Seq2Seq 模型
翻译
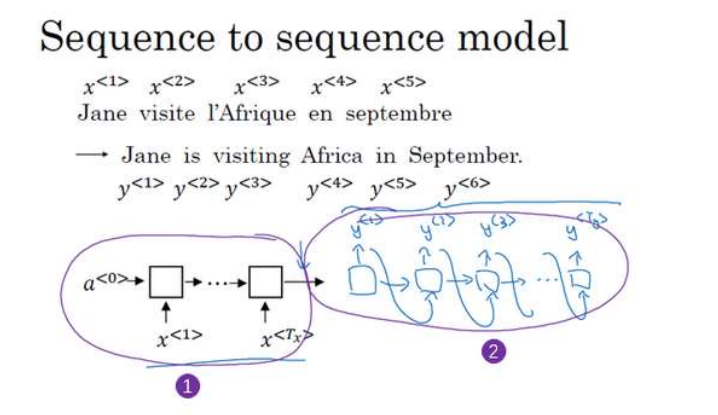
先建立一个编码网络,是一个RNN的结构,RNN的单元可以使GRU也可以是LSTM,每次向该神经网络输入一个法语单词,将输入序列接收完毕之后,RNN会输出一个向量来代表这个输入序列。
接着建立一个解码网络,如上图二所示,以编码网络的输出作为解码网络的输入。之后它可以被训练为每次输出一个翻译后的单词,一直到它输出序列的结尾或者句子结尾标记。而且每次生成一个标记,都会传递到下一个单元中进行预测。
图像描述
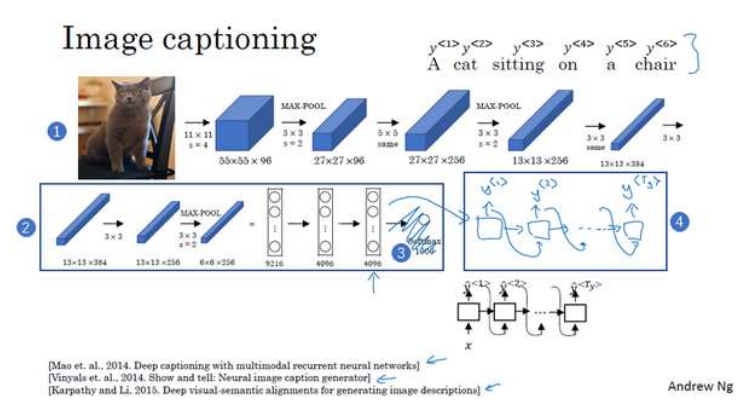
先把图片输入到卷积神经网络中,如一个预训练的AlexNet结构,然后让其学习图片的编码,如果是图片分类任务,最后得到的一个特征向量输出到一个softmax层,而这里把softmax层替换为一个RNN,RNN要做的就是生成图像的描述,每次生成一个单词。
选择最有可能的句子
机器翻译(条件语言模型)
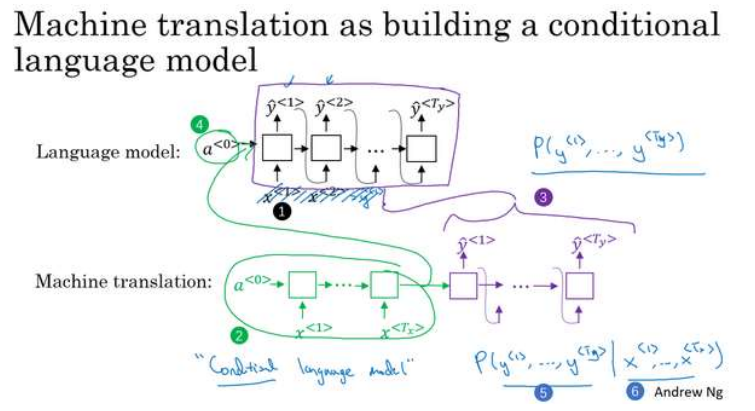
绿色表示encoder网络,紫色表示decoder网络,对于生成语言模型来说,encoder网络是以零向量开始,对于机器翻译模型来说,encoder网络会计算出一系列向量来表示输入的句子,有了这个输入句子,decoder网络就可以从这个句子开始,而不是从零向量开始,所以叫条件语言模型

x这里是法语句子,当进行机器翻译的时候,要找到一个英语句子y,使得条件概率最大化。通常使用束搜索方法。
我们W1生成的语言模型是在一个句子当中随机生成单词,但是例如下面句子:

