为什么要卷积?
for big size picture, the input scale would be very large. eg. an 10001000 size picture,
after flattening its features , you can get a vector as (31000*1000,1) = (3million ,1)
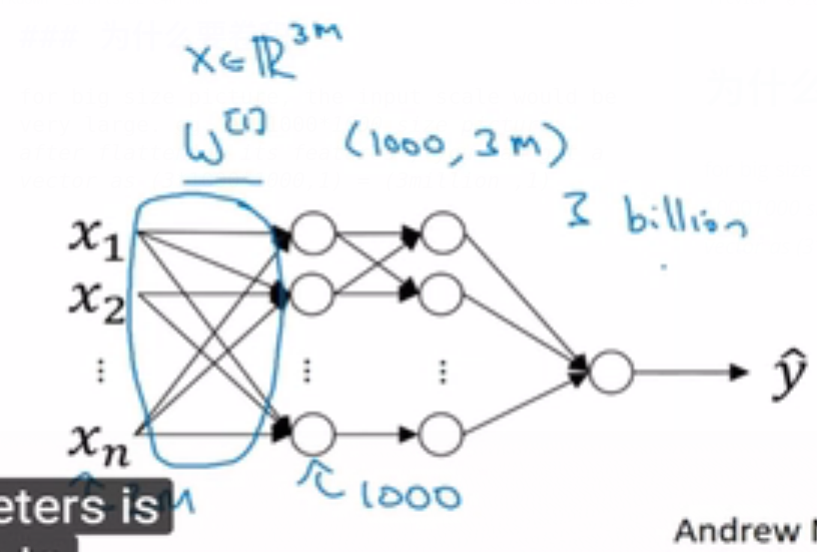
如果hidden layer只有1000层,那么W1 的输入大小是(1000,3m)
因为z(1000,1) = W1(1000,3M)*X(3M,1)+b
边缘检测
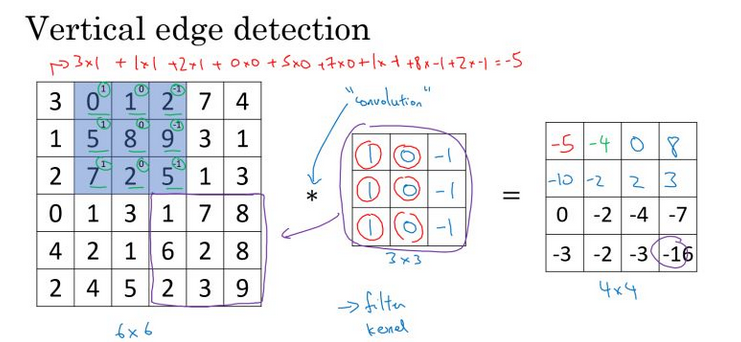
