Topological Sort
ver1 DFS
1 | code: |
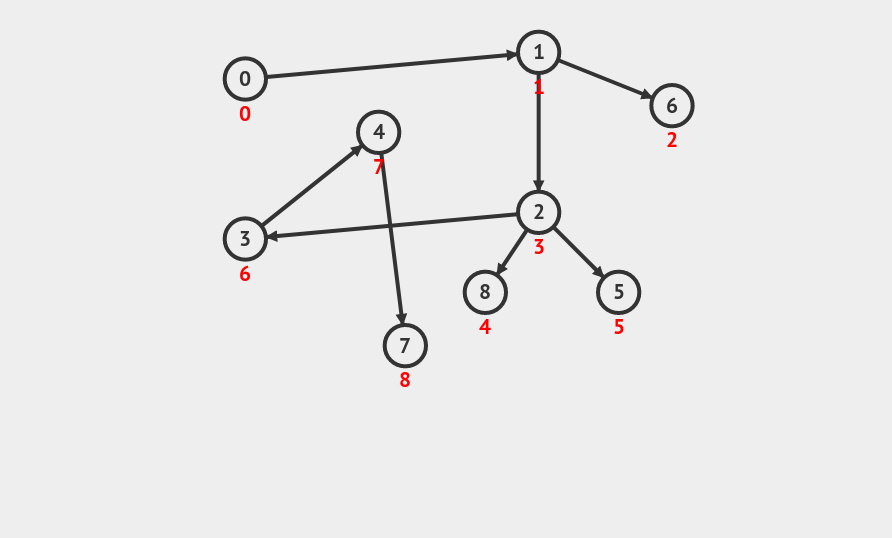
ver2 BFS (Khan)
1 | code: |
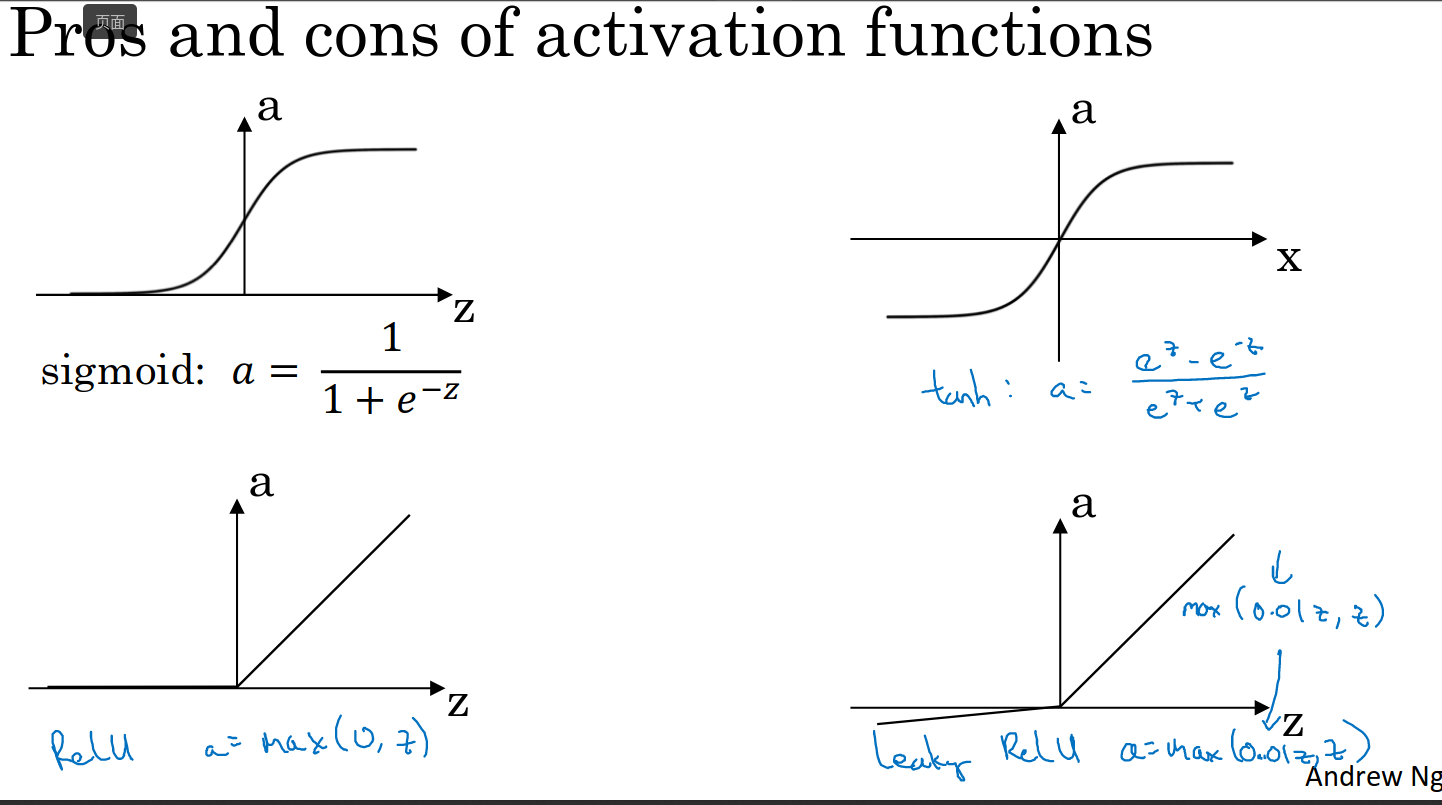
Bipartite
definition

1.说白了就是图的所有点可以分为两个set,每个set之间互相没有边,只有set与set之间的点有边。
2.应用于无向图。
Bipartite checker
ver1 DFS
