人脸识别
one shot learning
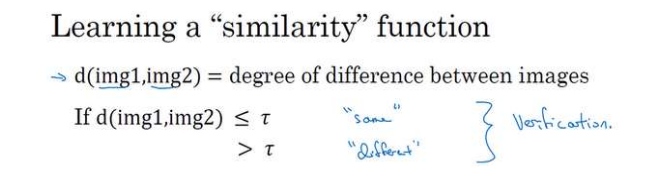
因为公司的数据库里面很可能只有该名员工一张照片,因此用一张图片投入神经网络,通过softmax输出分类显然不可行。因此应该学习一个相似函数,如果函数的结果大于某个阈值,说明不匹配,否则说明匹配。
siamese network
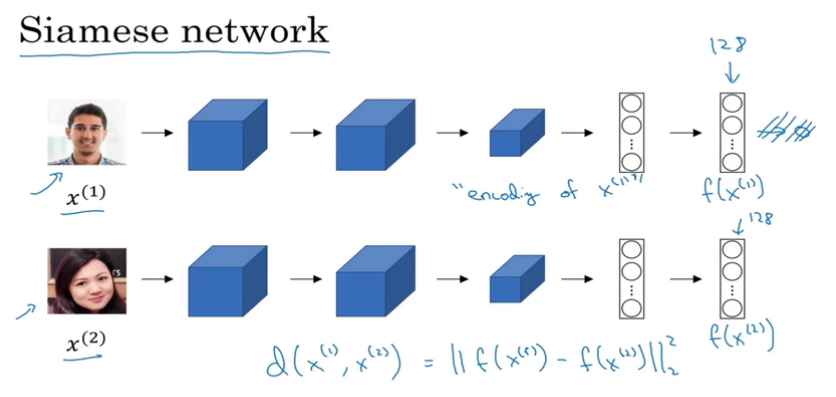
x1投入网络中,得到全连接层一个output vector,这个vector维度是128x1,记为encoding of x1
另外一张图片x2喂入网络,得到另外一个vector叫做encoding of x2
然后把二者距离定义为二者编码之差的范数。
更准确地说,神经网络的参数定义了一个编码函数f(x (i) ),如果给定输入图像x(i),这个网络会输出x (i) 的 128 维的编码。
三元组损失

目标:

遇到的问题:
如果f总是输出0,上面式子无意义
为了阻止网络出现这种情况,我们需要修改这个目标,也就是,这个不能是刚好小于等
于 0,应该是比 0 还要小,所以这个应该小于一个−a值(即||f(A) − f(P)|| 2 − ||f(A) −
f(N)|| 2 ≤ −a),这里的a是另一个超参数,这个就可以阻止网络输出无用的结果。按照惯
例,我们习惯写+a(即||f(A) − f(P)|| 2 − ||f(A) − f(N)|| 2 + a ≤ 0),而不是把−a写在后
面,它也叫做间隔(margin)
总结:
三元组损失函数的定义基于三张图片,假如三张图片A、 P、 N,即 anchor 样本、 positive
样本和 negative 样本,其中 positive 图片和 anchor 图片是同一个人,但是 negative 图片和
anchor 不是同一个人。
定义损失函数
1 | L(A, P, N) = max(||f(A) − f(P)|| 2 − ||f(A) − f(N)|| 2 + a, 0) |
这是一个三元组定义的损失,整个网络的代价函数应该是训练集中这些单个三元组损失的总和。
挑选数据集
现在我们来看,你如何选择这些三元组来形成训练集。一个问题是如果你从训练集中,
随机地选择A、 P和N,遵守A和P是同一个人,而A和N是不同的人这一原则。有个问题就是,
如果随机的选择它们,那么这个约束条件(d(A, P) + a ≤ d(A, N))很容易达到,因为随机
选择的图片,A和N比A和P差别很大的概率很大。我希望你还记得这个符号d(A, P)就是前几
个幻灯片里写的||f(A) − f(P)|| 2 ,d(A, N)就是||f(A) − f(N)|| 2 ,d(A, P) + a ≤ d(A, N)即
||f(A) − f(P)|| 2 + a ≤ ||f(A) − f(N)|| 2 。但是如果A和N是随机选择的不同的人,有很大的
可能性||f(A) − f(N)|| 2 会比左边这项||f(A) − f(P)|| 2 大,而且差距远大于a,这样网络并不
能从中学到什么。
因此要挑选最难学习的,就是要挑选 d(A,P)约等于 d(A,N)的三元组,
只有这样梯度下降法才有用,才能学到有意义的参数。
summary