用一个33大小的卷积核对一张66大小的图片进行卷积运算,最终得到一个4x4的图片
python:conv_forward
tf.nn.conv2d
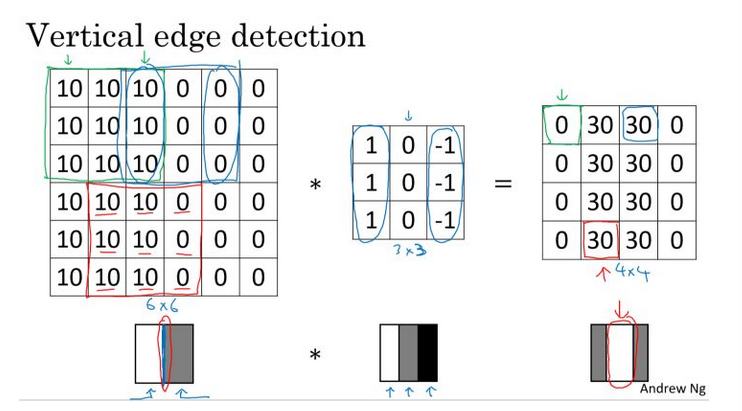
边缘检测原理
用垂直边缘filter,可以明显吧边缘和非边缘区区分出来。
多种边缘检测
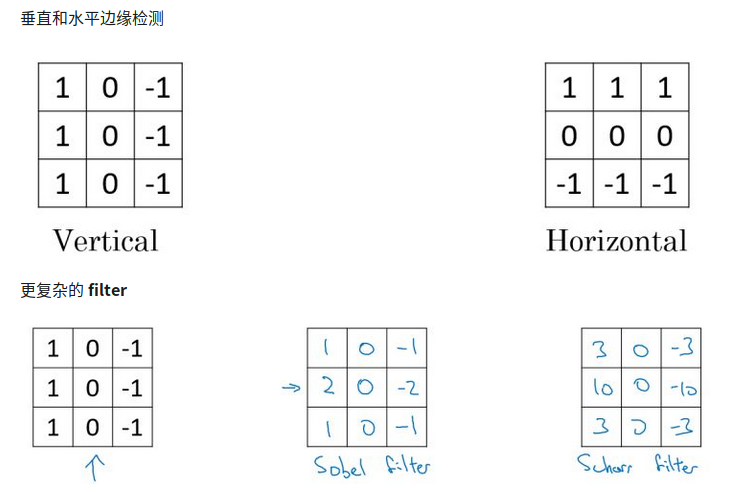
我们可以直接把filter中的数字直接看作是需要学习的参数
在nn中通过反向传播算法,学习到相应于目标结果的filter,然后把其应用在整个图片上,输出其提取到的所有有用的特征。
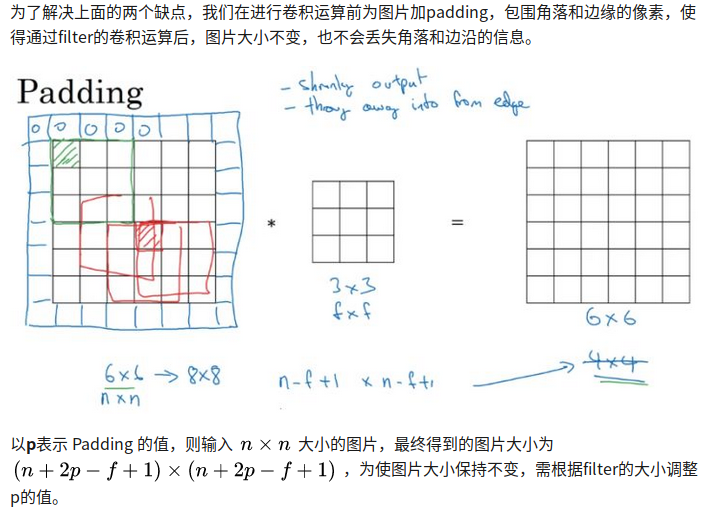
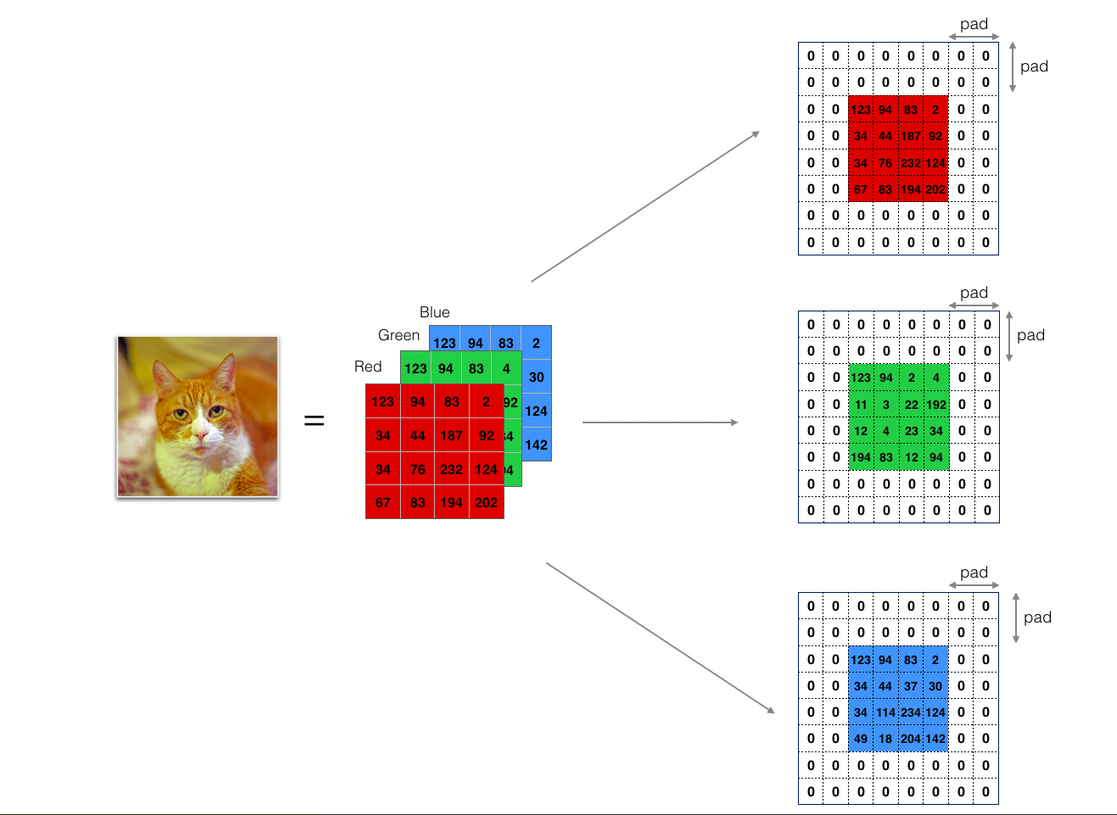
padding
从上面注意到每次卷积操作,图片会缩小。

所以我们要在卷积之前,为图片加padding,包围角落和边缘的像素,使得通过filter的卷积运算后,图片大小不变,也不会丢失角落。
valid/Some 卷积
Valid: no padding
nxn –>(n-f+1)x(n-f+1)
Same: padding
输出和输入图片的大小相同
p = (f-1)/2,在CV中,一般来说padding的值位奇数
N+2P-F+1 = N ,SO p = (F-1)/2
卷积步长(stride)
stride=1,表示每次卷积运算以一个步长进行移动。

立体卷积

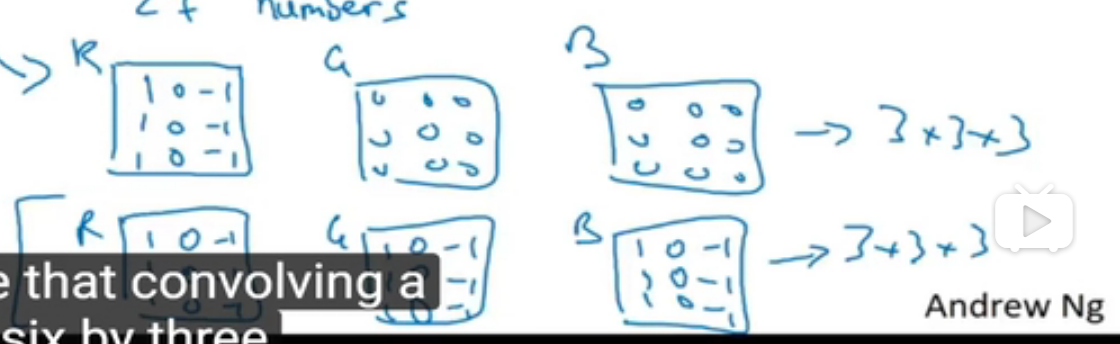
第一行表示只检测红色通道的垂直边缘
第二行表示检测所有通道垂直边缘
卷积核第三个维度大小等于图片通道大小
多卷积