每个点的邻居与它不同色(就是不同一个set)
每个点与它的邻居的邻居同色,它邻居的邻居与它在同一个set
1 | for each unvisited vertex in u: |
ver2 BFS
1 | push vertexs with no incoming edged to queue |
max flow
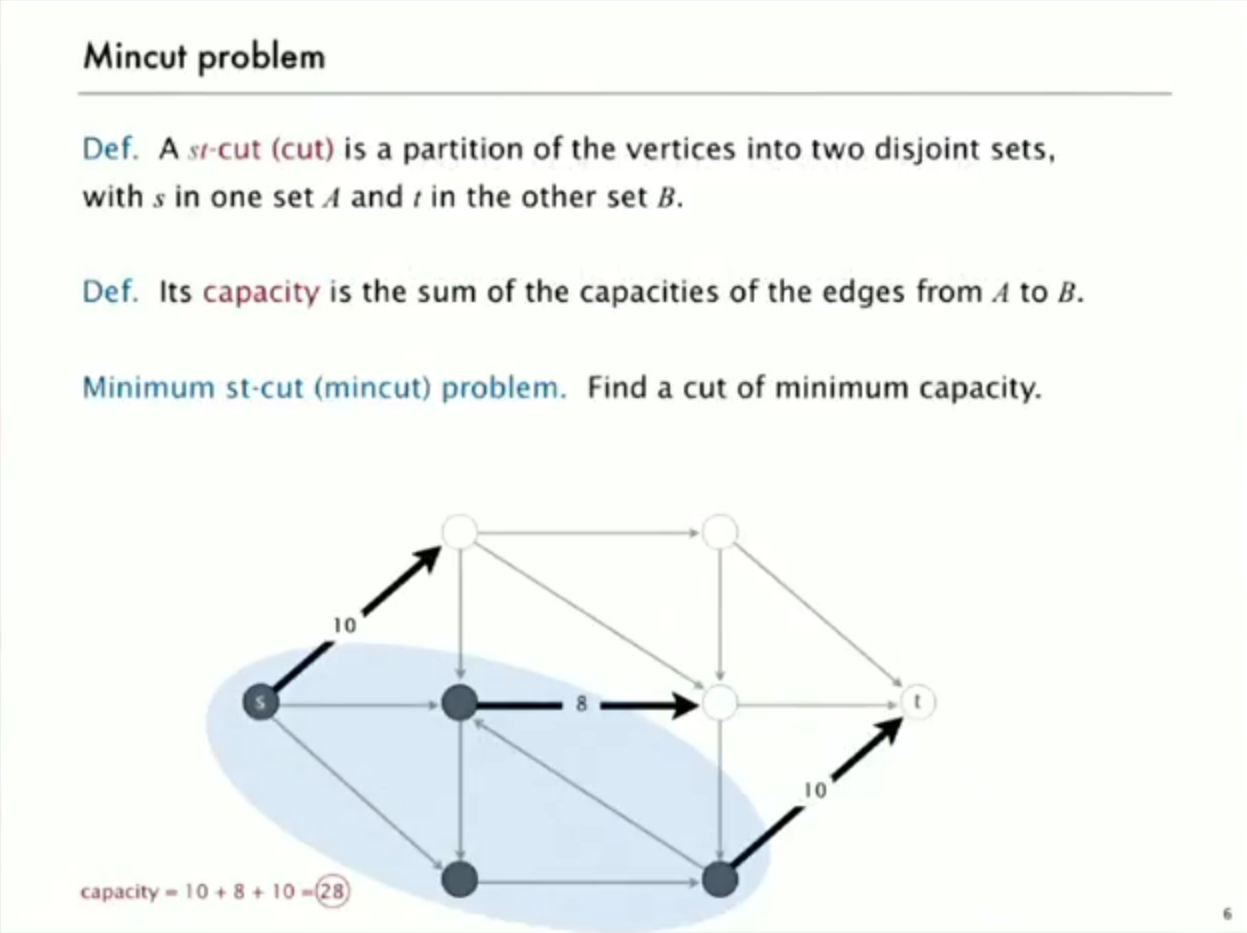
intro to mincut problem
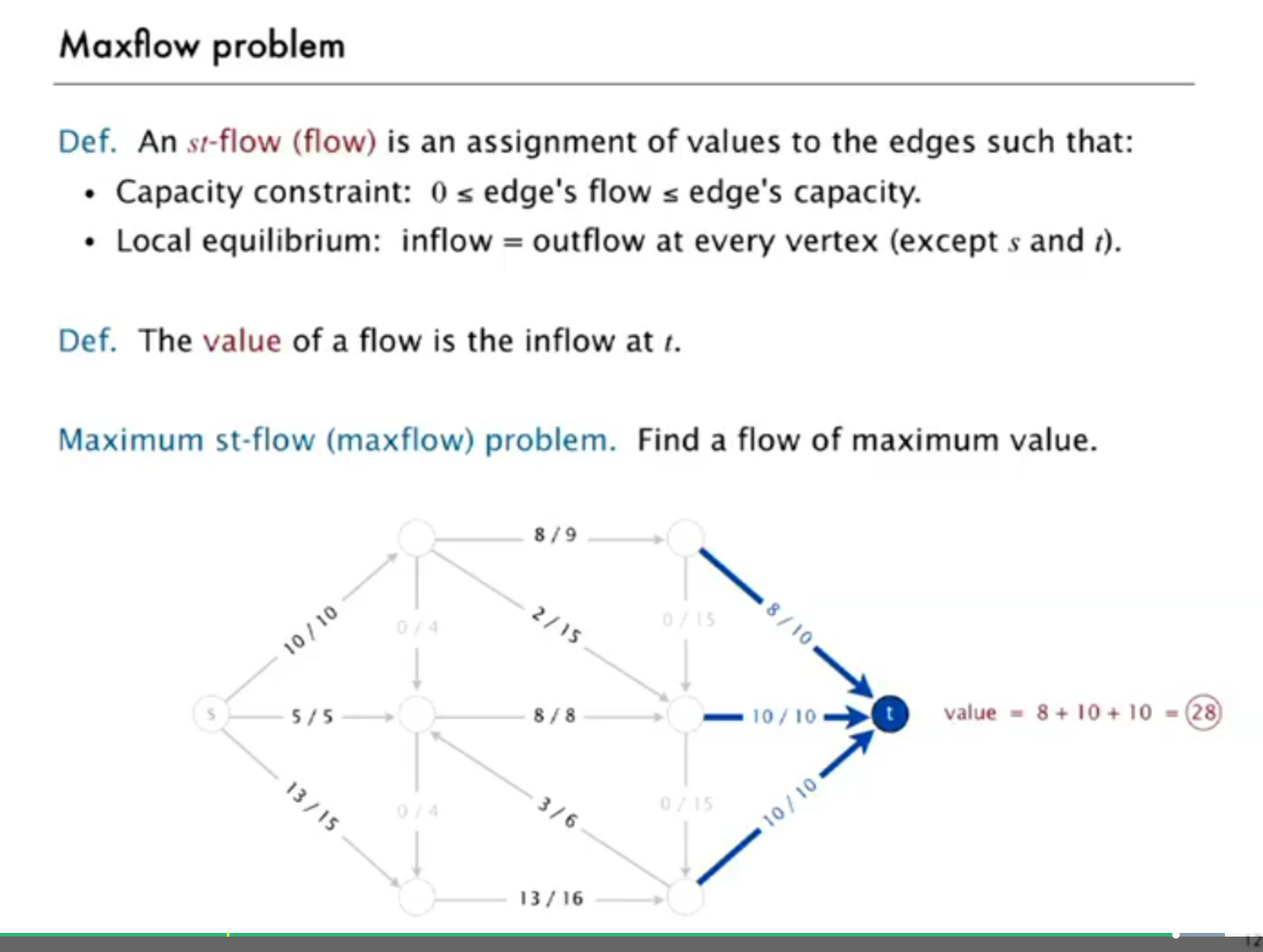
