数据预处理
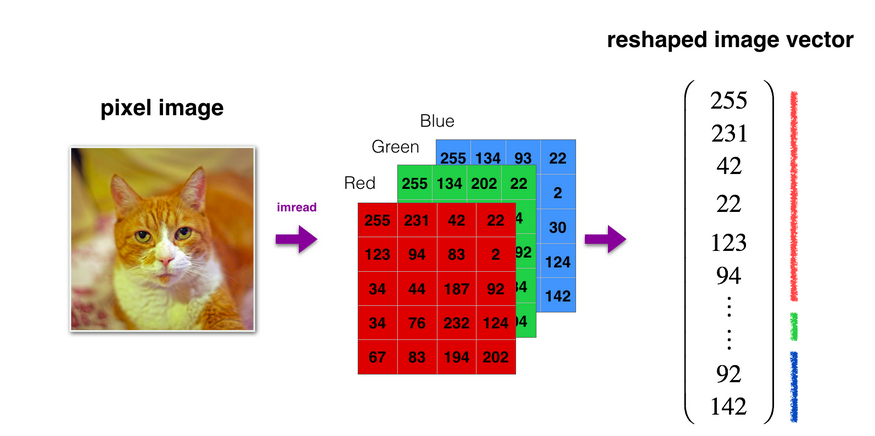
每一张图片都可以把它转化为一个m*1的向量
1 |
|
1 |
|
每一张图片都可以把它转化为一个m*1的向量
1 |
|
1 |
|

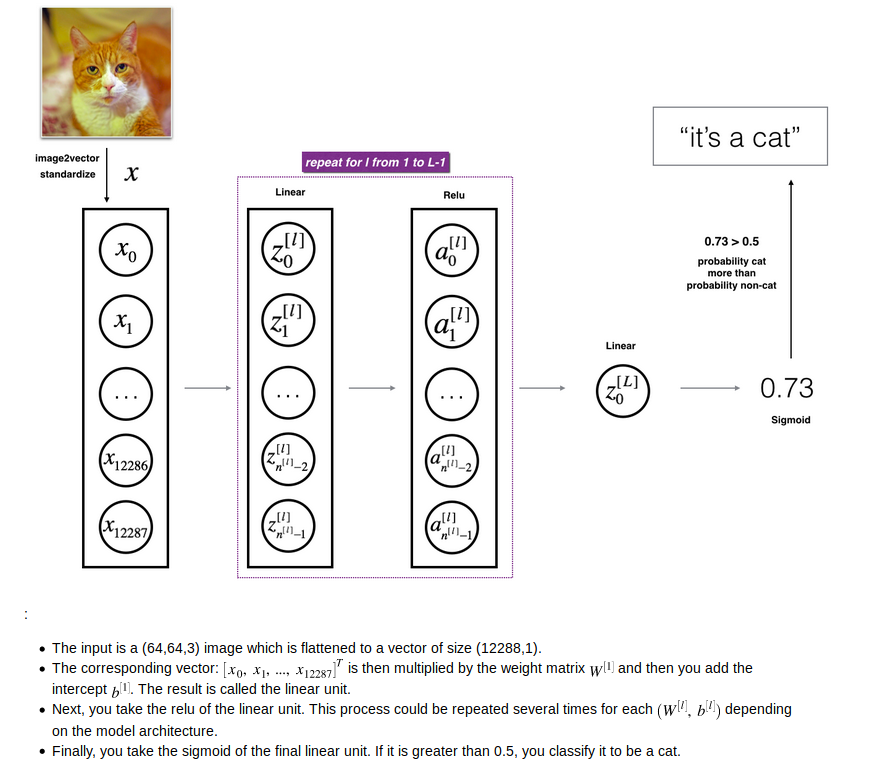
搭建深层的神经网络,各层W,X,B的维度一定要搞清楚
如上图所示,第i层W的维度为(n^[i],n^[i-1])
其中12288是特征数量,209是样本数,n^[i]是第i层神经元的数量。
1 |
|

实现Relu或者sigmoid激活函数
1 | def sigmoid(Z): |
以下是linear_activation_forward的函数
1 |
|
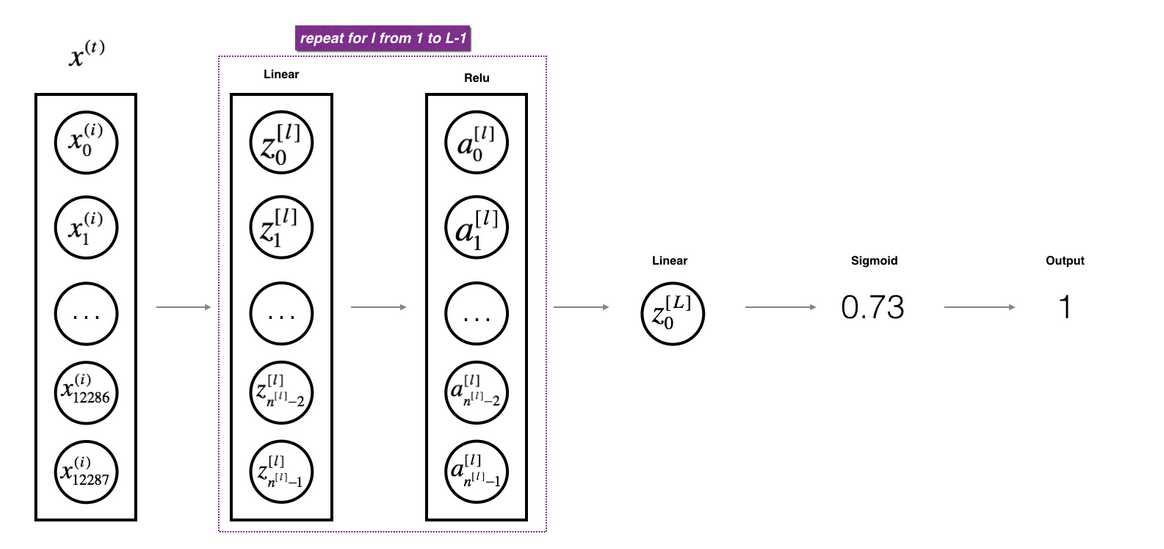
前L-1层作Relu变换,最后一层做sigmoid变换(由于是二分类)
1 |
|
在这里你得到的AL就是经过L曾训练后的parameters,可以用来测试结果,同时所有中间结果都保存在了caches中。
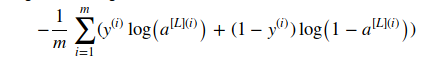
1 |
|
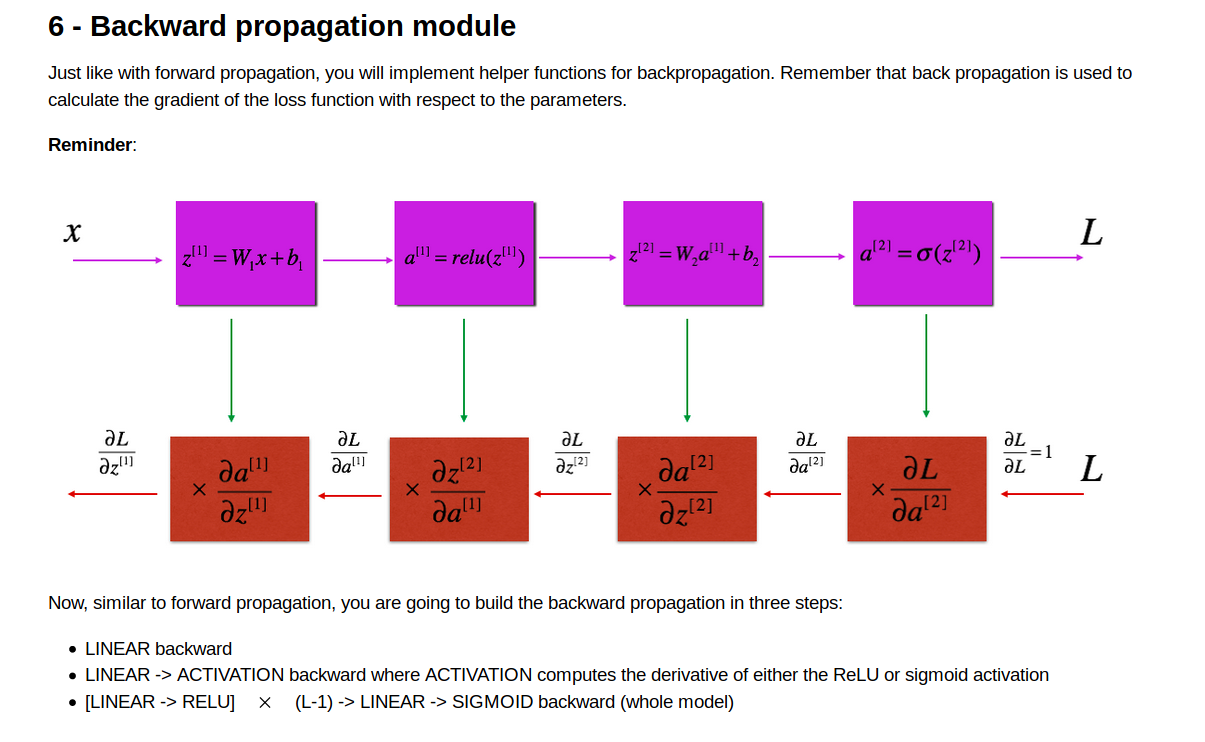
要通过计算dL/dz 来算出dw,dAprev,db 来进行梯度下降
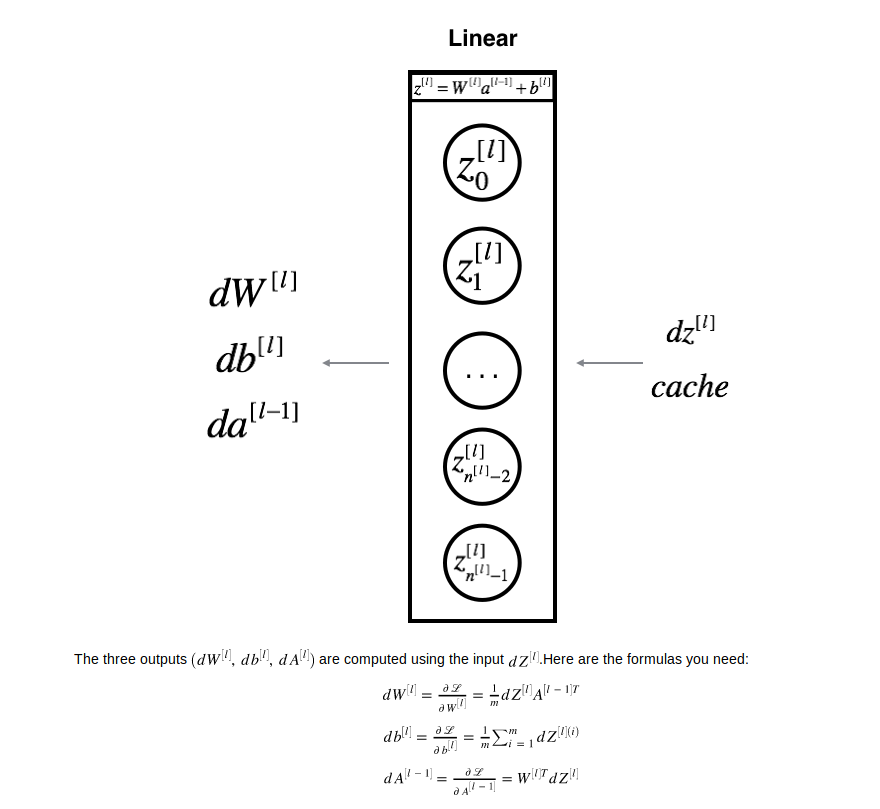
假设已知第l层的dZ,同时我们在做forward propagation的时候把对应该层的A_PREV,W已经存起来了
1 |
|
计算公式如上图所示
1 | def linear_backward(dZ, cache): |
那么上一个函数的dZ又是怎么计算?