人脸验证与二分类


预处理
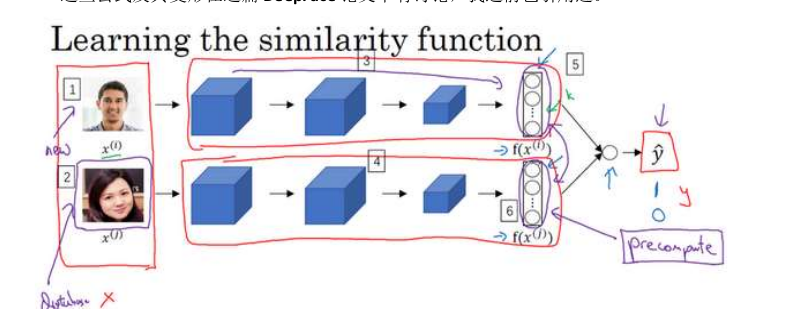
如果这是一张新图片(编号 1),
当员工走进门时,希望门可以自动为他们打开,这个(编号 2)是在数据库中的图片,不需
要每次都计算这些特征(编号 6),不需要每次都计算这个嵌入,你可以提前计算好,那么
当一个新员工走近时,你可以使用上方的卷积网络来计算这些编码(编号 5),然后使用它,
^ 。
和预先计算好的编码进行比较,然后输出预测值
神经风格迁移

怎么判断生成图像的好坏呢?我们把这个代价函数定义为两个部分。
J content (C, G)
第一部分被称作内容代价,这是一个关于内容图片和生成图片的函数,它是用来度量生
成图片G的内容与内容图片C的内容有多相似。
J style (S, G)
然后我们会把结果加上一个风格代价函数,也就是关于S和G的函数,用来度量图片G的
风格和图片S的风格的相似度。1
J(G) = aJ content (C, G) + βJ style (S, G)
梗概

content cost function

现在你需要衡量假如有一个内容图片和一个生成图片他们在内容上的相似度,我们令这
个a [l][C] 和a [l][G] ,代表这两个图片C和G的l层的激活函数值。如果这两个激活值相似,那么
就意味着两个图片的内容相似。
1
我们定义这个: J content (C, G) = 2 ||a [l][C] − a [l][G] || 2 ,为两个激活值不同或者相似的程度,
我们取l层的隐含单元的激活值,按元素相减,内容图片的激活值与生成图片相比较,然后
510第四门课 卷积神经网络(Convolutional Neural Networks)-第四周 特殊应用:人脸识别和神经风格转换
(Special applications: Face recognition &Neural style transfer)
1
取平方,也可以在前面加上归一化或者不加,比如 或者其他的,都影响不大,因为这都可以
2
由这个超参数 α 来调整(J(G) = aJ content (C, G) + βJ style (S, G))。
style cost function



对于这个风格矩阵,你要做的就是计算这个矩阵也就是G [l] 矩阵,它是个n c × n c 的矩阵,
也就是一个方阵。记住,因为这里有n c 个通道,所以矩阵的大小是n c × n c 。以便计算每一对
[l]
激活项的相关系数,所以G kk ′ 可以用来测量k通道与k′通道中的激活项之间的相关系数,k和
k′会在 1 到n c 之间取值,n c 就是l层中通道的总数量。
可以看做这是两个通道间的协方差。
implementation
using an ConvNet to compute encodings

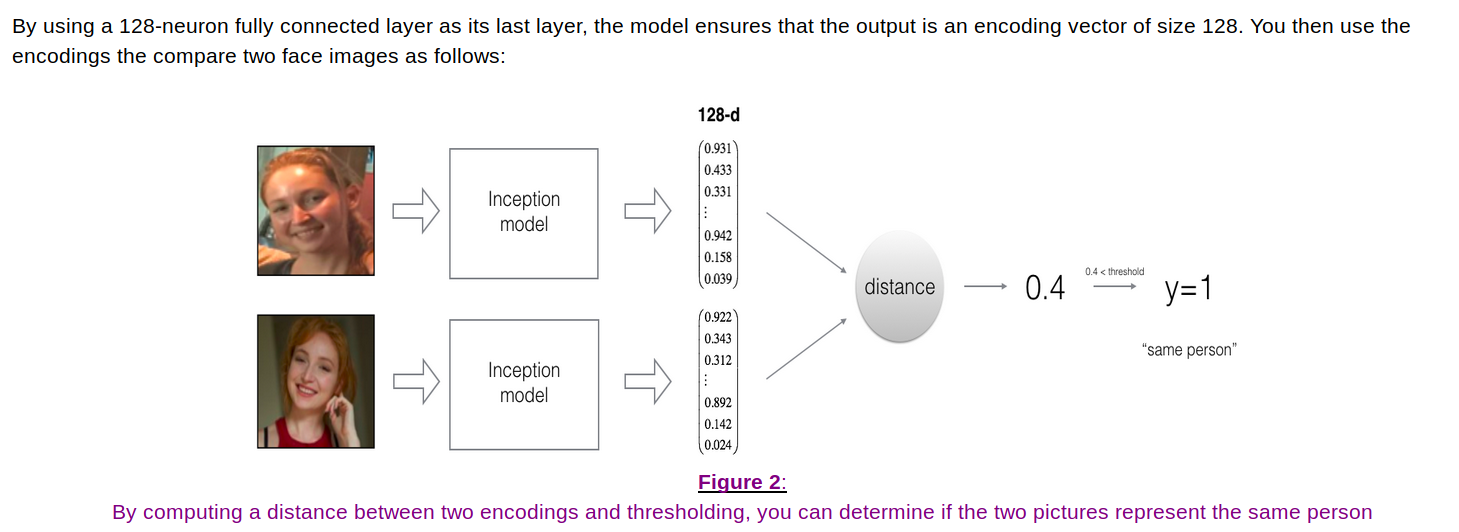
这里使用的是Inception Network
把两张图片分别转换成2个128维的向量,然后计算这两个向量的距离。
compute triplet loss