intro to maxflow problem
Ford-Fulkerson Algorithm
mincut 和 maxflow problem 实际上是等价的,解决了其中一个,另外一个就自然解决了。
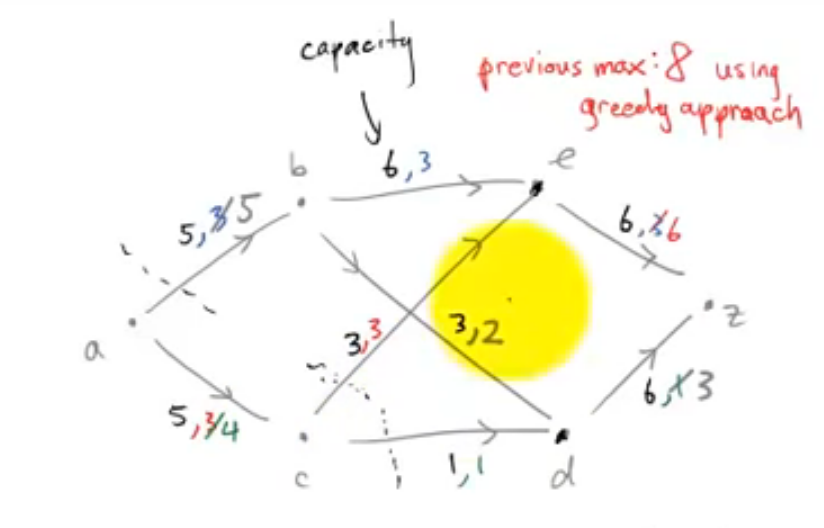
如上图,a为开始点。各边左数字为capacity,右边数字为flow
a->b满了,a->b有一个cut
a->c不满,即(flow<capacity)
c->e满了(flow==capacity)
c->d满了(flow==capacity)
设点a,c为集合P,其余所有点为集合P‘
则capacity of P->P’ 就等于maximum flow
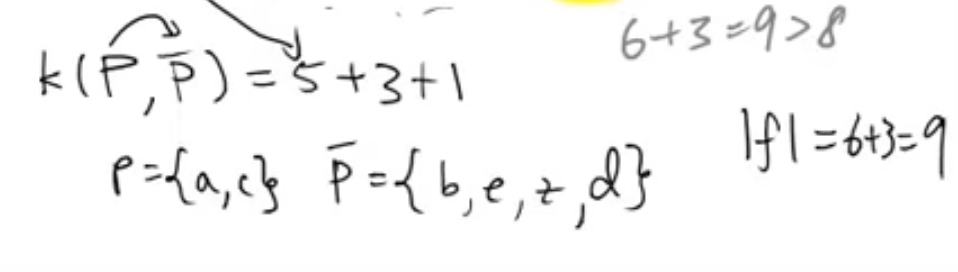
1 | Start with 0 flow |
Augmenting Path:
find an undirected path from s to t such that:
can increase flow on forward edges(not full.)