我们运用最开始定义的两个辅助函数来计算
1 | def linear_activation_backward(dA, cache, activation): |
对最后一层是sigmoid_backward,剩下的所有层是linear_backward

1 | # GRADED FUNCTION: L_model_backward |
1 | def update_parameters(parameters, grads, learning_rate): |
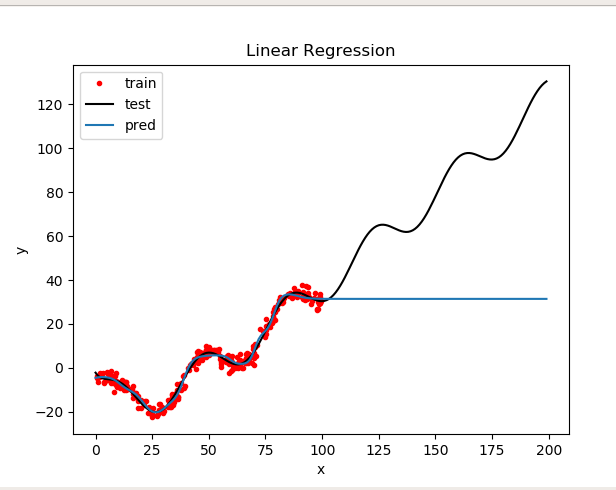
线性回归模型 y(x,w) = w0+w1x1+w2x2+…wDxD
而为了改进模型,把xi替换为非线性表达式

本实验使用了多项式基函数,高斯基函数和sigmoid基函数,以及混合型(多项式+sin正弦)而损失函数有两种选择,交叉熵函数以及均方误差,这里选择均方误差,求导比较方便。
y = w0+w1x1+w2x2^2 + b
λ2是L2正则化系数,可以解决过拟合问题
正则化意义:https://blog.csdn.net/jinping_shi/article/details/52433975

1 |
|
参数:n=2 epochs = 100000 lr 1e-7


1 | import numpy as np |
参数:f = gaussian.main(x_train, y_train,3,500000,1e-2,0)
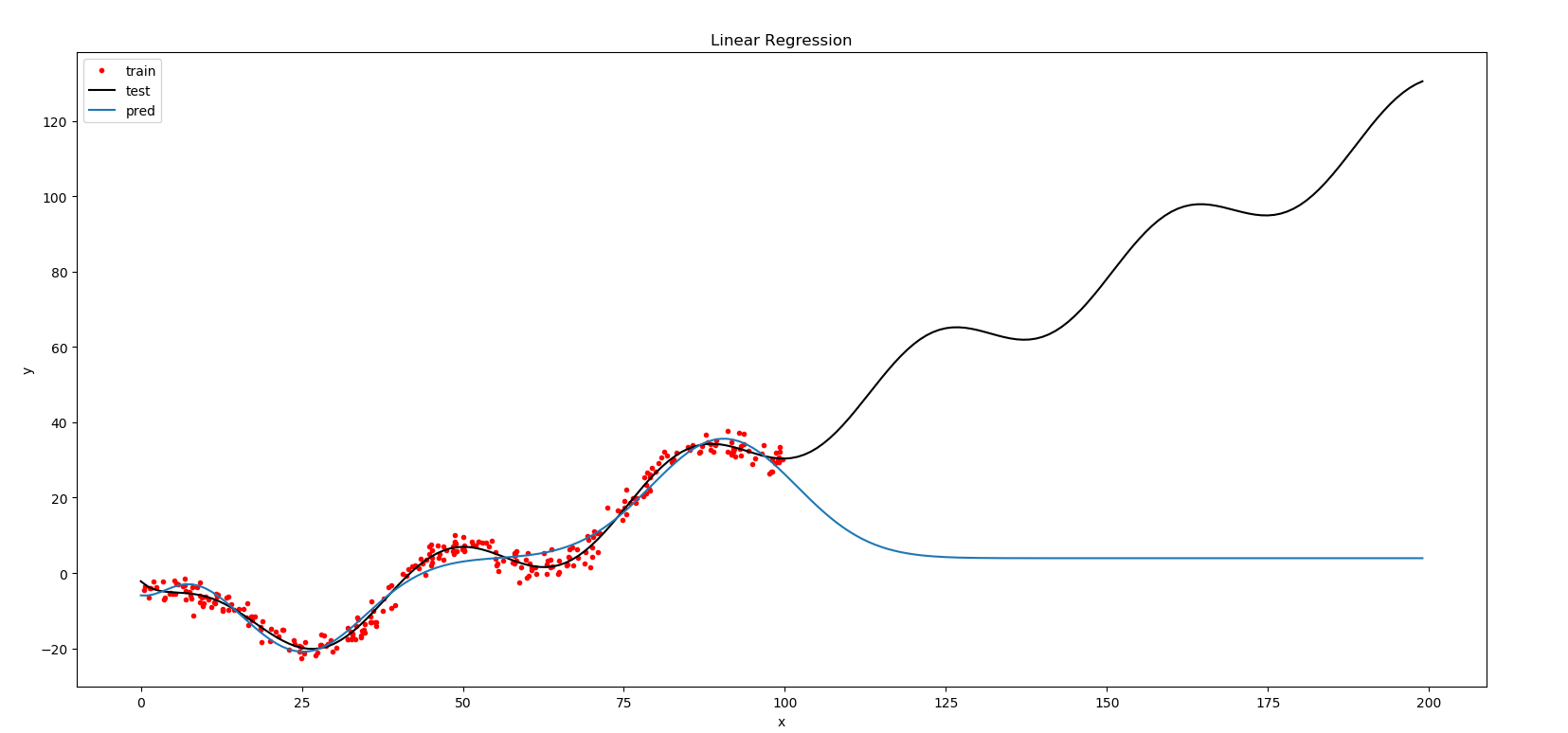

结果与高斯类似

1 | import numpy as np |
参数: f = sigmoid.main(x_train, y_train,10,100000,1e-2,0)
https://github.com/Haicang/PRML/blob/master/lab1/Report.ipynb
Ref:
https://blog.csdn.net/fuzhongmin05/article/details/54616344

code:
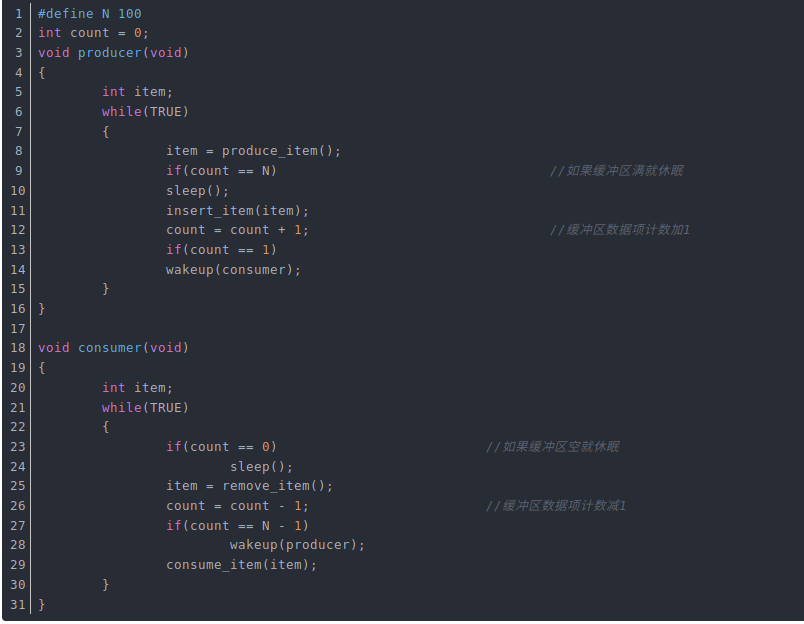
无法避免竞争
对count的访问没有做限制。
这里有可能出现竞争条件,其原因是对count的访问未作限制。有可能出现以下情况:缓冲区为空,消费者刚刚读取count的值发现它为0,此时调度程序决定暂停消费者并启动运行生产者。生产者向缓冲区加入一个数据项,count加1。现在count的值变成了1,它推断认为count刚才为0,所以消费者此时一定在睡眠,于是生产者调用wakeup来唤醒消费者。
但是消费者在逻辑上并未睡眠,所以wakeup信号丢失,当消费者下次运行时,它将测试先前读取的count值,发现它为0。于是睡眠,生产者迟早会填满整个缓冲区,然后睡眠,这样一来,两个进程将永远睡眠下去。
Dijkstra建议设立两种操作:down和up(分别为一般化后的sleep和wakeup)。对一信号量执行down操作,则是检查其值是否大于0。若该值大于0,则将其减1(即用掉一个保存的唤醒信号)并继续;若该值为0,则进程将睡眠,而且此时down操作并未结束。检查数值、修改变量值以及可能发生的睡眠操作均作为一个单一的、不可分割的原子操作完成。保证一旦一个信号量操作开始,则在该操作完成或阻塞之前,其他进程均不允许访问该信号量。这种原子性对于解决同步问题和避免竞争条件是绝对必要的。所谓原子操作,是指一组相关联的操作要么都不间断地执行,要么不执行。
up操作对信号量的值增1。如果一个或多个进程在该信号量上睡眠,无法完成一个先前的down操作,则由系统选择其中的一个(如随机挑选)并允许该进程完成它的down操作。于是,对一个有进程在其上睡眠的信号量执行一次up操作后,该信号量的值仍旧是0,但在其上睡眠的进程却少了一个。信号量的值增加1和唤醒一个进程同样也是不可分割的,不会有某个进程因执行up而阻塞,正如前面的模型中不会有进程因执行wakeup而阻塞一样。
在Dijkstra原来的论文中,他分别使用名称P和V而不是down和up,荷兰语中,Proberen的意思是尝试,Verhogen的含义是增加或升高。
从物理上说明信号量的P、V操作的含义。 P(S)表示申请一个资源,S.value>0表示有资源可用,其值为资源的数目;S.value=0表示无资源可用;S.value<0, 则|S.value|表示S等待队列中的进程个数。V(S)表示释放一个资源,信号量的初值应该大于等于0。P操作相当于“等待一个信号”,而V操作相当于“发送一个信号”,在实现同步过程中,V操作相当于发送一个信号说合作者已经完成了某项任务,在实现互斥过程中,V操作相当于发送一个信号说临界资源可用了。实际上,在实现互斥时,P、V操作相当于申请资源和释放资源。
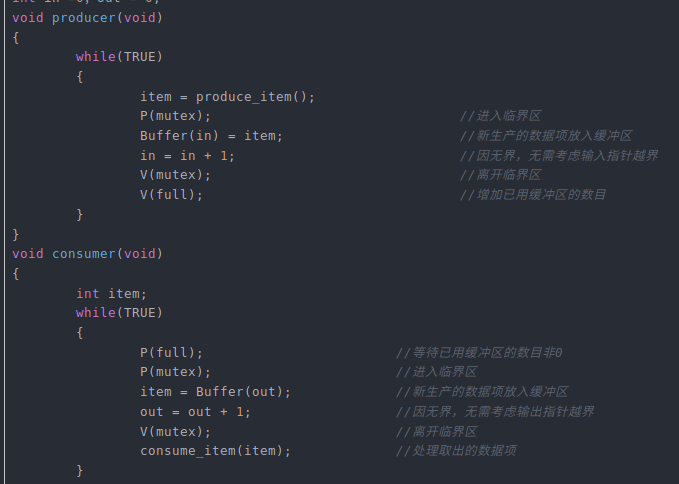
该解决方案使用了三个信号量:一个称为full,用来记录充满缓冲槽数目,一个称为empty,记录空的缓冲槽总数;一个称为mutex,用来确保生产者和消费者不会同时访问缓冲区。full的初值为0,empty的初值为缓冲区中槽的数目,mutex的初值为1。供两个或多个进程使用的信号量,其初值为1,保证同时只有一个进程可以进入临界区,称作二元信号量。如果每个进程在进入临界区前都执行down操作,并在刚刚退出时执行一个up操作,就能够实现互斥。
在下面的例子中,我们实际上是通过两种不同的方式来使用信号量,两者之间的区别是很重要的,信号量mutex用于互斥,它用于保证任一时刻只有一个进程读写缓冲区和相关的变量。互斥是避免混乱所必需的操作。
例题:

items 就是full,记录满槽数目,初始值位0
slots 就是empty,就是缓冲区中槽的数目,初始值为10
mutex inital value = 0
那么insert function
1 |
|
remove function
1 | P(items); //满槽数目-1 |
本例中,信号量保证缓冲区满的时候生产者停止运行,缓冲区空的时候消费者停止运行。
一个进程执行某个请求,如果需要一段时间才能返回信息,那么进程会一直等待下去。也就是说直到收到返回信息才继续下去。
进程不需要一直等待下去,继续执行下面的操作,不管其他进程的状态。
对于无界缓冲区问题,消费者只需关心缓冲区是否空即可
 。
。
我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
3、问题及危害
unix提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放。 但这样就导致了问题,如果进程不调用wait / waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个 子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时 处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。 如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。

b

C。读写锁只能同时由多个读者或者一个写者拥有,而且读和写是排他的,两者不能共存。

页大小大概占10位,那么虚拟地址分为虚拟页号和虚拟页偏移量,那么后10位就是偏移量,剩下的位就是索引位,对应在页表中的索引,那么所以说他们的索引一样,物理位置的物理页号一样,而物理偏移量A总是小于B
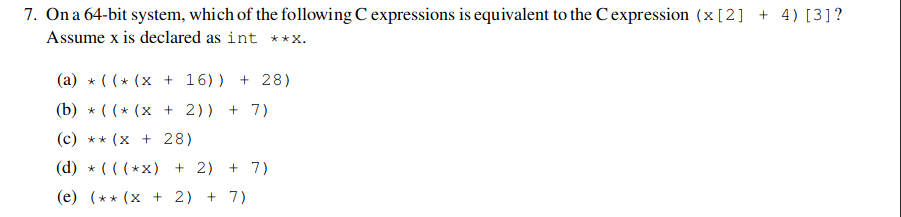
*(x+2) = A[2];

b

d
Size of a pointer should be 8 byte on any 64-bit C/C++ compiler, but not necessarily size of int.
1 | int a = 3; //静态变量,外部链接性 |
外部链接性: 多个文件共享
内部链接性: 只有所属的文件可用
无连接性: 只有该代码段内可用
外部链接性的静态变量

1 | int a = 2; |

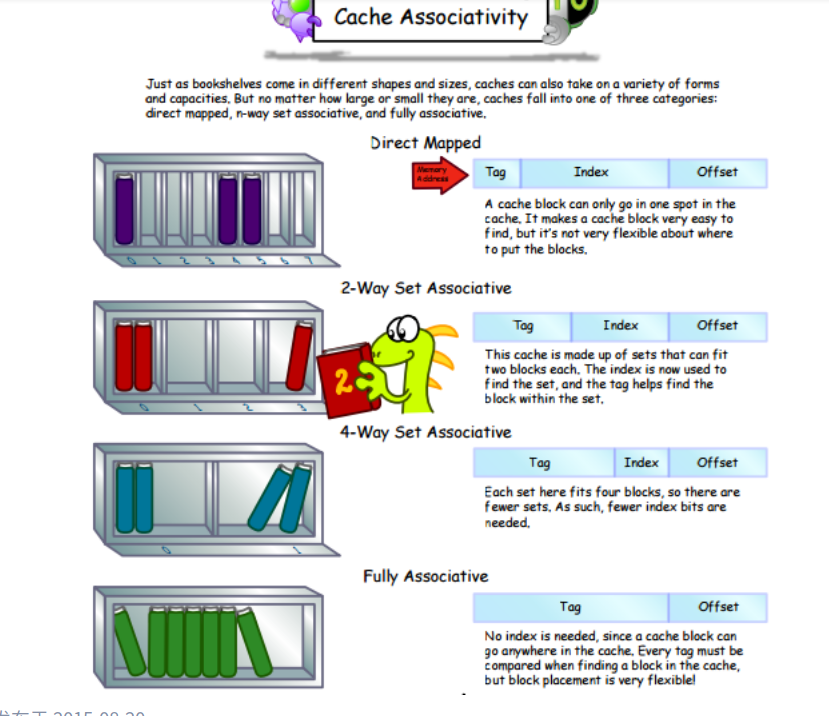
cache共有两个block,分别位于两个set中,设他们为b1和b2。每个block可以放下4个int类型的变量,也就是数组中的一行。在这一题中,源数组和目的数组是相邻排列的。所以内存和cache的映射情况是这样的:
b1 : src[0][] src[2][] dst[0][] dst[2][]
b2 : src[1][] src[3][] dst[1][] dst[3][]

这里搞错了,应该是dst数组全是m,src数组是左边的样子。

a

An object that is “8 bytes aligned” is stored at a memory address that is a multiple of 8.
so choose c
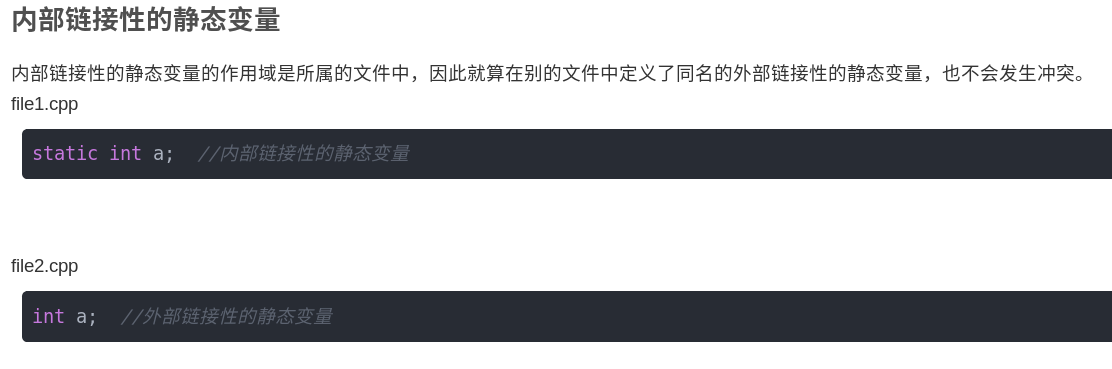
line就是block
directed mapped 就是一个set只有一个line
2way就是一个set可以放2个line
4way,就是一个set可以放4个line
fully associated 就是只有一个set,所以不需要中间位的index,来作为line index
空间局部性。
“子进程是父进程的副本。例如,子进程获得父进程数据空间、堆和栈的副本。注意,这是子进程所拥有的副本。父进程和子进程并不共享这些存储空间部分。父进程和子进程共享正文段。”


子进程得到的只是全局变量的副本,该题应该选b
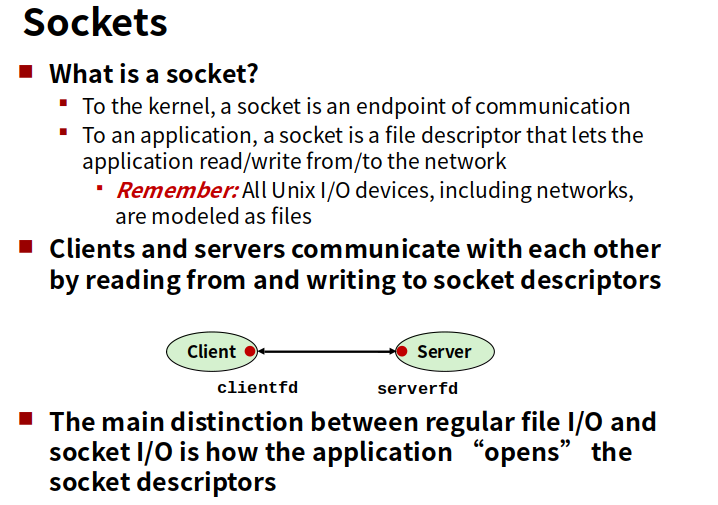
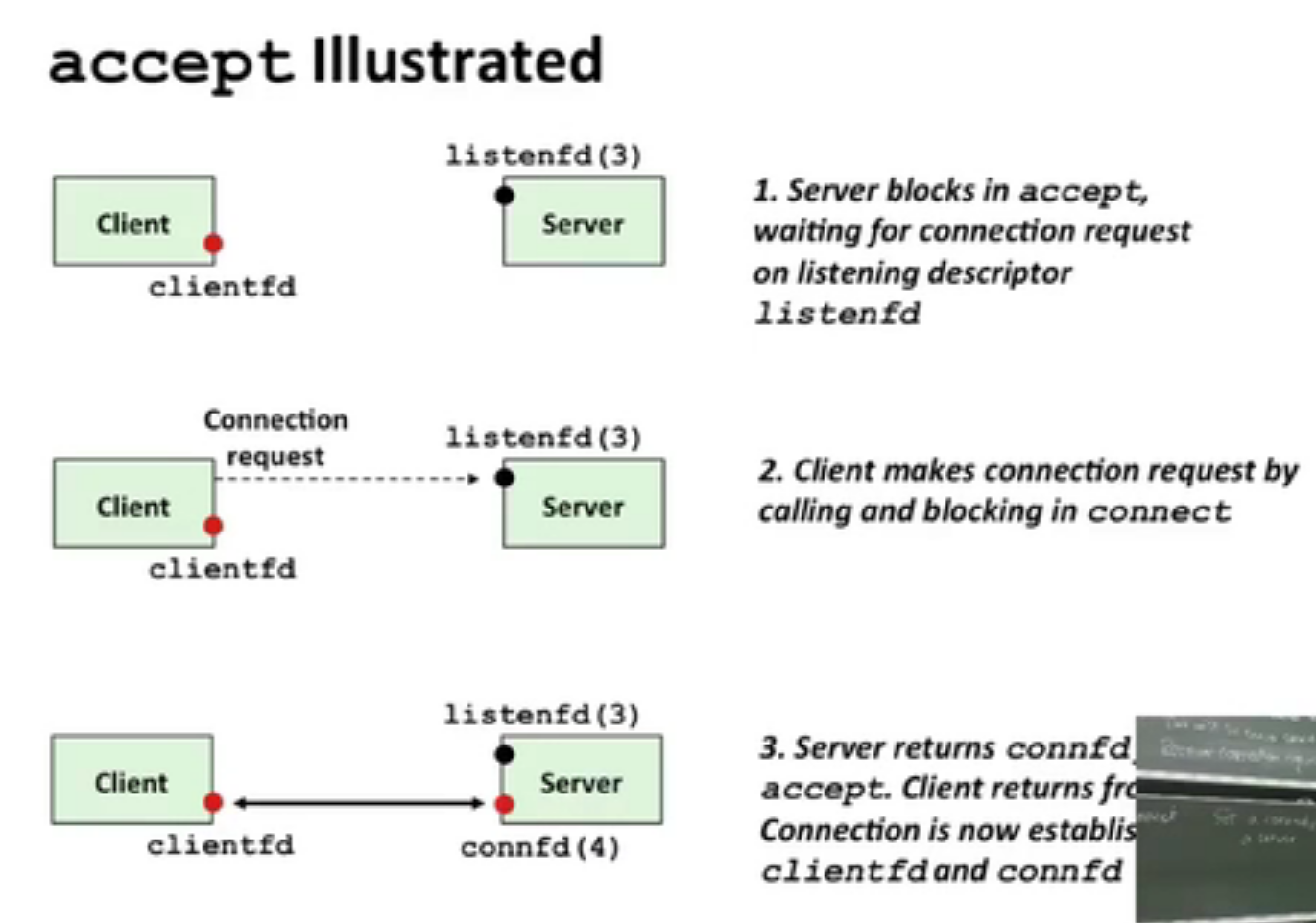
先搞清listen socket 和 connected socket 的区别。
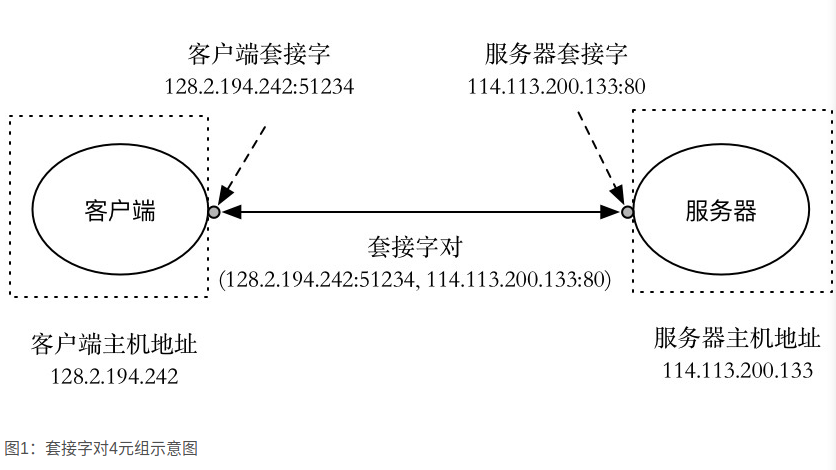
一个套接字对标记着一个客户端和服务器的链接。
客户端是发起连接请求的主动实体,而内核会认为socket函数创建的套接字是主动套接字,而服务器就是要调用listen函数告诉内核,该套接字是被服务器而不是客户端使用的,即listen函数将一个主动套接字转化为监听套接字。
服务器通过accept函数等待来自客户端的连接请求到达监听套接字,并返回一个已连接套接字,这个connfd可以被用来与客户端进行通讯。
实验过程如下:
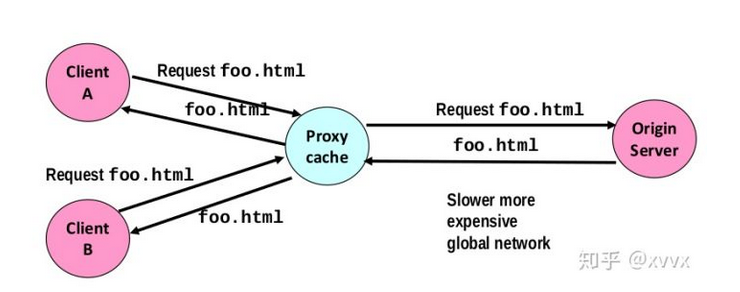
1 | /* You won't lose style points for including this long line in your code */ |
main 函数,参考课本的tiny服务器,注意的是这里pthread_create是传值而不是引用,是为了避免竞争。(传值是传一个独立的副本)
1 | int main(int argc,char **argv) |
1 | void *thread(void *vargp){ |
函数逻辑:
1.得到解析后的请求行和请求头
2.然后去连接对应的服务器,发送请求
3.建立连接后,返回信息会在描述符中,也就是endServerFd
4.再把信息从endServerFd中读取出来,直接写进客户端对应的描述符fd就可以。
1 |
|
1 | void buildHTTPHeader(char *http_header,char *hostname,char *path,int port,rio_t *client_rio){ |
1 |
|
1 | inline int connectEndServer(char *hostname,int port){ |
采用读者-写者模型,可以让多个线程同时来读。
没有实现LRU,只是简单地把1MiB内存分为十块,每次接受请求并解析之后,先去cache看看有没有对应的web object,如果有直接返回给客户端,没有再从服务端请求。
1 |
|
use ./free-port.sh to get a free port, like 4501
open a terminal, nc -l 4501
open a terminal
1 | curl -v --proxy http://localhost:23885/ http://localhost:4501/ |
./proxy 23885
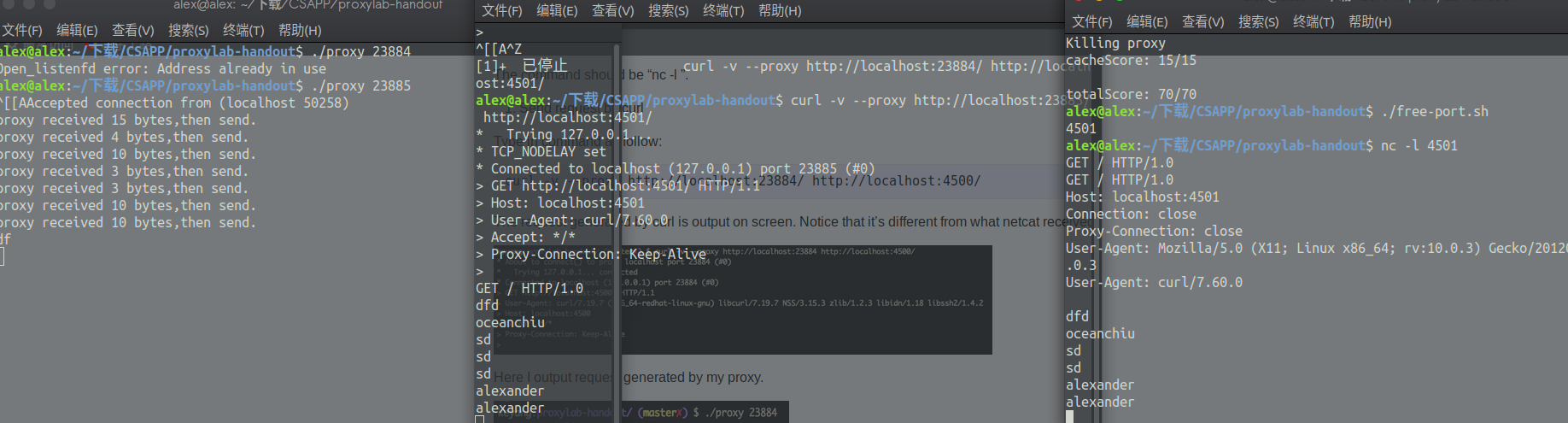
netcat is listening on 4501,proxy is listening on 23885,here netcat serves as a server,print sth in the ‘nc -l’ window,then you can see the exact sth print on the ‘curl’ window
现代操作系统提供三种构造并发程序的方法:
1.进程
2.I/O多路复用
3.线程
1.内核自动管理多个逻辑流
2.每个进程有私有的地址空间(进程切换的时候要保存和载入数据)
1 | void sigchld_handler(int sig){ |
服务器在accept函数中等待连接请求,然后客户端通过调用connect函数发送连接请求,最后服务器在accept中返回connfd并且fork一个子进程来处理客户端链接,链接就建立在listenfd和connfd之间。
每个客户端由独立的子进程处理,而且必须回收僵尸进程,避免内存泄漏
不同进程之间不共享数据
父进程和子进程都有listenfd和connfd,所以父进程中要关闭connfd,子进程要关闭listenfd
优点:只共享已打开的file table,无论是descriptor还是全局变量都不共享,不容易造成同步问题。
缺点:带来额外的进程管理开销,进程间通信需要用IPC
1.由程序员手动控制多个逻辑流。
2.所有逻辑流共享同一个地址空间
内核自动管理多个逻辑流
每个线程共享地址空间
属于基于进程和基于事件的混合体
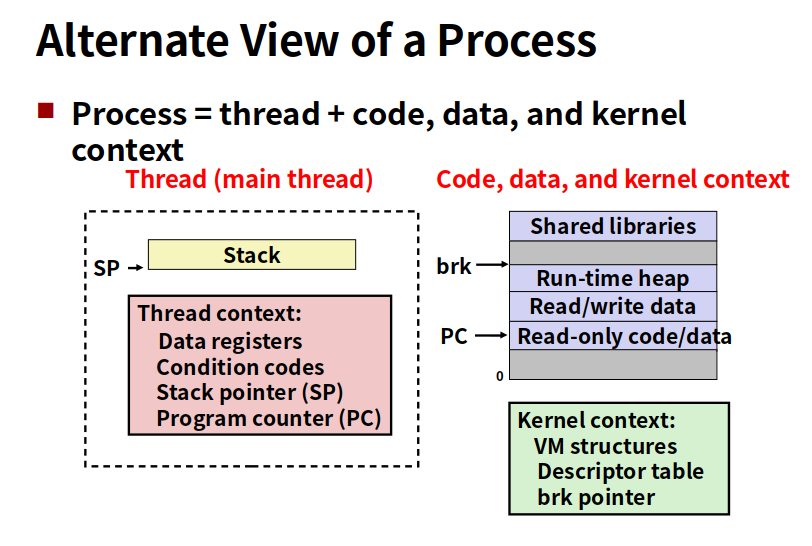
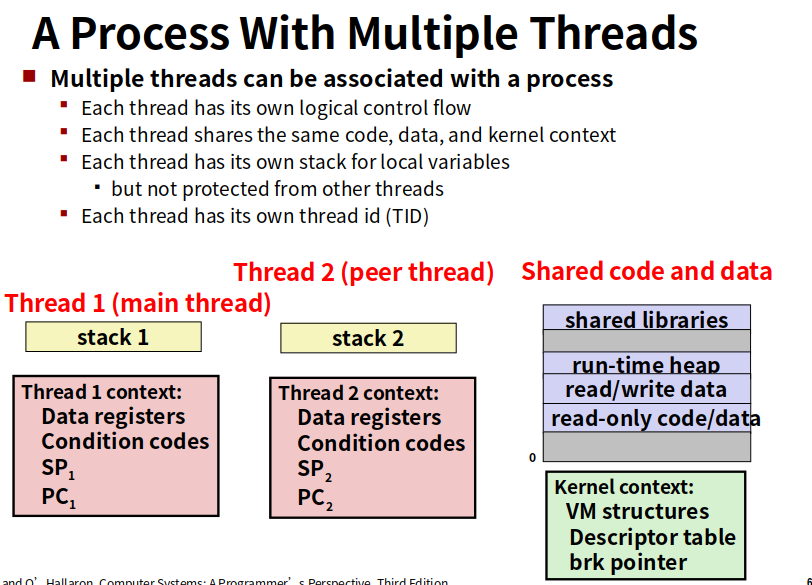
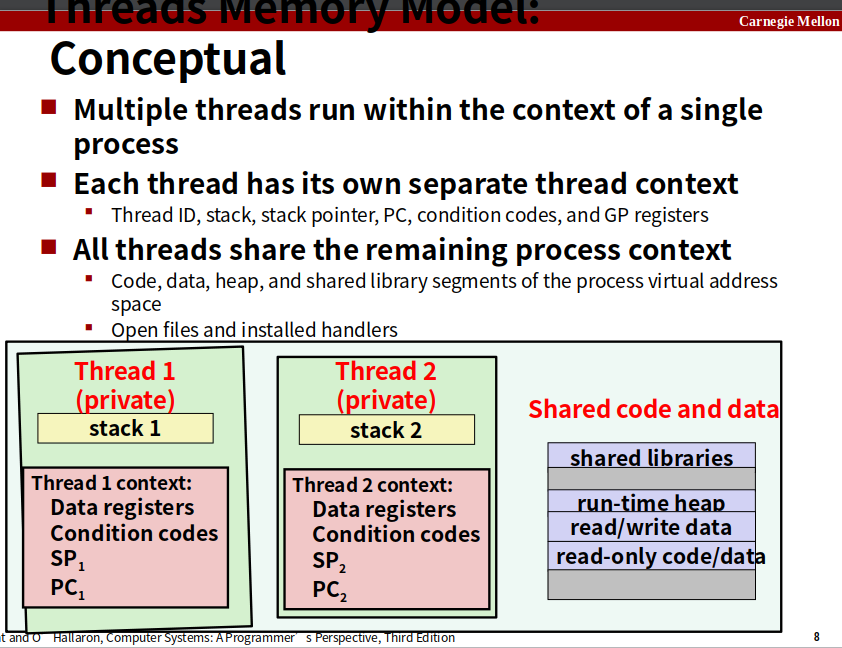
一个进程有多个线程,每个线程有自己的线程id,有自己的逻辑控制流,也有自己用来保存局部变量的栈(其他线程可以修改)。而且共享所有代码,数据和内核上下文。
概念上的
实际上的
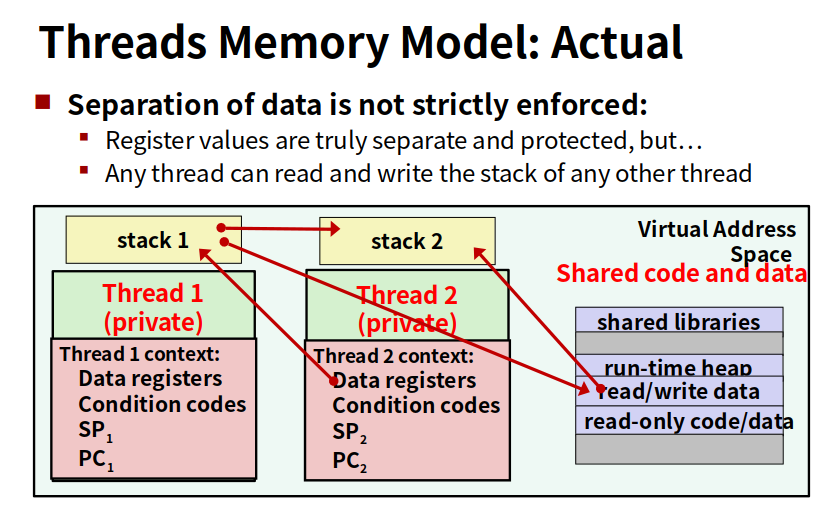
不同线程之间的数据其实可以相互访问
a variable x is shared if and only if multiple threads reference some instance of x


ptr是全局变量,shared by main thread and thread 1&2
i is only referenced by main, so not shared
msgs is referenced by all 3 threads, so is is shared
myid is only referenced by thread 1 & 2 seperately
static int cnt is referenced by both 1 &2
so if multiple threads reference the same x instance, the x is shared


看loop的汇编代码

正常结果
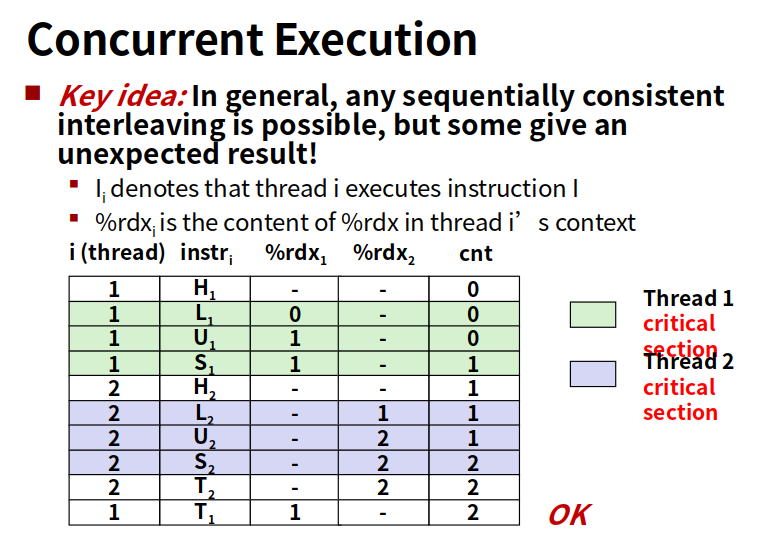
下图是线程2提前Load了cnt,结果rdx2为0,正确结果是等到线程1store之后线程2再load
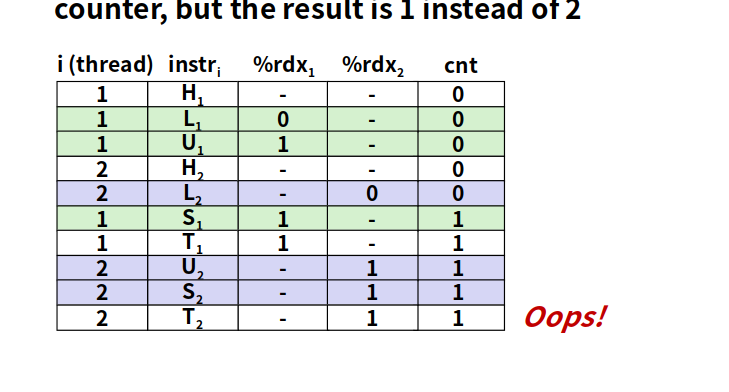
volatile的本意是“易变的” 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用valatile,则编译器将对所声明的语句进行优化。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)

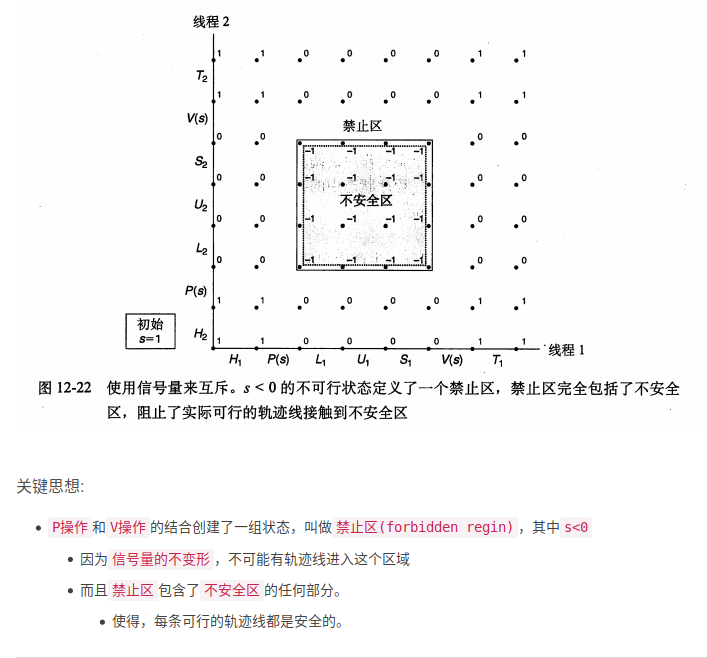
信号量的提出,是为了解决同步不同执行线程问题的方法。
什么是信号量?
信号量s是一个具有非负值的全局变量。
只能由两种特殊操作P,V来处理
P,V原理如上图

定义P和V,为了确保一个正在运行的程序绝不可能进入s是负值的状态,这个属性叫信号量不变性

1 |
|




一个函数如果被多个并发线程反复调用的时候,会一直产生正确的结果,否则就是线程不安全的。
1.不保护共享变量的函数
解决方案,利用P,V这样的同步操作来保护共享的变量
2.保持跨越多个调用状态的函数

3.返回指向静态变量的指针的函数

4.调用线程不安全函数的函数。
1.如果函数f调用线程不安全函数g。那么f可能不安全。
2.如果g是第二类,那么f一定不安全,也没有办法去修正,只能改变g.
3.如果g是第一,三类,可以用加锁-拷贝技术来解决。
当一个程序的正确性依赖于一个线程要在另一个线程到达y点之前到达它的控制流中的x点,就会发生竞争。
1.通常,竞争发生的理由是因为程序员假定某种特殊的轨迹线穿过执行状态空间。