1 | # GRADED FUNCTION: triplet_loss |
verify
这里设定阈值!与数据库中已有的照片进行比较
1 | # GRADED FUNCTION: verify |
face recognition
在数据库中寻找dist与输入图片最小的,结果就是识别出来的人。
1 | GRADED FUNCTION: who_is_it |
Neural Style Transfer
compute the content cost
在网络里面,浅层的卷积网络倾向于检测一些如边缘与简单内容的低层次特征,深层的卷积网络倾向于检测一些高层次特征例如目标的类别等。
我们目标是生成的图片G与输入图片C有相同的内容。假设选定了某层的激活层来代表图片的内容,在实践中,选择那些不太深也不太浅——即中间的网络。
所以假定你选择一个隐含层,设定图片C作为预训练的VGG网络的输入,然后前向反馈,记a^[c]为你选择的隐含层的激活。 这将是一个维度为nHxnWxnC的张量。
对输入的图片G重复上述操作。
我们定义损失函数如下
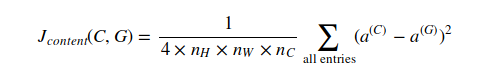
这里的nH,nW,nC分别为你所选择的隐含层的高度,宽度与通道数目。
为了方便计算J_content(C,G) ,需要把三维的volumns unrolled成二维的矩阵。
1 | # GRADED FUNCTION: compute_content_cost |
STYLE MATRIX
在线性代数中,风格矩阵也叫作Gram矩阵.
matrix G of set of vectors(v1,v2…vn)
是任意两个向量vi,vj的点乘的矩阵,看作是来衡量vi
与vj是有多相似的。如果vi与vj很相似,得到的点乘也会越大。
Gij=vTivj=np.dot(vi,vj)Gij=viTvj=np.dot(vi,vj). In other words, GijGij compares how similar vivi is to vjvj:
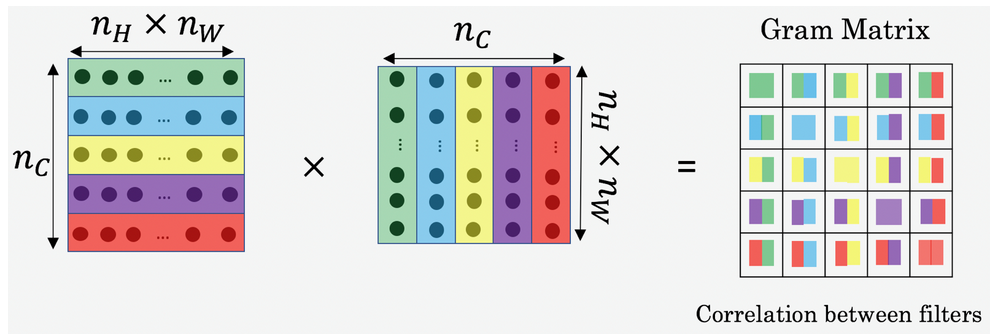
这个矩阵维度是(nc,nc),nc是filter的数量,Gij的值衡量了filter_i的激活与filter_j的激活的相似程度。
而矩阵的对角元素G_ii衡量了filter_i的活跃程度。举个例子,如果filter_i是用来检测竖直特征的,那么Gii就衡量了整张图片出现竖直特征的总体情况。
1 |
|
Style cost
生成了风格矩阵之后,你的目标就是最小化风格图片的Gram矩阵与生成图片的Gram矩阵的距离。这就可以写出一个损失函数,然后转化为一个最优化问题就行。

1 | # GRADED FUNCTION: compute_layer_style_cost |
定义J_style
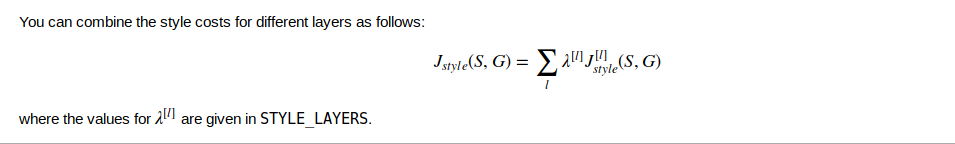
定义最终的cost

再对这个损失函数求优化问题就行了。
result: