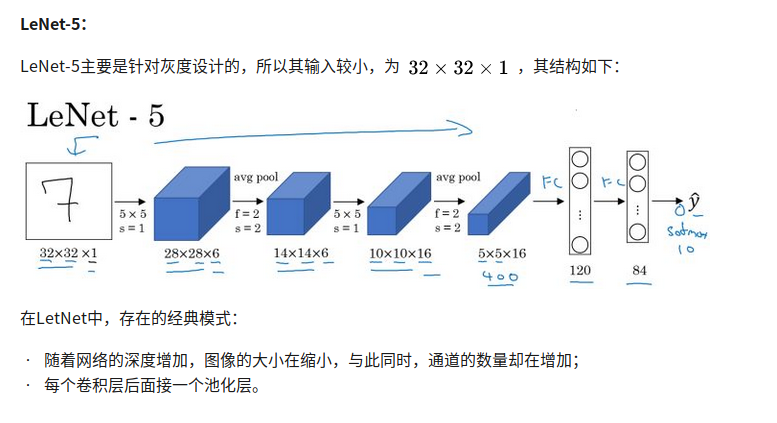
LeNet -5
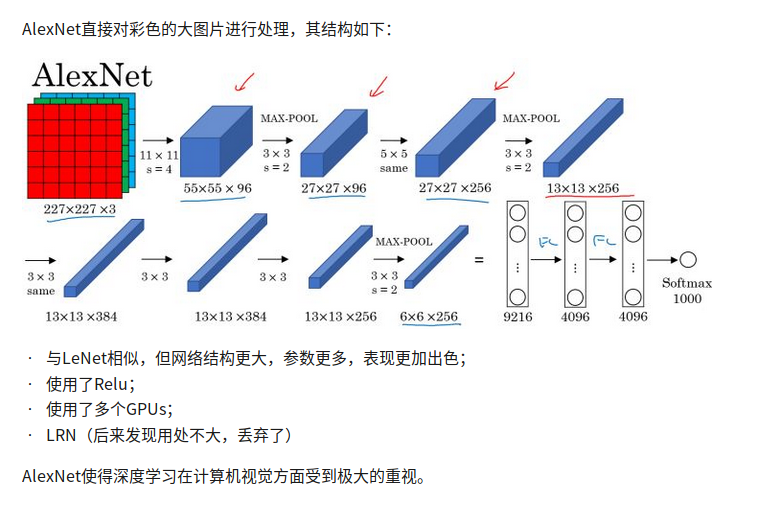
AlexNet
conv->max pool->conv->max pool->conv->conv->conv->conv->max pool->fc->fc->fc
VGG-16
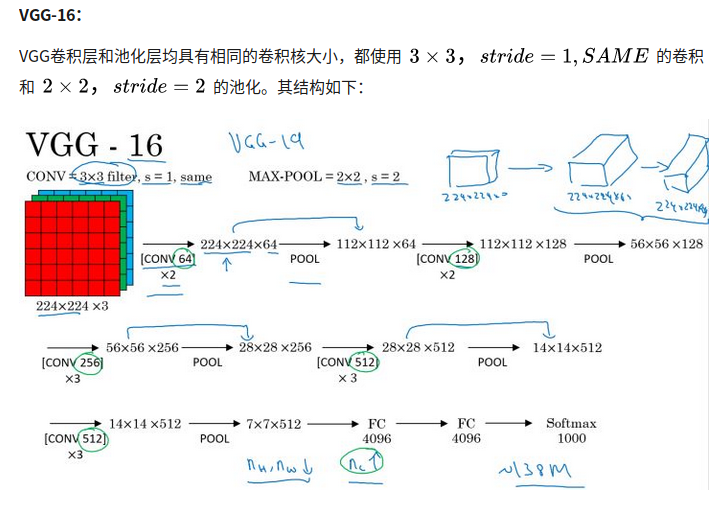
16指的是只有16层网络有需要学习的参数,pooling层是没有要学习的参数的。
箭头下方的[CONV 64]指有64个filter,x2值对两层作卷积
ResNet
residual block
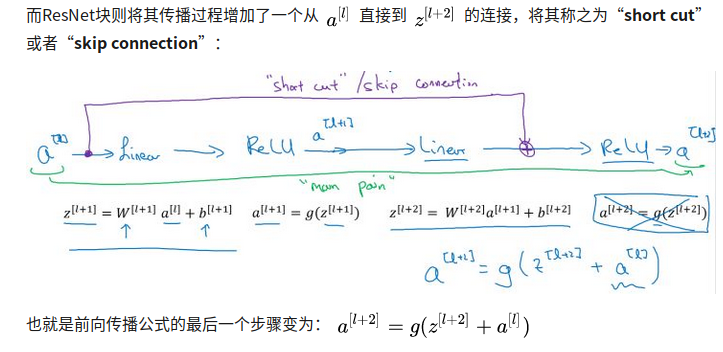
增加short cut之后成为残差块的网络结构
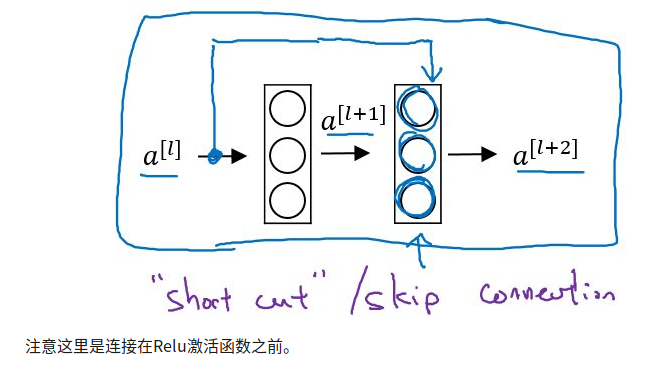
可以构建更为深层的网络
Residual Network
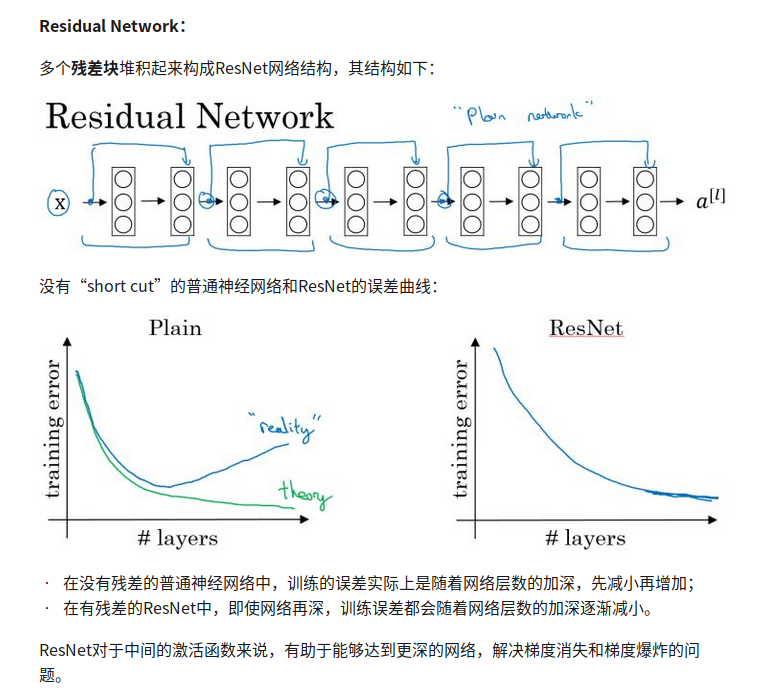
没有residual block的网络叫做plain network
why it works?

对于越深层的神经网络来说,参数越来越多,越来越难选择,将会导致连学习identity function(f(x)=x)都很困难,而如果用residual block,a^[l+2] = g(a^[l]) = a^[l],对于残差块来学习identity function 其实是很简单的,所以不影响性能。
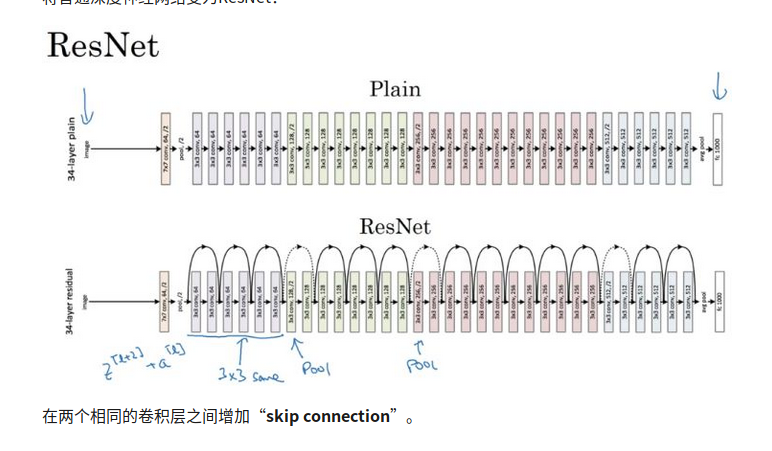
在经历了相同的conv之后增加一层pooling
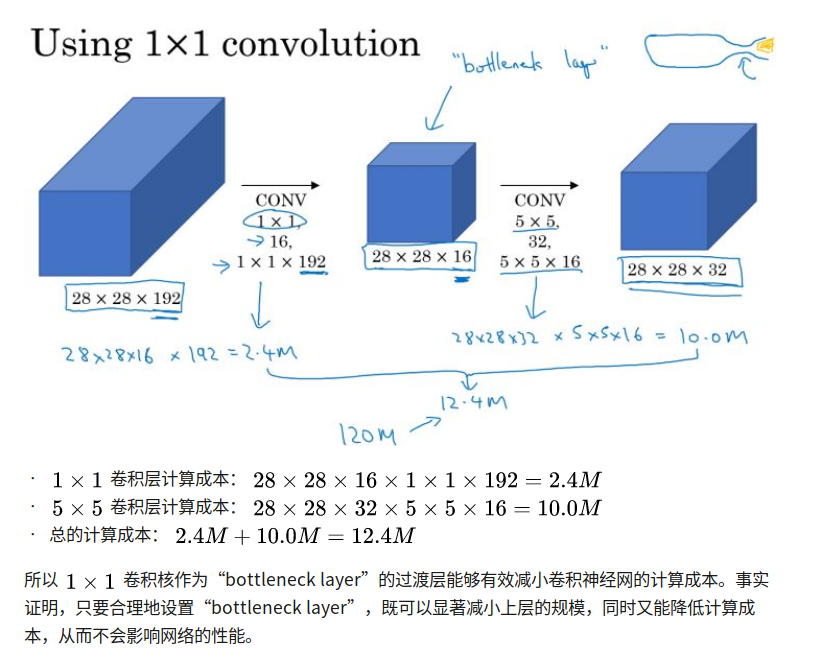
1x1 convolution
又叫做网中网
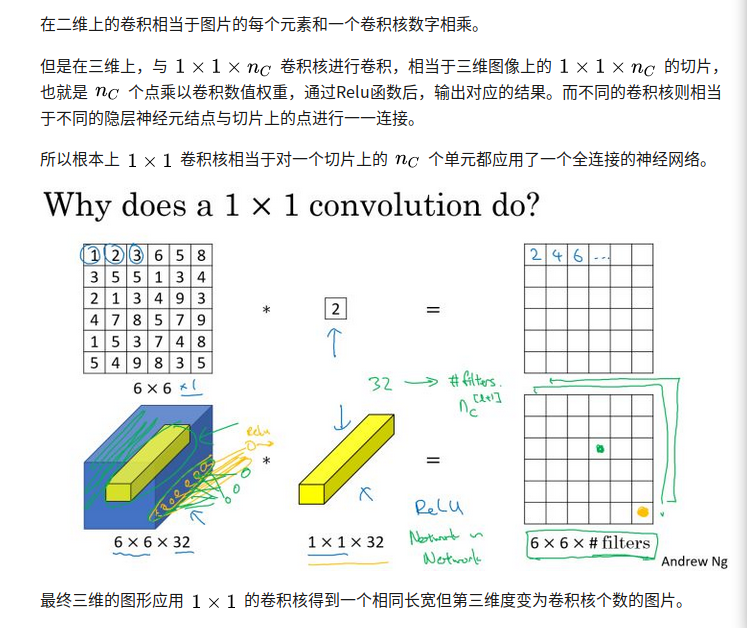
对一层 nxnxc 的图片,应用1x1xc的卷积核,得到新一层
nxnx1,f个filter处理后,就得到一个nxnxf的新层。
应用
降维或升维
压缩channel个数,当卷积核个数小于输入channel数量的时候
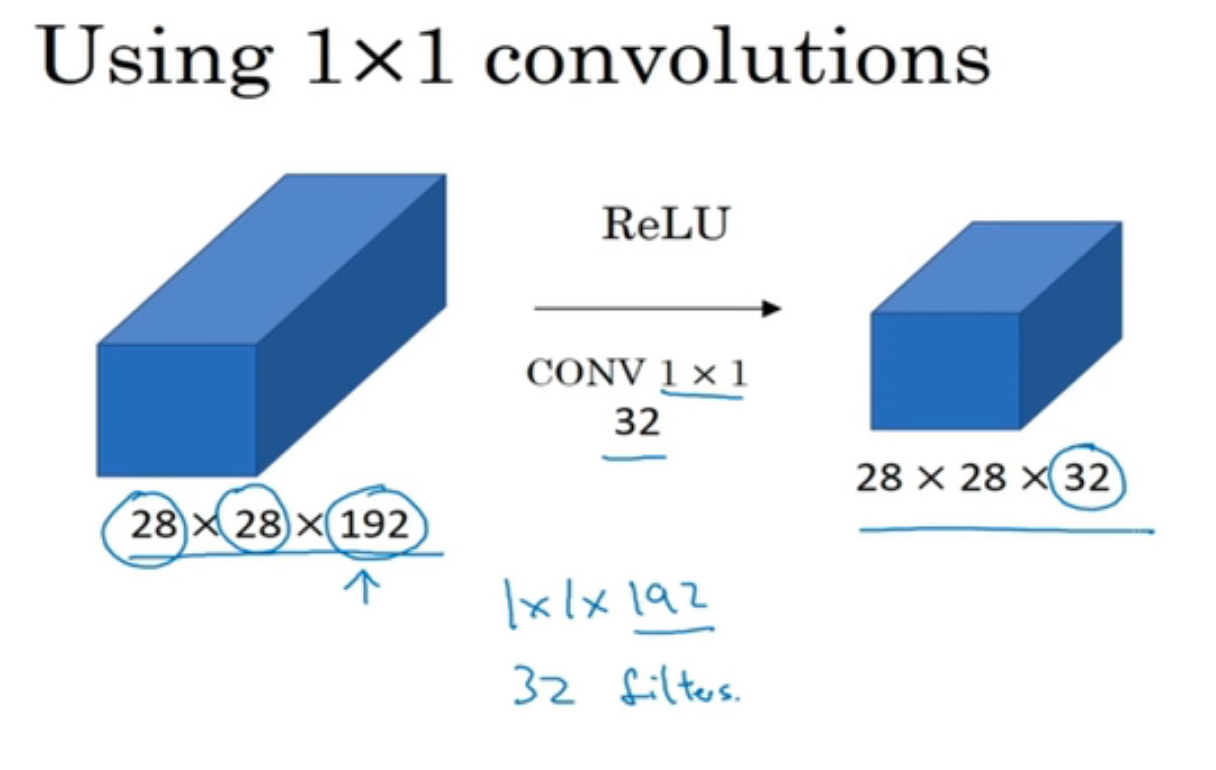
增加非线性
why?

跨通道信息交互

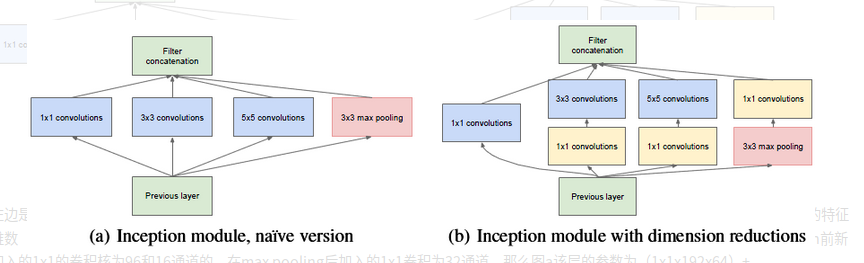
Inception Network
ref:
https://zhuanlan.zhihu.com/p/40050371
https://blog.csdn.net/a1154761720/article/details/53411365
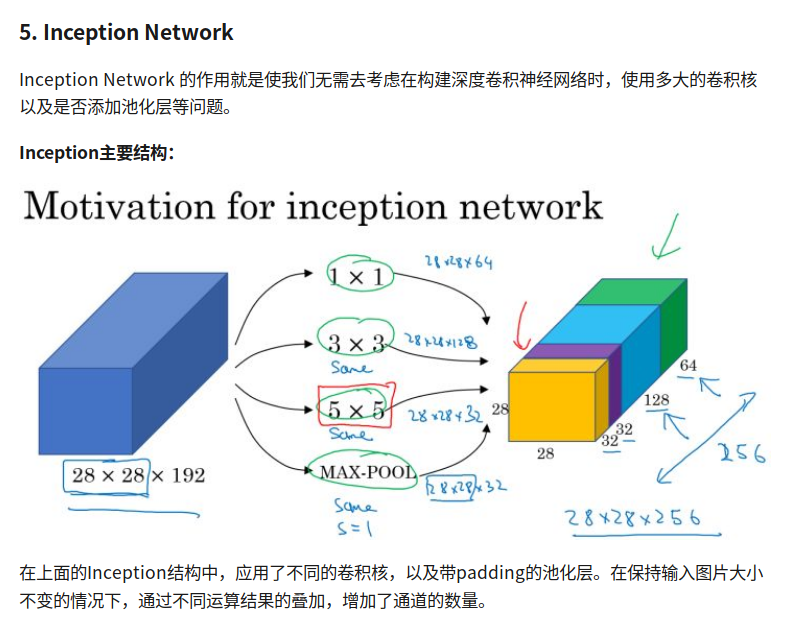
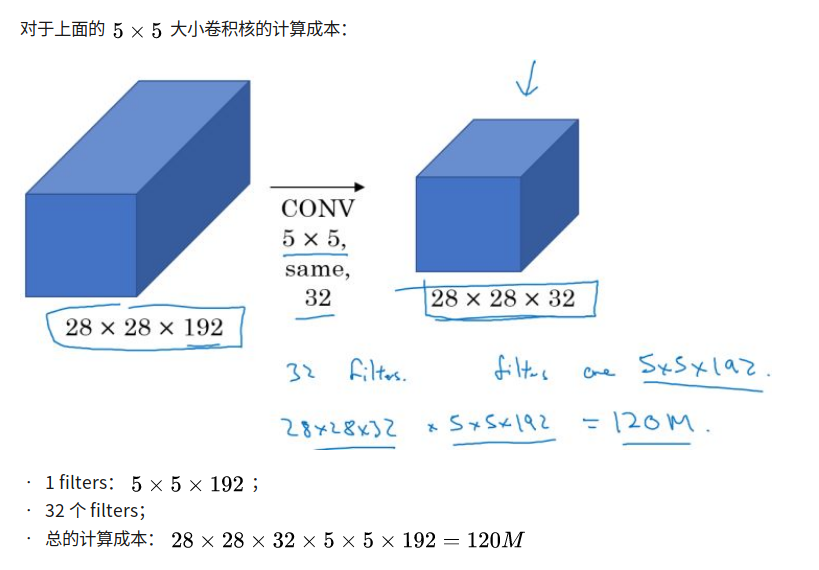
compute cost
filter的第三个通道数目 == input feature map的第三个通道数目
