Overview of the model
创建一个基于字符的语言模型
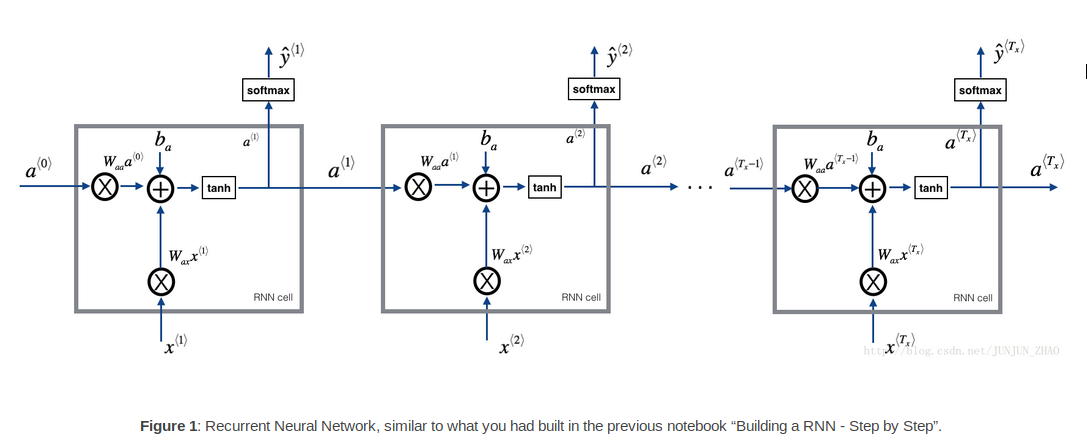
在每一个时间步,RNN基于先前的字符去预测下一个字符是什么,dataset X = {x1,x2,….xT}是输入,而输出Y={y1,y2…yT}使得y^T = x^(T+1)
大概步骤
Initialize parameters
Run the optimization loop
Forward propagation to compute the loss function
Backward propagation to compute the gradients with respect to the loss function
Clip the gradients to avoid exploding gradients
Using the gradients, update your parameter with the gradient descent update rule.
Return the learned parameters
clip
防止梯度爆炸或者弥散,让所有参数的梯度都限定在一个范围内,如某一个值如果大于maxValue,则这个值设置为maxValue
1 |
|
sample
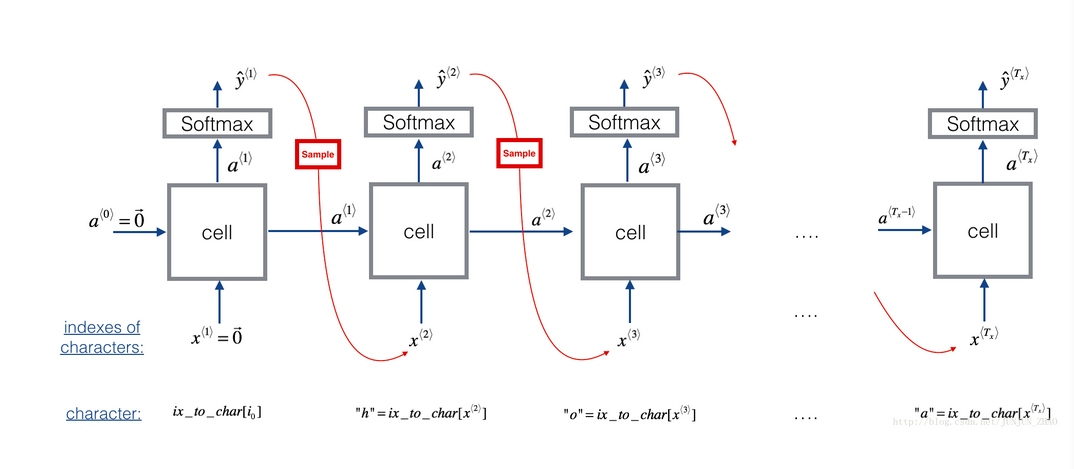
step1 设置好第0层激活层和第一个输入字符为0向量