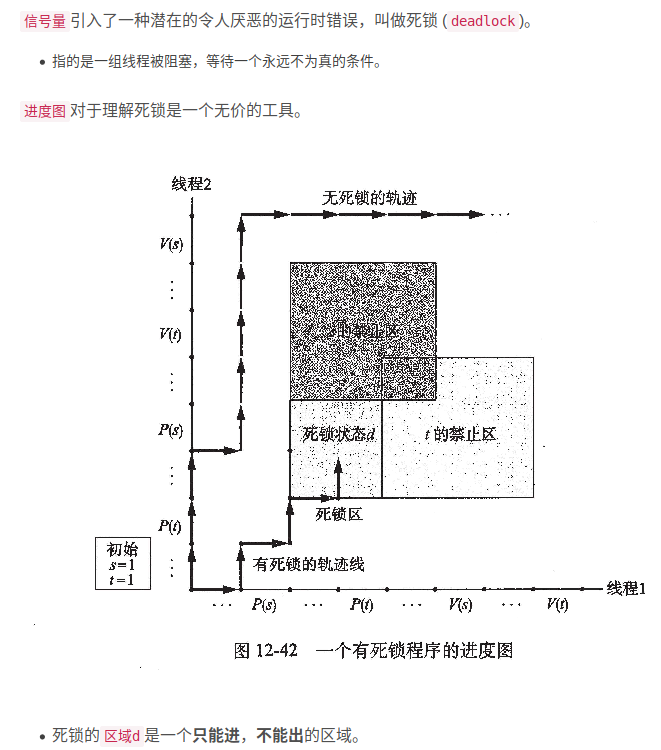
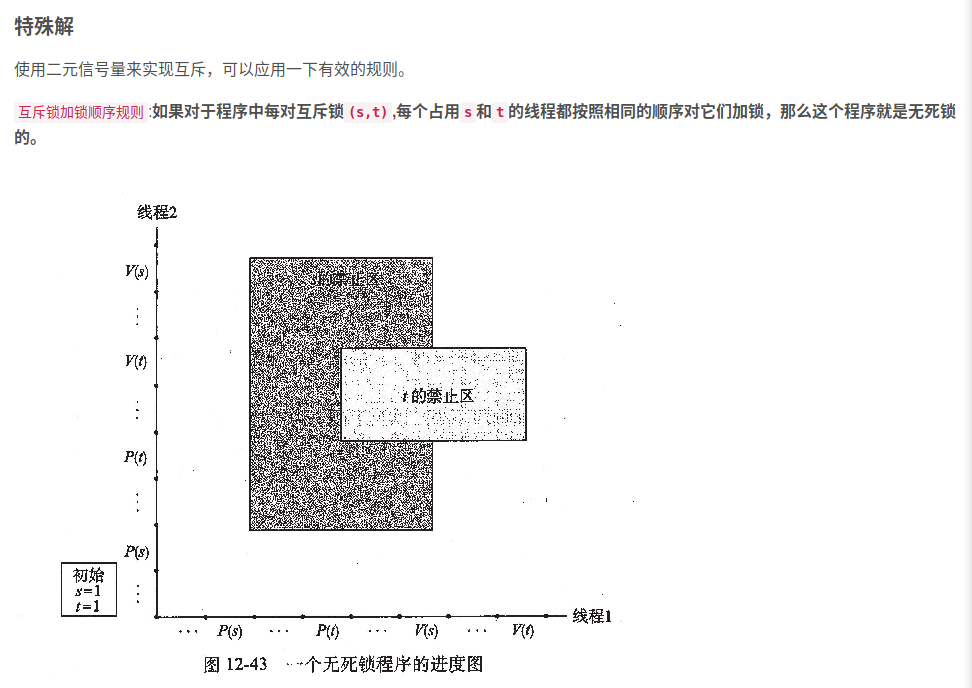
判断 myid会不会出现竞争
1 | // 版本一 |
循环中每次创建不同的指针,两个线程不是共享同一个变量。
1 | // 版本二 |
两个线程共享i变量,而i++和myid = ((int )vargp)
会发生竞争,当然前提是传的是引用&i,因为这样的话foo函数会改变i本身的值,若如果是传值i,则只会改变i的一个副本。
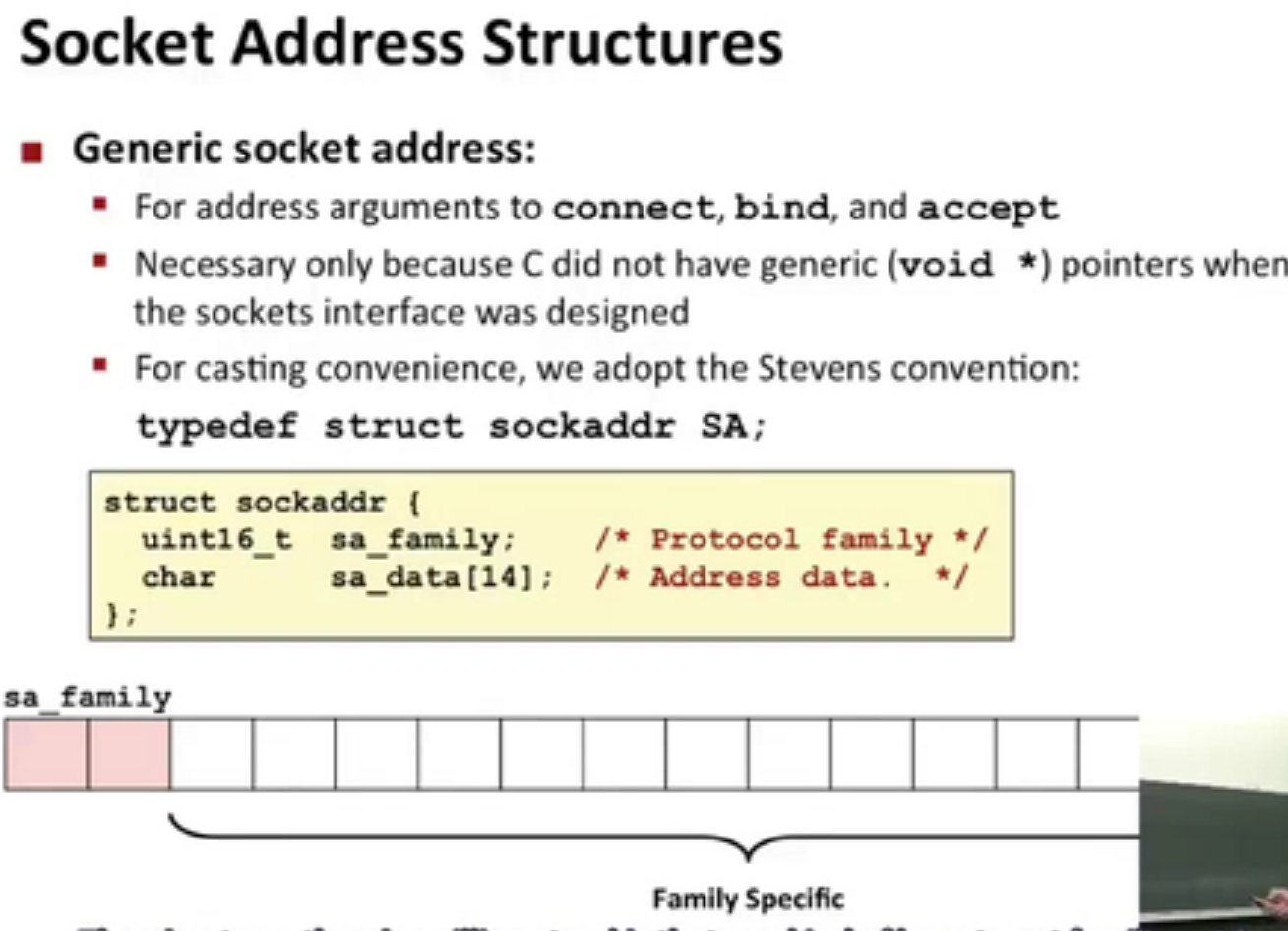
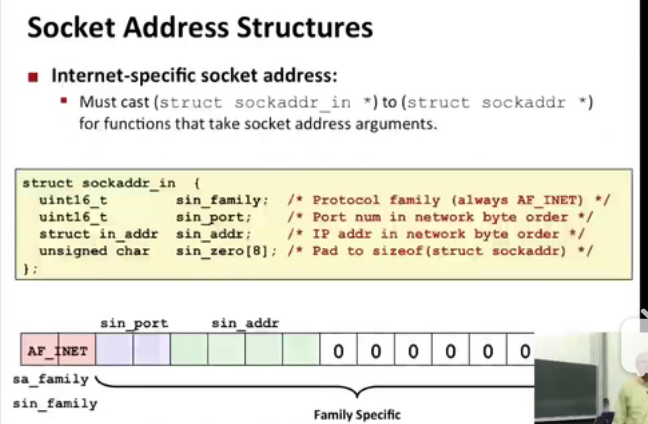
发明套接字接口的时候,还没有void*,为了兼容,可以定义套接字函数要求一个指向通用sockaddr结构的指针,然后要求应用程序将与协议特定的结构的指针强制转换成这个通用的结构。
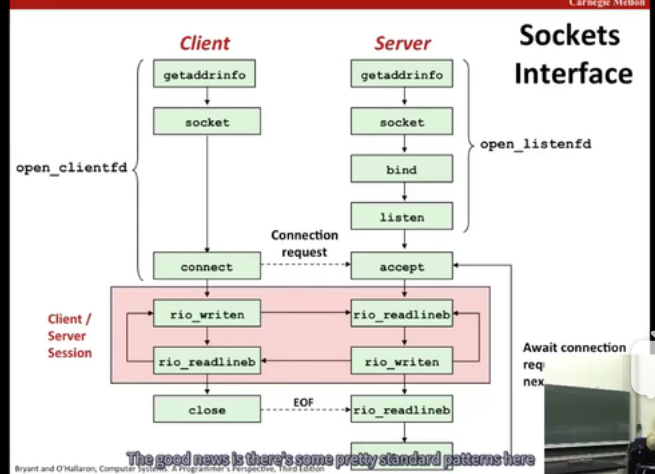
1.开启服务器
2.开启客户端
4.关闭客户端
5.断开客户端
设置服务器的相关信息
创建socket descriptor ,也就是之后用来读写的file descriptor

请求kernel把socket address 和 socket descriptor绑定
Bind is kernel call to designate which service this program will be hosting
告诉内核将addr中的服务器套接字地址和套接字描述符sockfd联系起来,对于socket和connect,最好方法是用getaddrinfo来为bind提供参数

由于客户端是发起连接要求的主动实体,服务器是被动等待连接请求的,所以默认条件下,内核会认为socket函数创建的描述符对应于主动套接字,它存在于一个连接的客户端。服务器调用listen函数告诉内核,描述符是被服务器而不是客户端使用的。
也就是说listen函数把sockfd从一个主动套接字转化为一个监听套接字,这个套接字可以接受来自客户端的连接请求。

等待来自客户端的连接请求到达listenfd,然后在addr中填写客户端的套接字地址,并且返回一个已连接描述符,这个描述符可以用来利用Unix I/O 函数与客户端通信。

connect 函数试图与套接字地址为addr的服务器建立一个因特网链接,其中addrlen是sizeof(sockaddr_in)connect函数会阻塞,一直到连接成功或者发现错误。