can decrease flow on backward edge(not empty.)
termination
all paths from s to t are blocked by either a:
full forward edge
empty backward edge
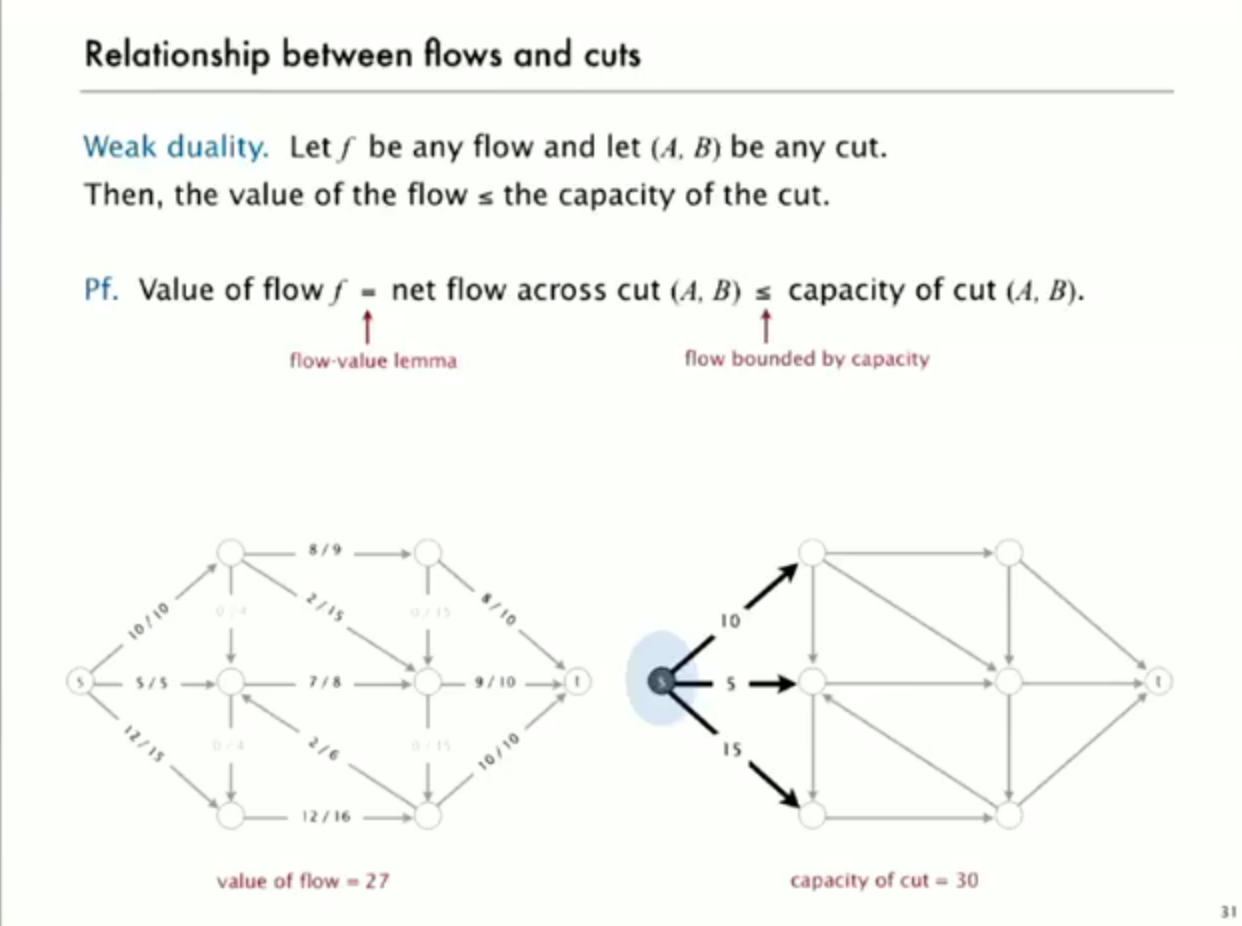
relationship between flow and cuts
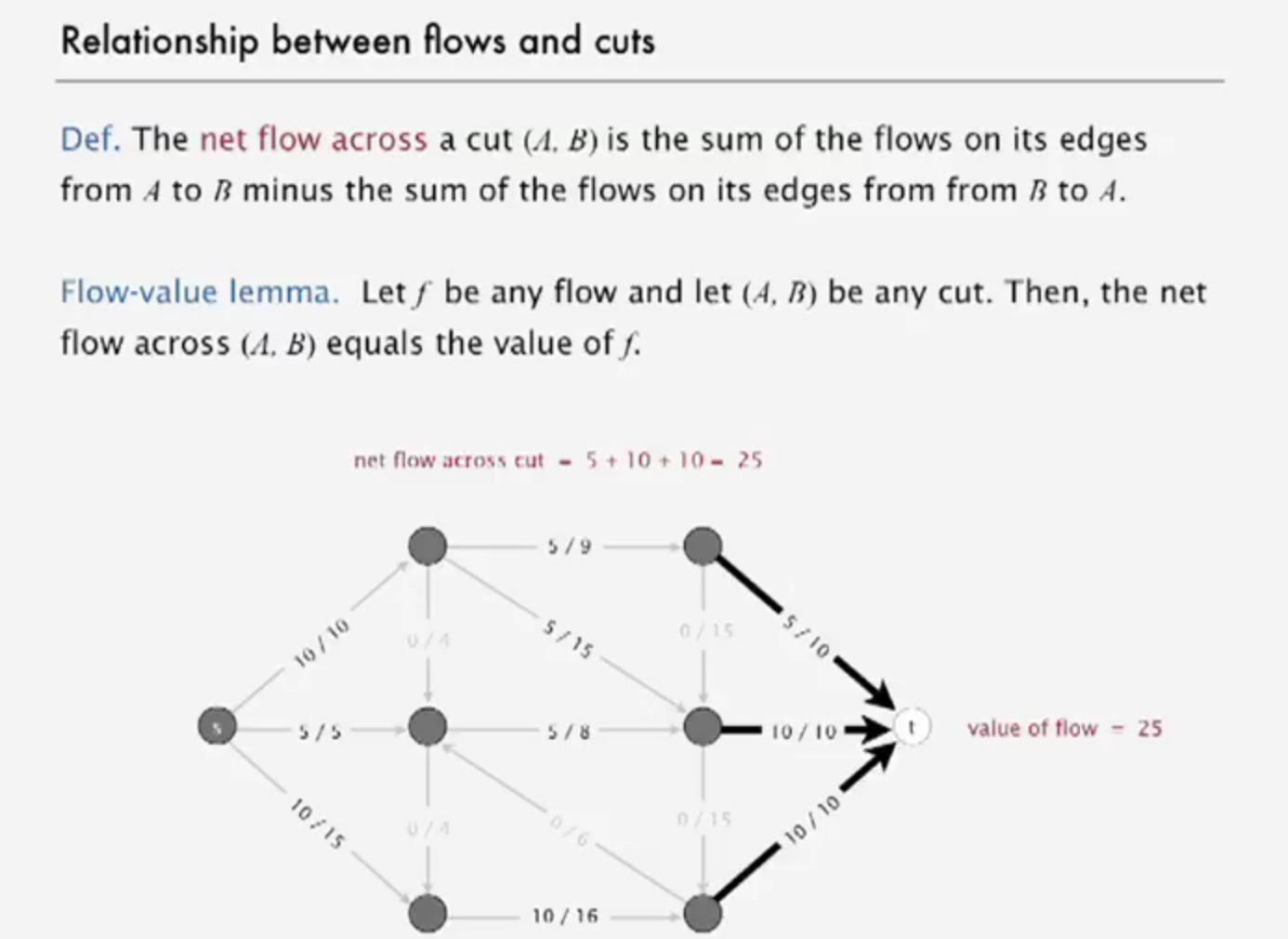
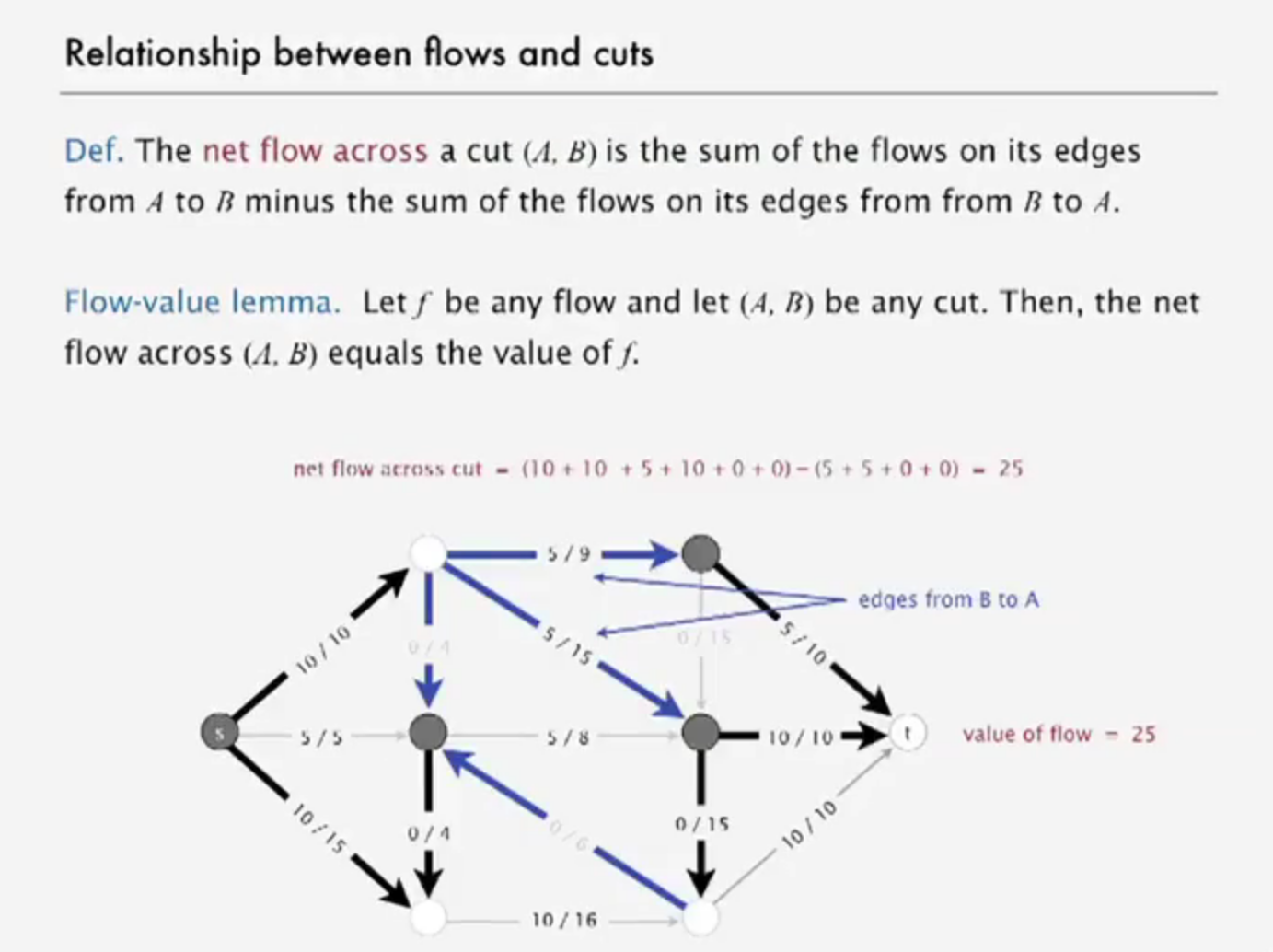
