词汇表征
one-hot encoding
比如如果man在词典里是第 5391 个,那么就可以表示成一个向量,只在第 5391 处为 1(上图
编号 2 所示),我们用O 5391 代表这个量,这里的O代表 one-hot。接下来,如果 woman 是编
号 9853(上图编号 3 所示),那么就可以用O 9853 来表示,这个向量只在 9853 处为 1
缺点 孤立了单词,使得算法对相关词的泛化能力不强

word embedding
例如要把单词表征为一个三百维的向量,每一维数值大小表示这个单词与对应类别的联系程度,如上图,man与woman与gender联系比较大,因此数值接近于1,而与royal联系比较小,因此数值趋近于0.
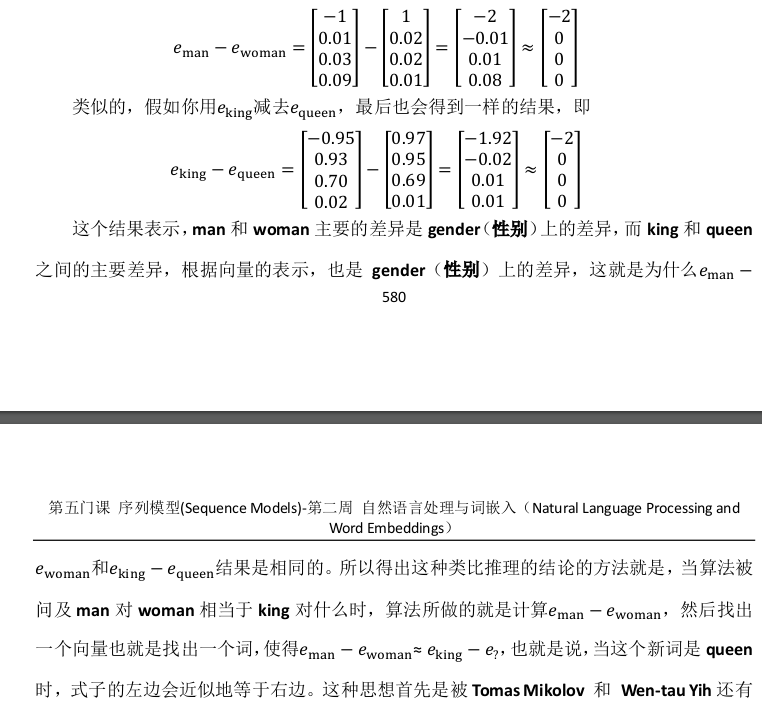
你能做的就是找到单词 w 来
使得,e man − e woman ≈ e king − e w 这个等式成立,你需要的就是找到单词 w 来最大化e w 与
e king − e man + e woman 的相似度,即
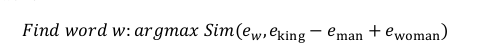
而计算相似度,通常使用余弦相似度。
语言模型
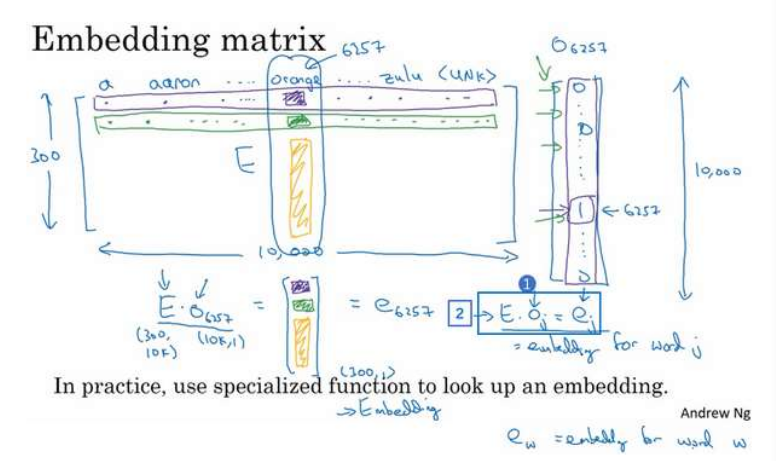
假如要把单词压缩成一个300维的嵌入向量,然后一共有10000个单词,那么可以随机初始化一个300x10000的矩阵。每一列代表一个单词的嵌入向量,那么把这个随机的矩阵与一个one-hot向量相乘就得到了这个单词的嵌入向量。
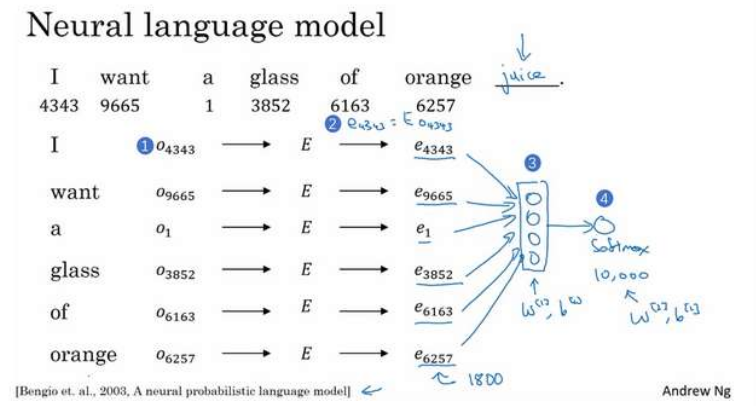
然后把如果你要预测
“I want a glass of orange ___.”,
的下一个词
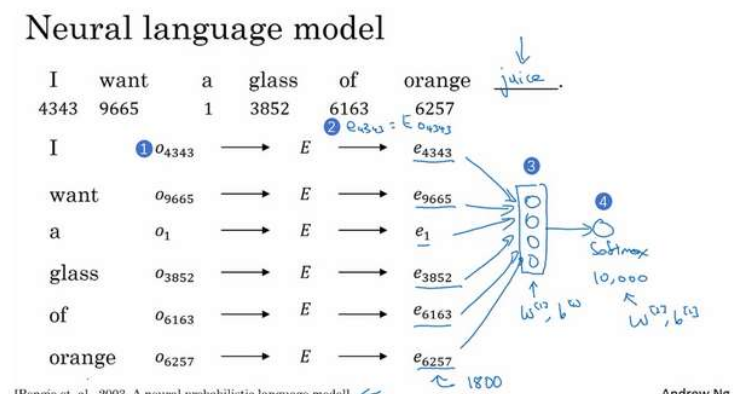
把这个句子所有单词转换为嵌入向量后,全部放到一个隐藏层中(上图3),然后再通过一个分类的softmax层,预测出对应单词。
在这里这个隐藏层是一个1800维的向量(6x300),有自己的参数。
如果你的目标是建立一个语言模型,那么一般选取目标词之前的几个词作为上下文。