forward propagate
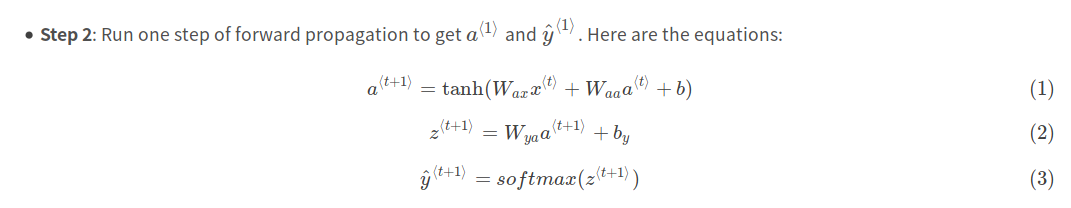
生成一个概率向量,就是这个向量所有数加起来是1,每个数代表着某个字符出现的概率。
采样,根据生成的概率向量,选择下一个生成的字符
替换x^t的值为x^(t+1),然后在forward propagate中继续重复这个过程,直到遇到”\n”字符。
1 | def sample(parameters, char_to_ix, seed): |
Gradient descent
1 | def optimize(X, Y, a_prev, parameters, learning_rate = 0.01): |
model
1 |
|
训练数据是88000个英文last name
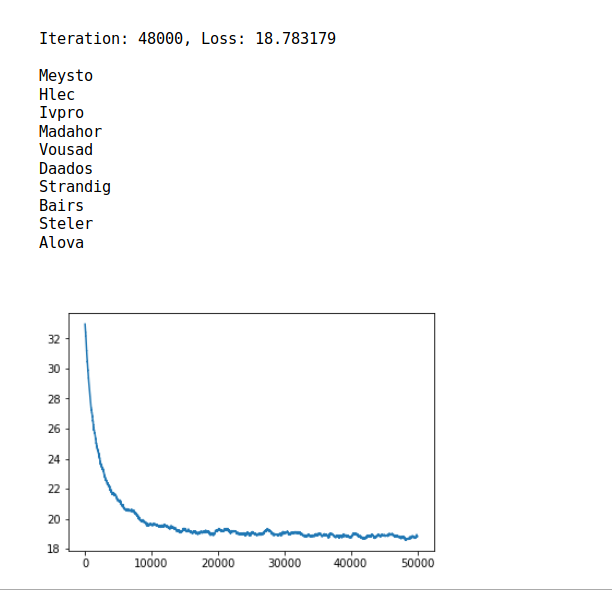
手把手搭建RNN
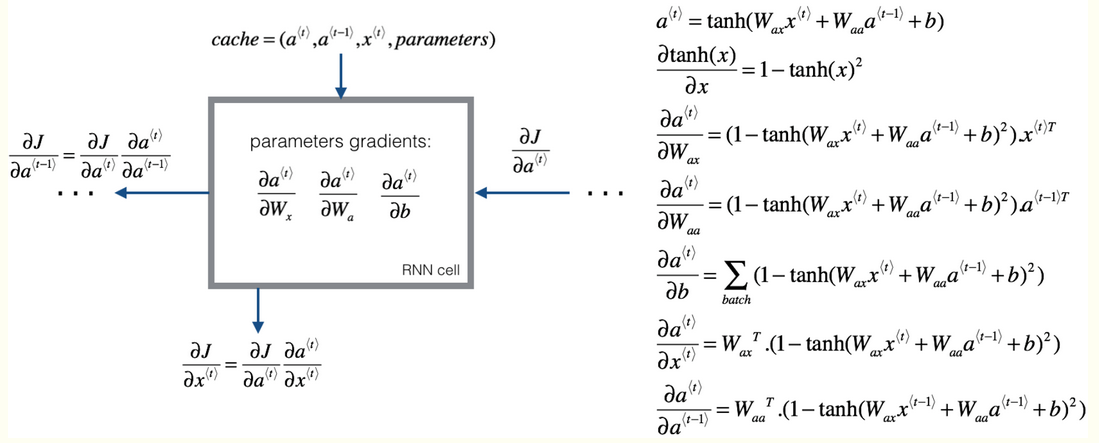
RNN cell
一个RNN可以看做是一个cell的重复
1.Compute the hidden state with tanh activation: a⟨t⟩=tanh(Waaa⟨t−1⟩+Waxx⟨t⟩+ba).
2.Using your new hidden state a⟨t⟩, compute the prediction ŷ ⟨t⟩=softmax(Wyaa⟨t⟩+by). We provided you a function: softmax.