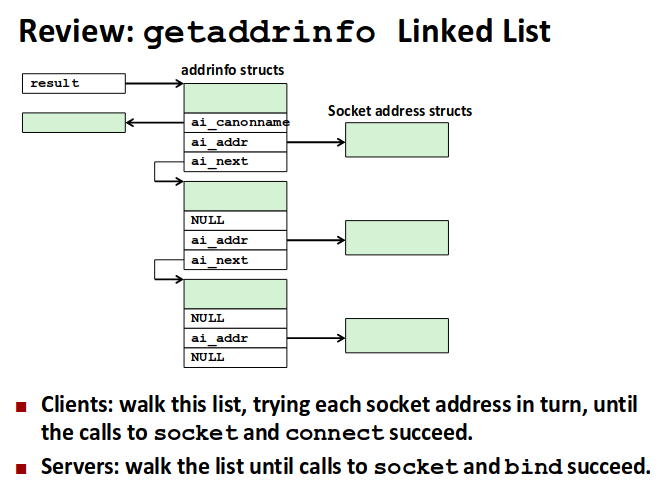
result 指向addrinfo结构的链表


以下函数是用来把域名转化为IP地址的
1 | int main(int argc,char **argv){ |
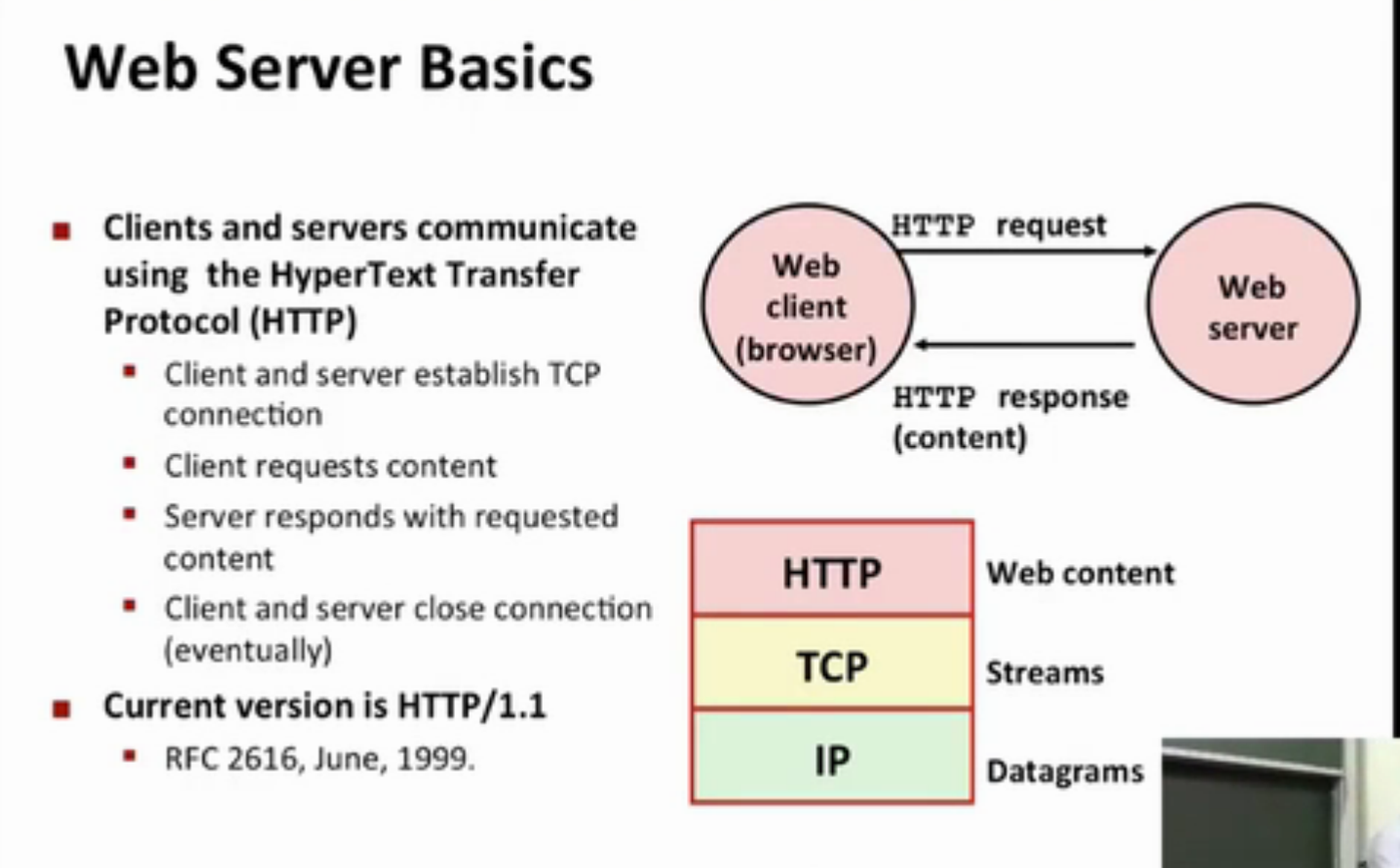
web server return content to clients,in 2 different ways:
1.取磁盘文件,并把他的内容返回给客户端,磁盘文件称为静态内容,返回文件给客户端叫服务静态内容。
2.运行一个可执行文件,把输出返回给客户端,运行的时候输出内容叫做动态内容,而运行程序并返回输出内容叫做服务动态内容。
web服务器返回的内容都是和它管理的某个文件相关联的,这些文件中的每一个都有一个唯一的名字叫URL,通用资源定位符。
超文本传输协议
通用网关接口,用来处理服务器向客户端提供动态内容的问题
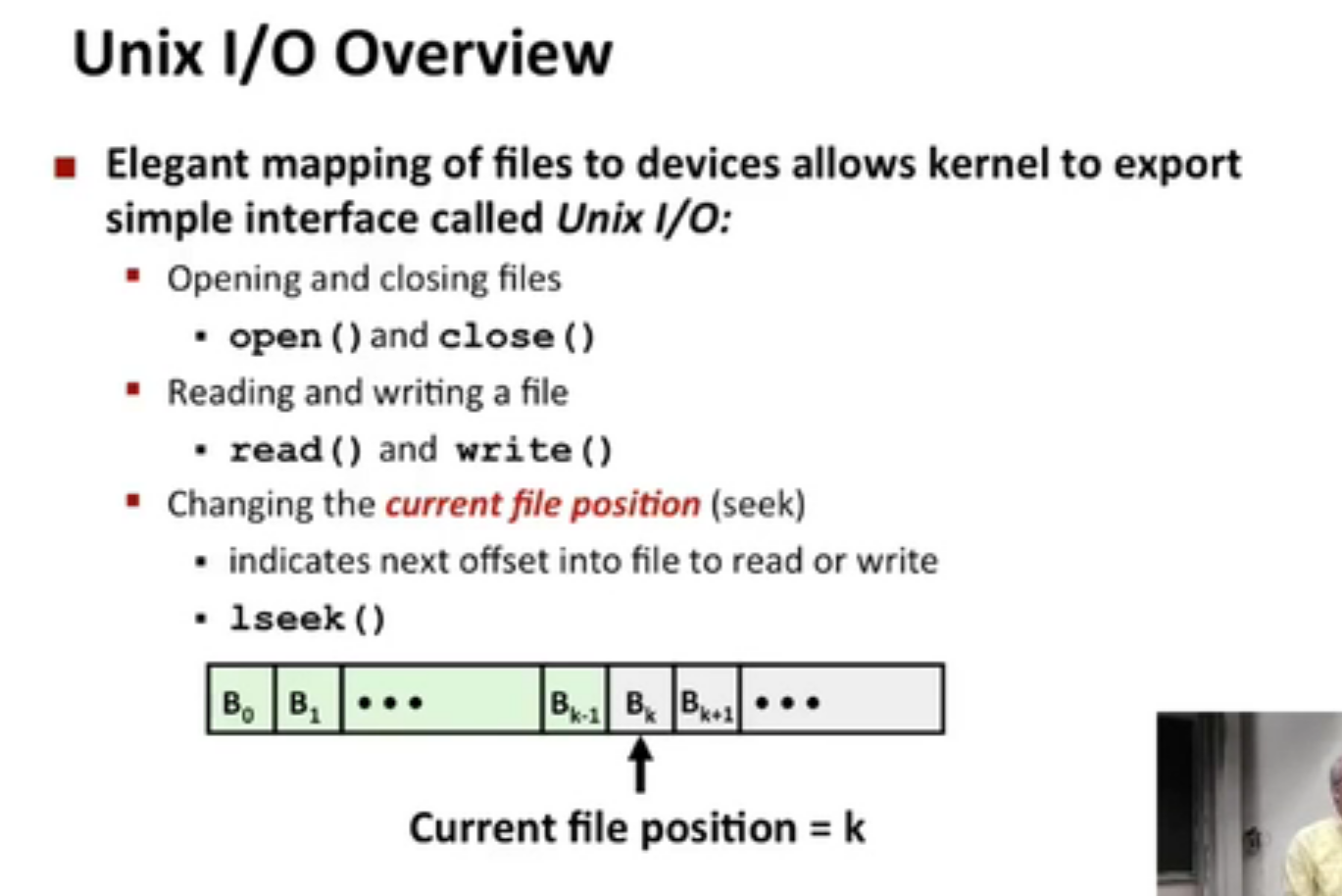
1.A linux file is a sequence of m bytes
B0,B1..Bm-1
2.all I/O devices and even the kernel are represented as files
/dev/sda2 (/usr disk partition)
/dev/tty2 (terminal)
1.regular file
2.directory
3.socket for communicating with a process on another machine
Kernel doesn’t know the difference between text files and regular files
starts with ‘/‘ and denotes path from root
/home/droh/a.c
../home/droh/a.c



Each while loop, execute 2 operating system function,that means you have to go to the kernel,go through,context switch,do whatever you wants,then switch back. in a word,it is too expensive.
1 | #include "csapp.h" |