但如果你的目标不是学习语言模型本身,也可以选择其他上下文。
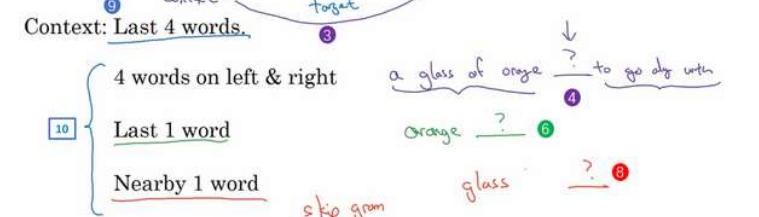
例如要预测一个句子中间的单词,可以用前面和后面各4个单词作为上下文。
或者你想用一个更简单的上下文,也许只提供目标词的前一个词。
word2Vec
假设在训练集中给定了一个这样的句子:“I want a glass of orange juice to go along with
my cereal.”,在 Skip-Gram 模型中,我们要做的是抽取上下文和目标词配对,来构造一个监
督学习问题。
我们要随机选一个单词作为上下文词,比如选orange,然后要随机在一定词距内选择另外一个词,作为目标词,通过这种方法来学到一个好的词嵌入模型。
Word2Vec Model
有两个模型,一个是skip-gram,另外一个是Word2Vec模型。


但是这种方法对于词汇量很大的词汇表来说运算速度会变得非常非常的慢。
解决方法:
分级softmax分类器
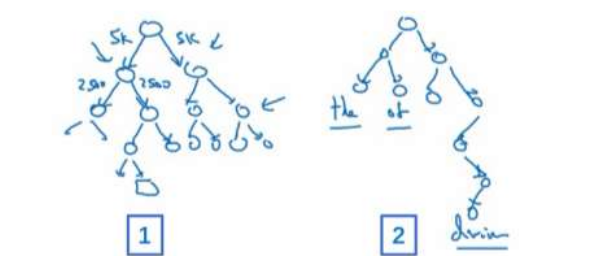
意思就是
说不是一下子就确定到底是属于 10,000 类中的哪一类。想象如果你有一个分类器(上图编
号 1 所示),它告诉你目标词是在词汇表的前 5000 个中还是在词汇表的后 5000 个词中,假
如这个二分类器告诉你这个词在前 5000 个词中(上图编号 2 所示),然后第二个分类器会
告诉你这个词在词汇表的前 2500 个词中,或者在词汇表的第二组 2500 个词中,诸如此类
常用的词会在树的顶部,不常用的词会在树的更加深的地方。
而且实际上上下文词的概率p(c)的分布并不是单纯的在训练集语料库上均匀且随机的采样得到的,而是采用了
不同的分级来平衡更常见的词和不那么常见的词
Cbow 与 skip-gram
CBOW是从原始语句推测目标字词,对于小型数据库比较合适。而skip-gram正好相反,是从目标字词测出原始语句,在大型语料中表现更好。
Negative Sampling
上面介绍的skip-gram模型实际上是构造一个监督学习的任务,把上下文映射到了目标词上面,让你学到一个实用的词嵌入,缺点在于softmax计算起来很慢。