3.Store (a⟨t⟩,a⟨t−1⟩,x⟨t⟩,parameters) in cache
4.Return a⟨t⟩ , y⟨t⟩ and cache
1 |
|
RNN forward
1 | def rnn_forward(x, a0, parameters): |
LSTM
遗忘门
我们假设我们正在阅读一段文本中的单词, 并希望使用 LSTM 来跟踪语法结构, 例如主语是单数还是复数。如果主语从一个单数词变为复数词, 我们需要找到一种方法来去除以前存储的单数/复数状态的内存值。在 LSTM 中, 遗忘门让我们这样做:

更新门

输出门

1 | # GRADED FUNCTION: lstm_cell_forward |
1 | def lstm_forward(x, a0, parameters): |
RNN backward pass
LSTM music generation
从一个更长的序列中随机选取30个数值片段来训练模型,因此不会设置x(1) 为 零向量。 设置每个片段都有相同长度Tx=30,使得矢量化更容易。
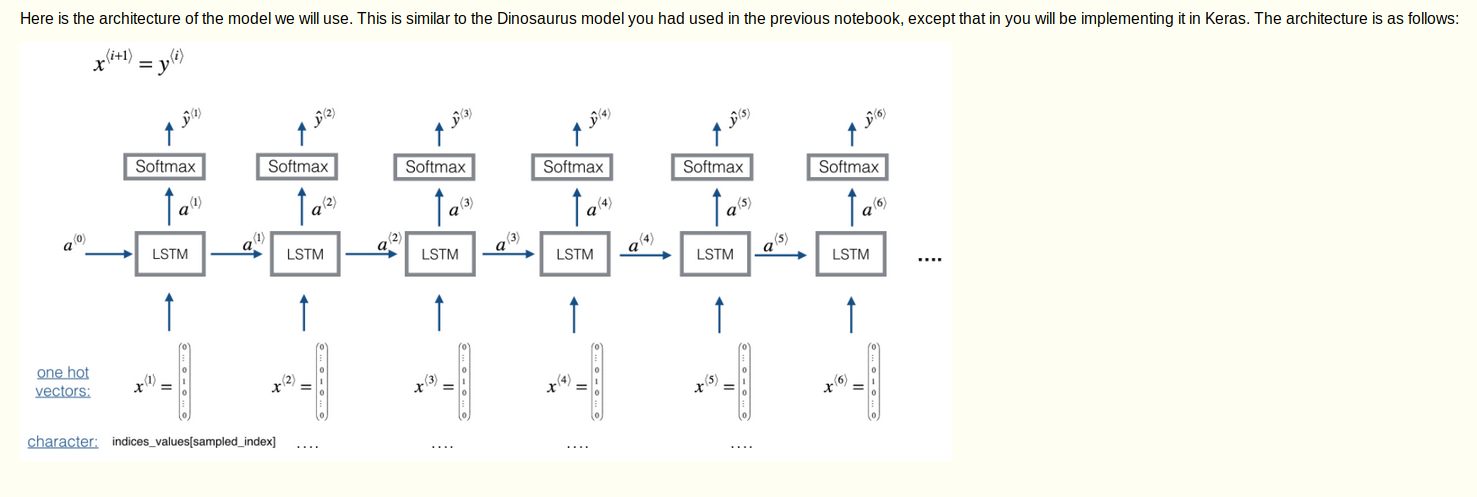
building model
对于序列生成,测试的时候不能提前知道所有的x^t数值,而使用x^t = y^(t-1)一次生成一个,因此要实现for循环来访问不同的时间步,函数djmodel()将使用for循环调用LSTM层TX T次,并且每次第Tx步都应该有共享权重,而不应该重新初始化权重。
在Keras中实现具有共享权重层的关键步骤
1.定义层对象
2.前向传播输入时候调用这些对象
1 | n_a = 64 |

1 | def create_model(Tx, n_a, n_values): |
1 | model = create_model(Tx = 30 , n_a = n_a, n_values = n_values) |
1 | opt = Adam(lr=0.1, beta_1=0.9, beta_2=0.999, decay=0.003) |
1 | m = 60 |
LSTM
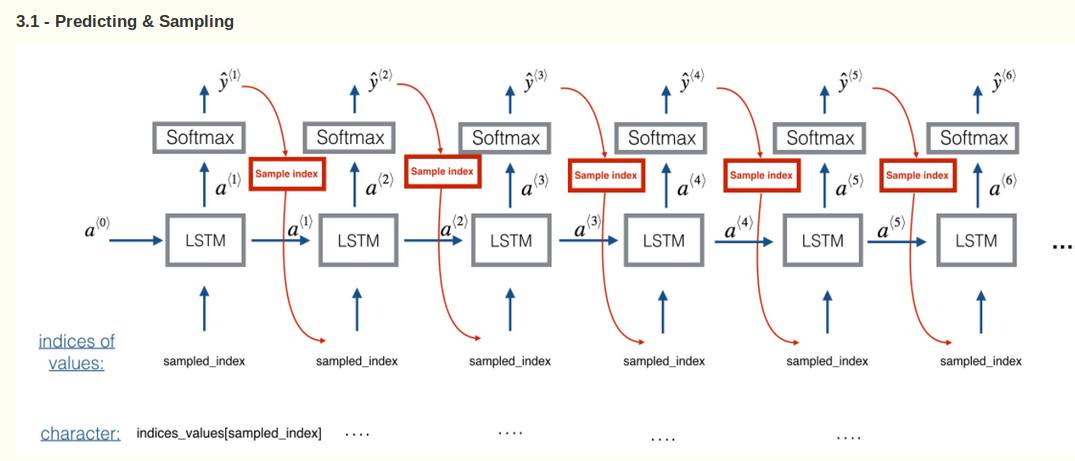
用上个cell预测的值来作为下个cell的输入值
1 | def music_inference_model(LSTM_cell, densor, n_values = n_values, n_a = 64, Ty = 100): |