1 | 结果参数 = 输入层 HxWx卷积核个数 |
bottleneck layer
inception network
google net
1x1convolution 能够有效减少参数数量,加快训练
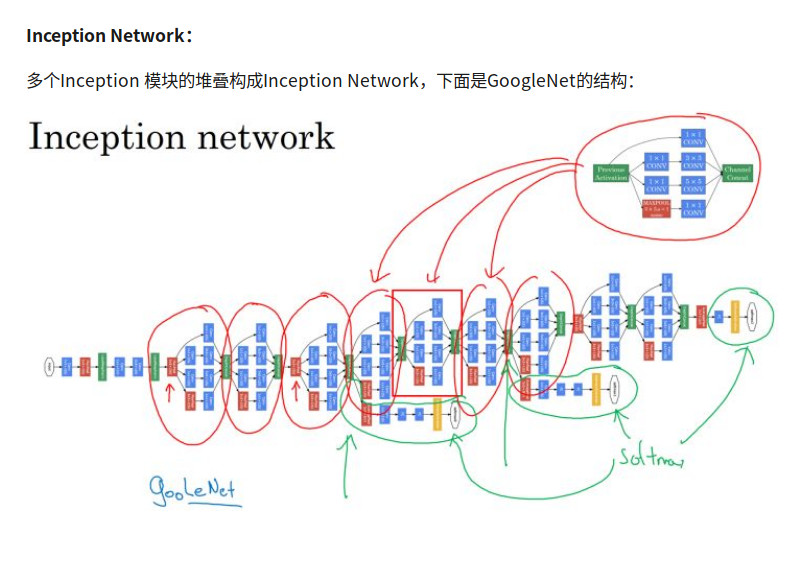
可以观察到有一些旁路也输入到softmax中,因为hidden layer有时候的预测效果也不错,这么做可以防止过拟合
Transfer Learning
小数据集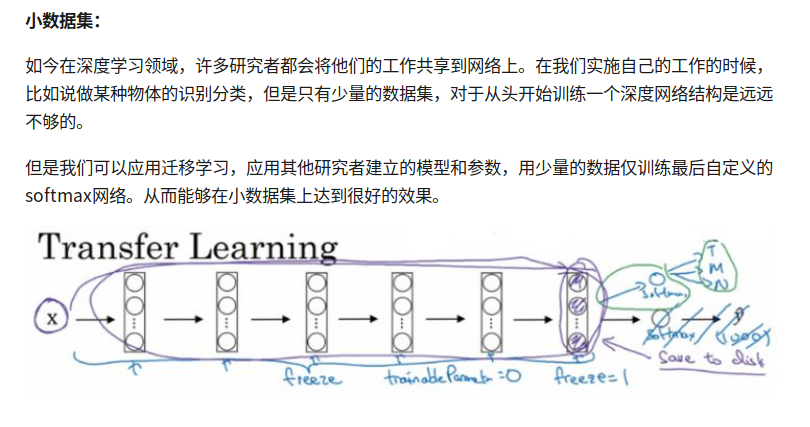
大数据集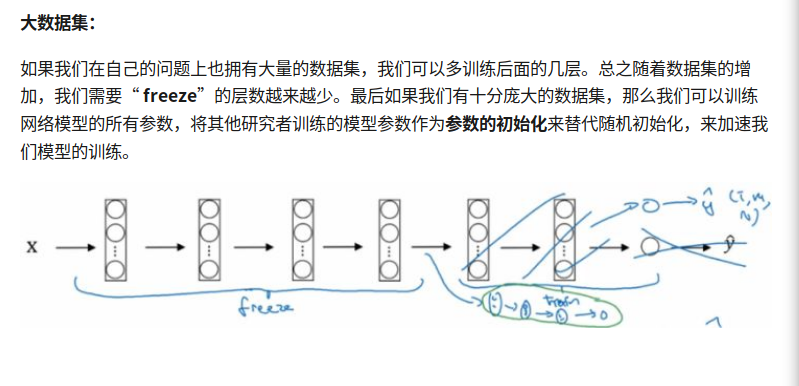
数据扩充

多CPU多线程实现