随机生成的语言模型挑选了JANE IS 之后,由于going在英语中更加常见,因此很有可能采取下面那一句实际上并不太好的翻译。
Beam search
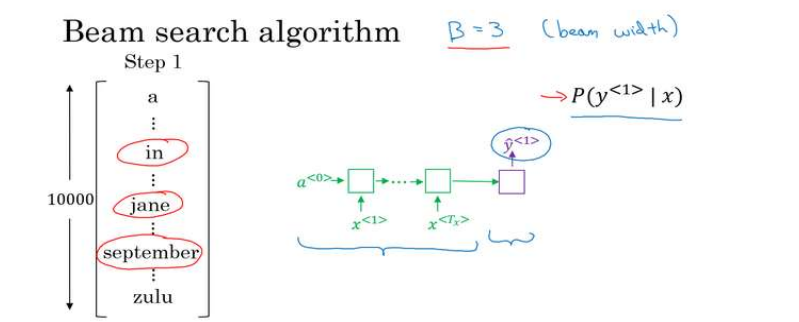
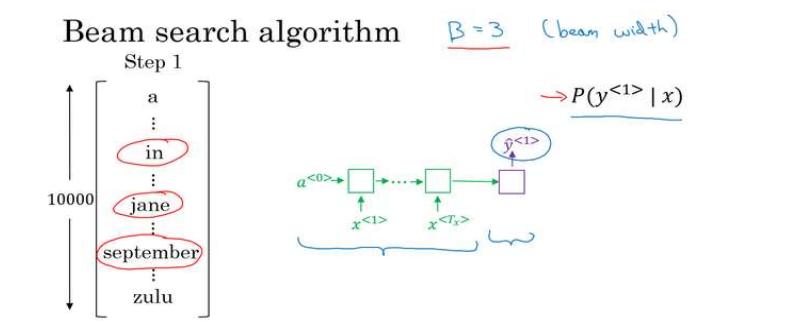
列出一个10000词的词汇表,为了简化问题,忽略大小写,把所有单词都以小写列出来,首先利用编码部分评估第一个单词的概率值,贪婪算法只会挑出最可能的一个单词,而beam search有一个参数B,例如设为3,那么就会考虑三个不同的单词。
所以第一步就是输入法语句子到编码网络,然后会解码这个网络,softmax层会输出10000个概率值,取前三个存起来。
第二步,假设已经选出了in,jane,september。作为第一个单词红最有可能的选择,算法接下来会针对每一个单词考虑第二个单词是什么。
把第一个单词输出作为下一个单元的输入,表示考虑第一个单词的情况下预测第二个单词。在第二步中我们更关心的事要找到最可能的第一个和第二个单词对,写成条件概率,就是上面的7式,等于第一个单词出现的概率乘以考虑第一个单词的情况下第二个单词的概率。
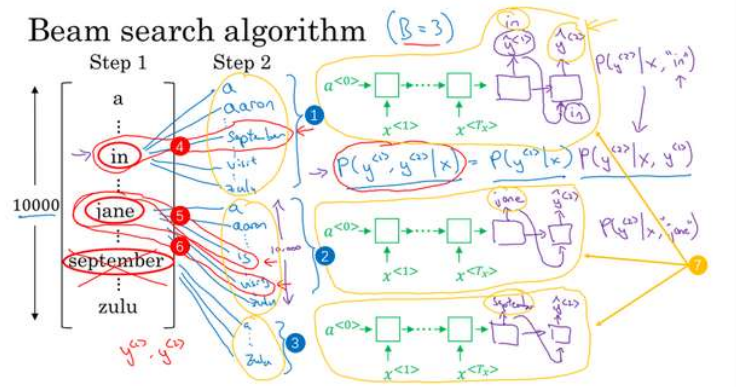
当选中了第一个单词的3个候选的时候,每个候选单词有10000个选择,所以一共有3x10000=30000中可能结果,按照第一和第二个词的概率,选出前三个,把这30000个可能性又变成了3个。
如果找到了第一个和第二个单词对最有可能的三个选择分别是in September,jane is 和jane visits,那么就去掉了september作为第一个单词的可能。
改进集束搜索

但概率都小于1,很多个小于1的数相乘,会得到很小很小的数字,会造成数值下溢。因此可以加上log,最大化这个log求和的概率值。
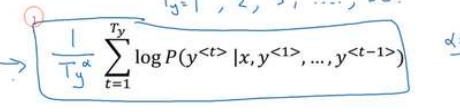
对于目标函数可以做一些改变,如果要预测一个很长的句子,那么每个单词都要乘以一个很小的数字,最后得到一个更小的概率值,所以这个目标函数有一个缺点,就是会不自然地倾向于更短的翻译结果。
我们可以不再最大化这个目标函数,而是把它归一化通过除以翻译结果的单词数量。这时候这个目标函数也叫作归一化的对数似然函数,也就是取每个单词的概率对数值的平均,这样很明显地减少了对输出长的结果的惩罚,
同时我们也可以对这个单词数量加上一个指数α,这是一个超参数,如果α=0,则不进行归一化,如果α为1,相当于用完全长度来归一化。
总结一下如何运行这个算法:

误差分析
模型有两个部分,一个神经网络模型(seq-to-seq),我们称为RNN模型,实际上是个编码器和解码器。另一部分是束搜索算法,以某个集束宽度B运行。
如果翻译错误的话,究竟是模型的那个部分出了错呢?

假设y*是理想结果,而与y^是机器给出的结果,如果是情况一的话,RNN模型输出的结果是
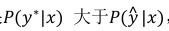
但是束搜索却选择了y^,明明y*的得分更高,因此是束搜索算法出了错。
第二种情况则是RNN模型出了错,它评分大小比较给错了。