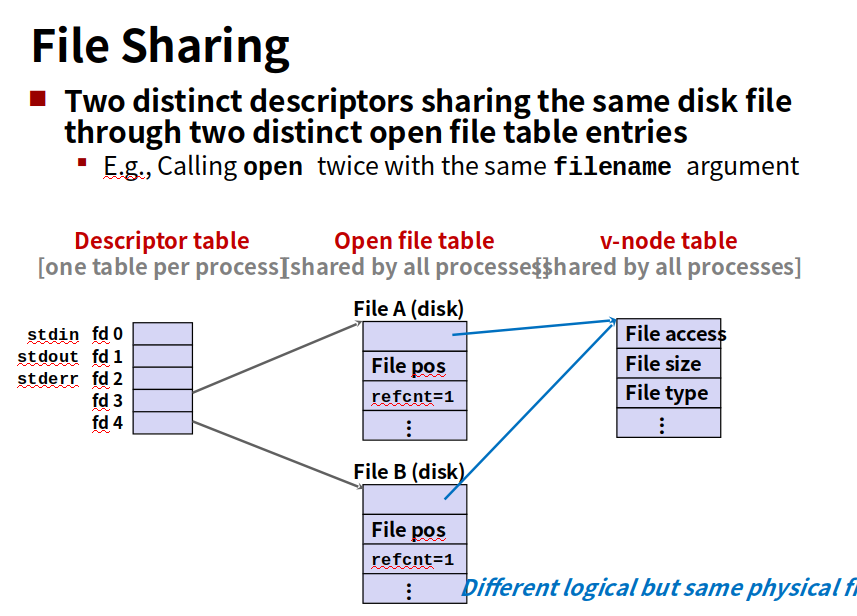
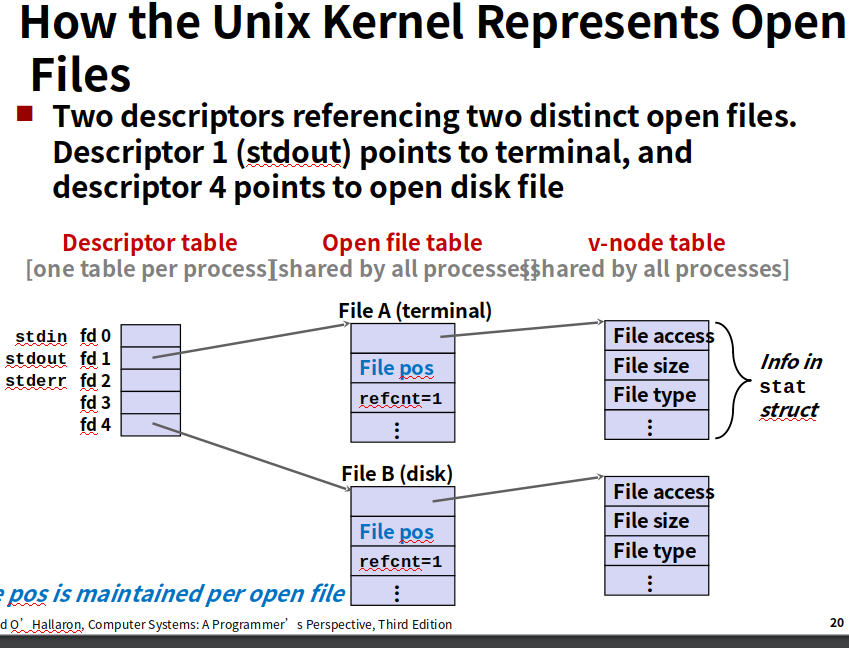
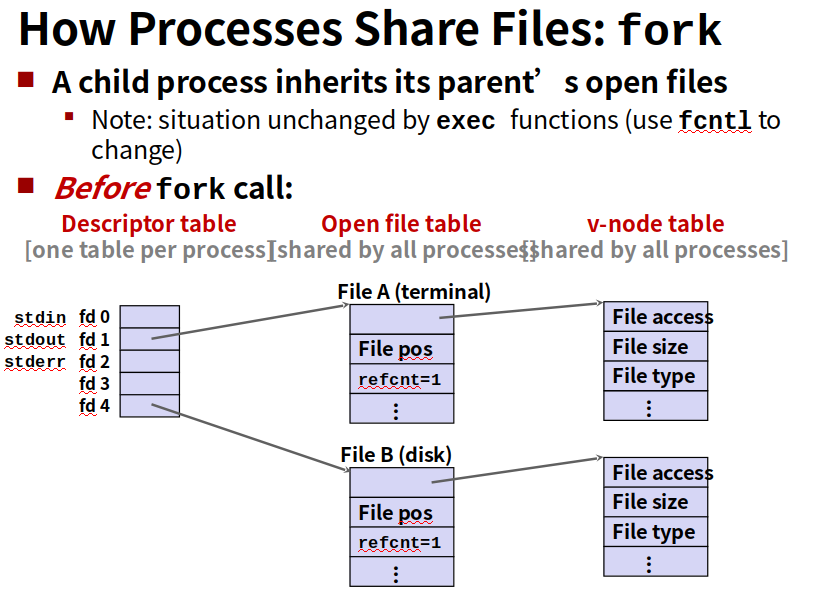
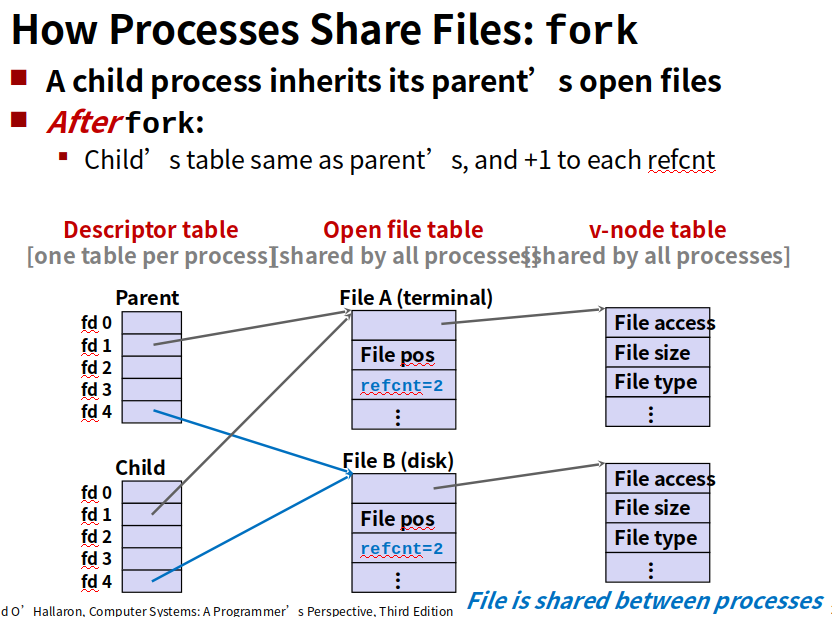
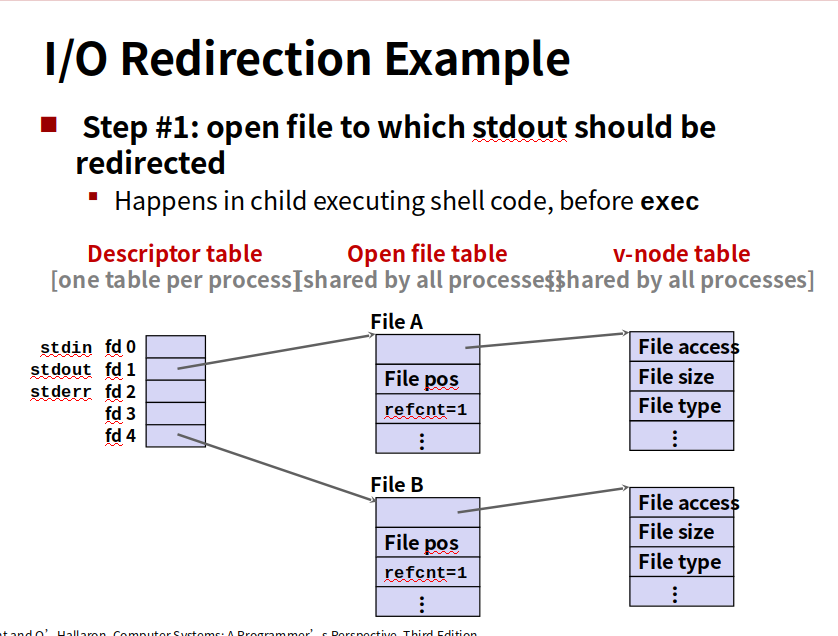
内核用三个相关的数据结构来表示打开的文件
1.每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的,每个打开的描述符表项指向文件表一个表项。
2.文件表。是所有进程共享的,保存当前文件位置,引用计数(当前指向该表项的描述符表项数),以及一个指向vnode表对应表项的指针
3.vnode表,所有进程共享
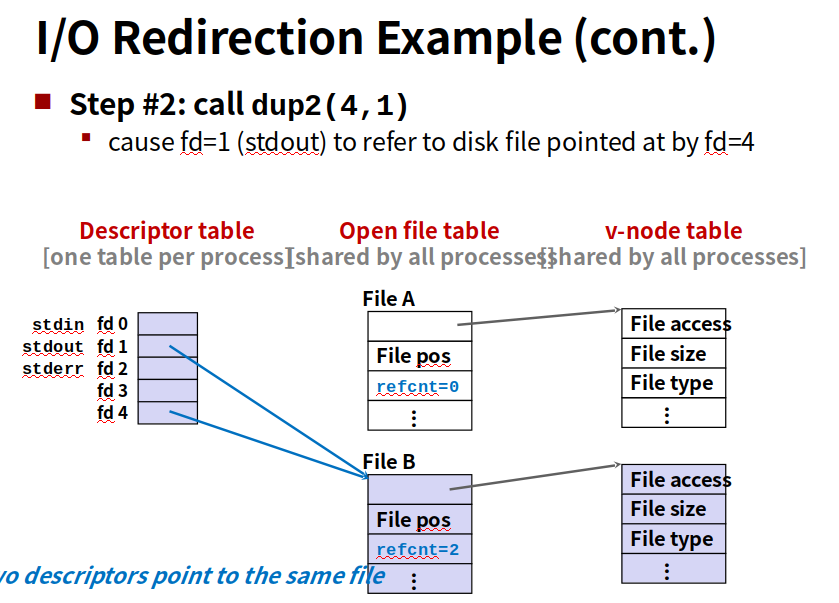
1 |
|
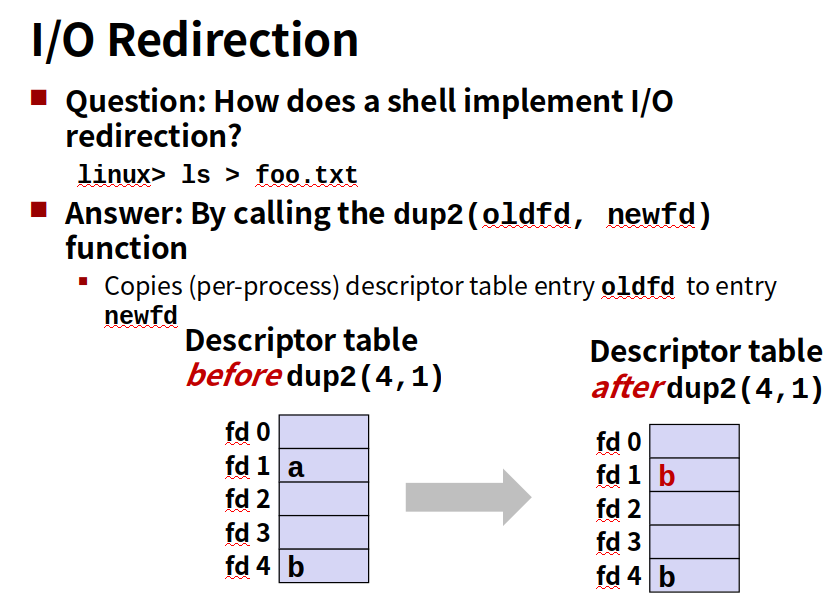
就是把重定向标准输入到描述符5
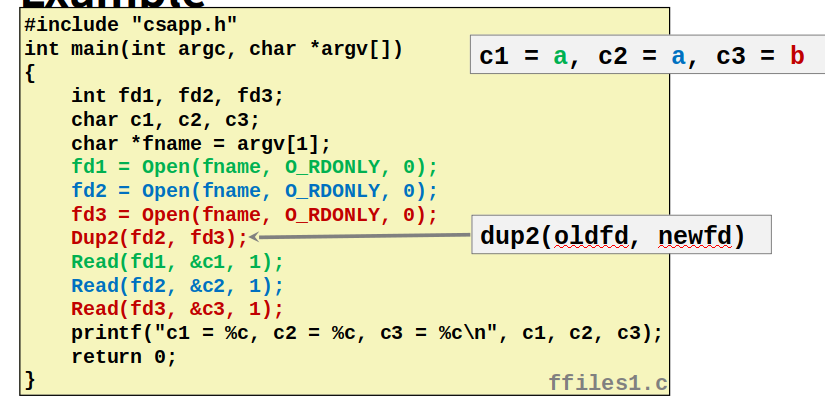
fd3重定向到了fd2,所以他们指向同样的open file table项,c2是第一个字符a,而c3在此基础上读下一个字符,所以是b。