network of flow



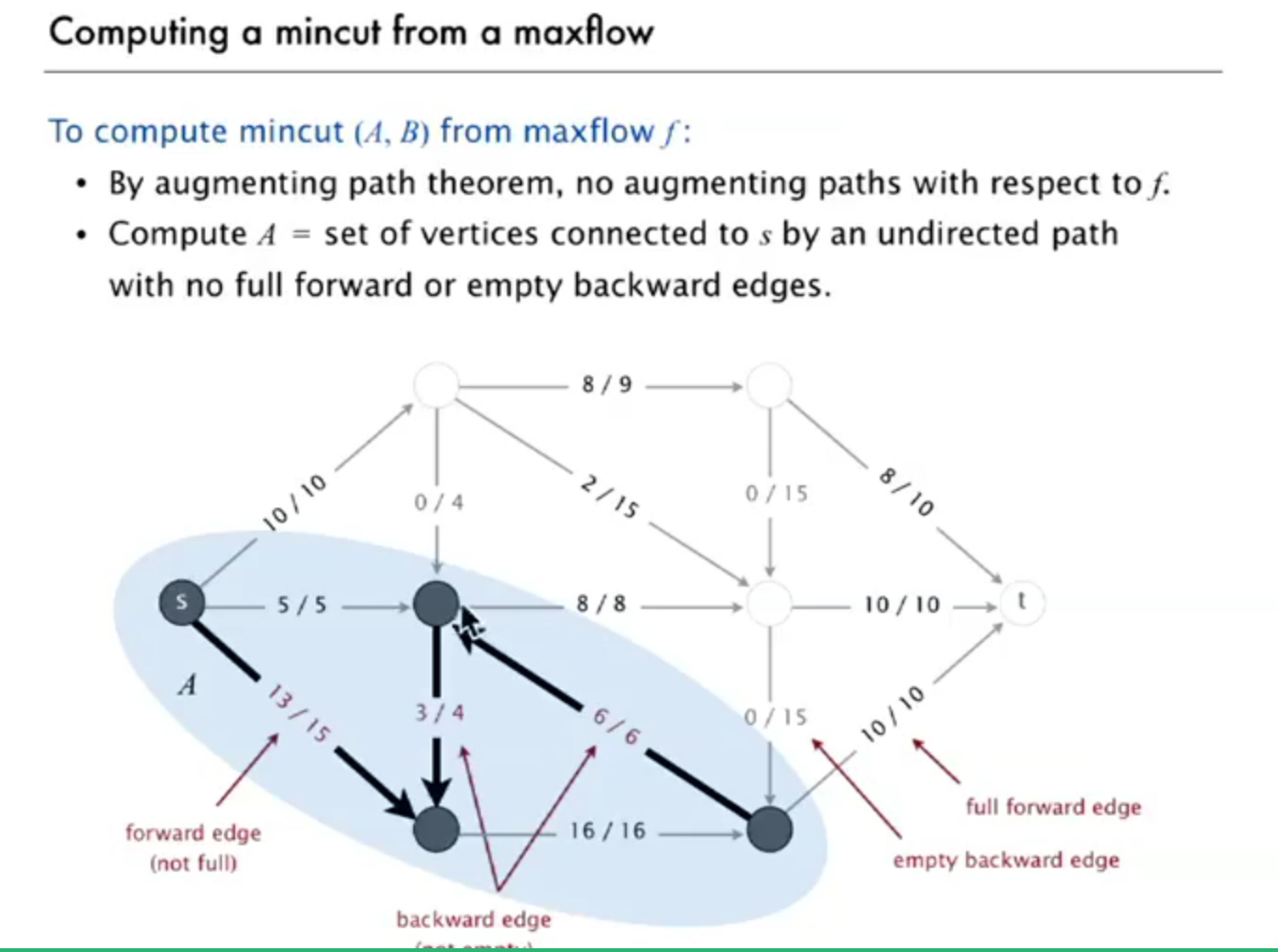
so how to find mincut from maxflow f?
start from s,find the forward edge that is not full or backward edge that is not empty

Ford-fulkerson算法
Ford-fulkerson算法就是: 不断在残留网络中找增广路,直到没有为止。
Time complexity : O(C*E) ,C 是容量和
1 | Time complexity of the above algorithm is O(max_flow * E). We run a loop while there is an augmenting path. In worst case, we may add 1 unit flow in every iteration. Therefore the time complexity becomes O(max_flow * E). |
Dinic 算法
Dinic: 每次寻找最短的增广路until找不到,可证明最多能找V次。
Time complexity : O(V^2E)
1 | 1) Initialize residual graph G as given graph. |
A flow is Blocking Flow if no more flow can be sent using level graph, i.e., no more s-t path exists such that path vertices have current levels 0, 1, 2… in order.
Dinic code-Kattis maximum flow
1 | #include <stdio.h> |