在这个算法中要做的是构造一个新的监督学习问题,给定一对单词比如orange和juice,去预测这是否是一对上下文词-目标词(context-target)
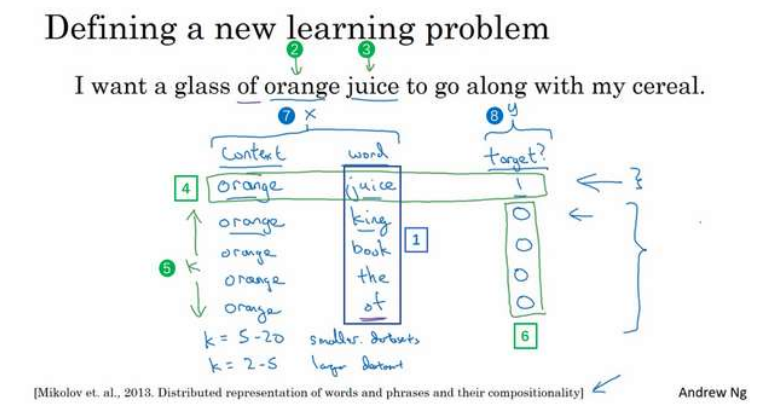

然后接下来构造一个监督学习问题,其中学习算法输入x,输入这对词,编号7,要去预测目标的标签,编号8,即预测输出y,因此问题就是给定一对词像orange和juice,判断这两个词究竟是分别在文本和字典中随机选取得到的,还是通过对靠近两个词采样获得的,这个算法就是要分辨这两种不同的采样方式。
*选取K:
K次就是确定了上下文词后,在字典中抽取K次随机的词
如何选取K?如果是小数据集,5-20比较好,如果数据集很大,K2-5比较好。
Model
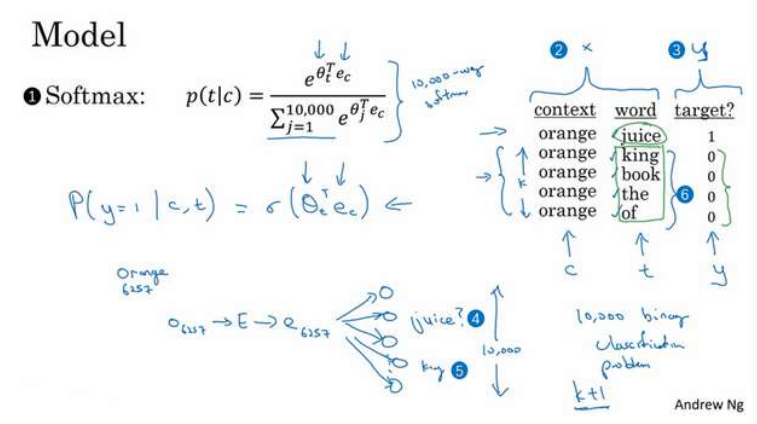
学习从x映射到y的监督学习模型,这个(上图编号 2 所示)将是新的输入x,这个(上图编号 3 所示)将是你要预测的值y。
为了定义模型,将记号c表示上下文词,记号t表示可能的目标词,再用y表示0和1,表示是否是一对上下文-目标词,要做的就是定义一个逻辑回归模型,给定输入的c,t对的条件下,y=1的概率,即:
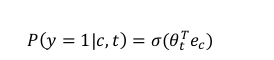
这个模型基于逻辑回归模型,不同的是我们把一个sigmoid函数作用于θ_t^Te_c,θ_t表示目标词对应的参数向量,而e_c对应上下文词的嵌入向量,如果有K个样本,可以把它看做1/K的正负样本比例,即每一个正样本你都有K个对应的负样本来训练一个类似逻辑回归的模型。
然后把它看成一个神经网络,如果输入词是orange,即词6257,你要做的事输入one-hot向量,再传递给E,通过两者相乘获得嵌入向量e6257,就得到了10000个可能的逻辑回归分类问题。其中一个将会是用来判断目标词是否是juice的分类器,但并不是每次迭代都训练全部10000个,只训练其中的(K+1)个,这样会减少计算成本,只需要更新K+1个逻辑单元。
说白了负采样就是有一个正样本词orange和juice,然后你会特意去生成一系列负样本,因此叫负采样。每次迭代你选择K个不同的随机的负样本词去训练你的算法。
该怎样选取负样本?
如果均匀且随机抽取负样本,这对于英文单词的分布非常没有代表性,而如果根据其在语料中的经验频率进行采样,会导致在like,the,of,and等词汇上有很高的频率。
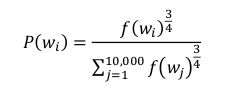
Glove 词向量

我们曾通过挑选语料库中位置相近的两个词,列举出词对,glove算法就是使其关系明确化。
假定Xij是单词i在单词j上下文中出现的次数,你也可以遍历你的训练集,然后数出单词i在不同单词j上下文中出现的个数。如果定义上下文和目标词为任意两个位置相近的单词,假设是左右各10个词的距离,那么Xij就是一个能够获取单词i和单词j出现位置相近时候频率的计数器。
glove就是把他们的差距作最小化处理。
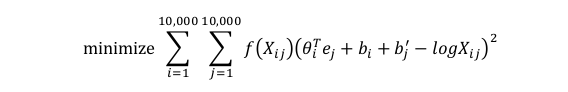
f(Xij)是一个加权项,如果Xij为0的话,f(Xij)也为0,防止出现log0的情况!
另一个作用是有的词在英语里出现十分频繁,比如this,is,of,a等等,这叫做停用词。但也有些不常用的词,比如durion,想把它考虑在内但是又不像那些常用词那样频繁,因此加权因子f(Xij)就可以是一个函数,即使是像durion这样不常用的词也能给予大量有意义的运算。
情感分类
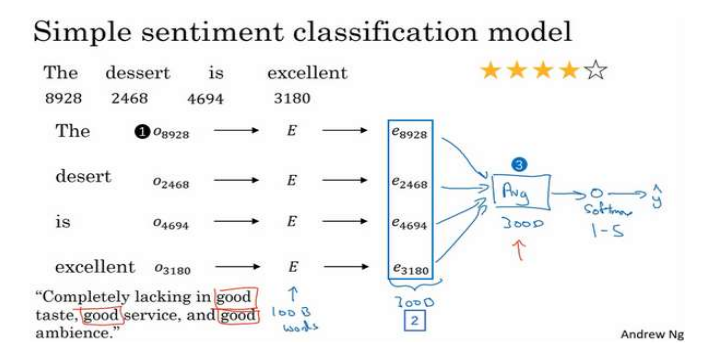
方法一
把这个句子里的所有单词对应的嵌入向量求和或者取平均,得到一个平均值计算单元(上图编号3),把这个特征向量送入softmax分类器,然后输出y。
但是这种方法没有考虑词序,例如Completely lacking in good taste,good service and good ambiance.
good出现了很多次,分类器会有可能认为这是一个很好的评论,实际这是一个差评。
方法二:RNN
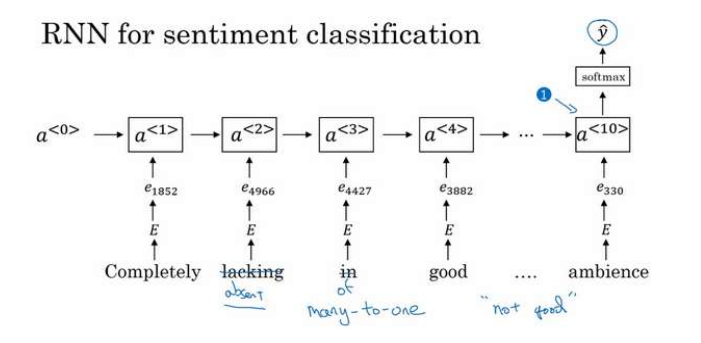
用一个多对一的RNN,考虑词的顺序效果。
由于你的词嵌入是在一个更大的数据集里训练的,这样的效果会更好,更好的泛化一些没有见过的新单词。