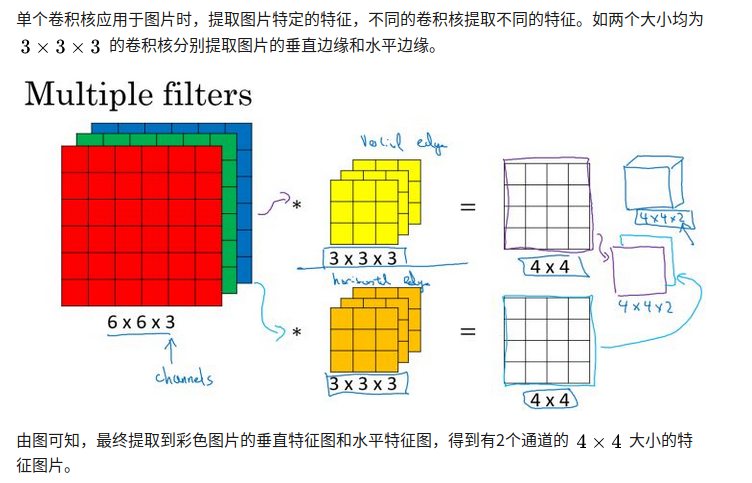
上图意思是把检测垂直和水平边缘的两个图片叠成两层。

单层卷积网络
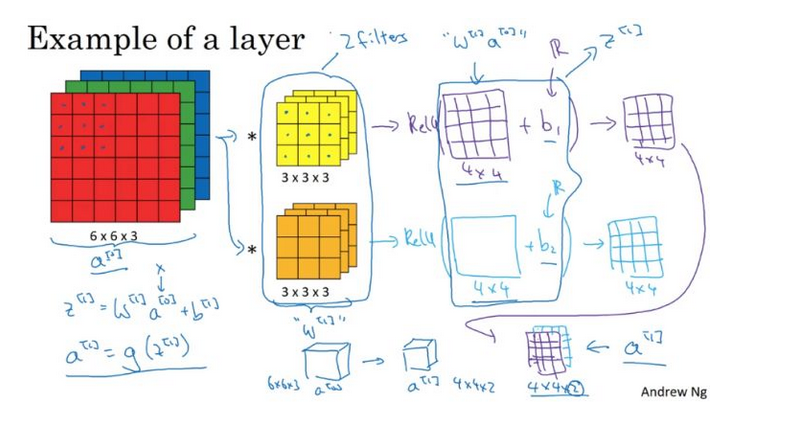
与普通神经网络单层前向传播类似,卷机神经网络也是先由权重和bias做线性运算,然后得到结果在输入到一个激活函数中。

对应上图a[0]表示图片层(nn3)
w[1]对应卷积核(ff3)
a[1] 对应下一层(4x4x2)
单层卷积参数个数
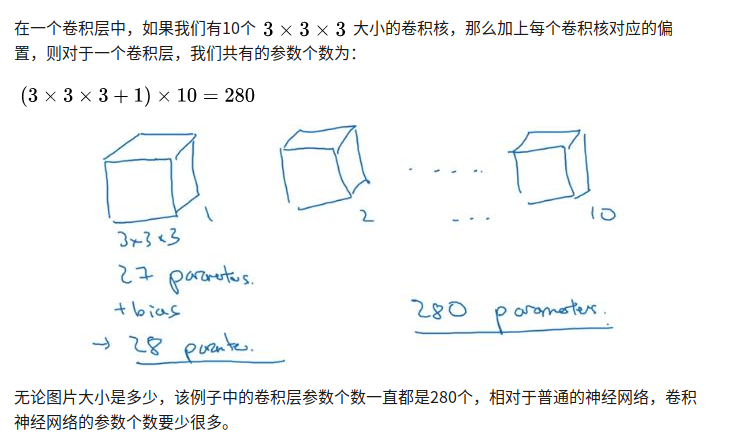
不受图片大小影响
标记

f[l] 卷积核大小
卷积核第三个维度大小等于输入图片通道数
而权重就是卷积核大小×卷积核个数,卷积核个数就是输出层的通道数目
激活值大小就是下一层输出层的大小: nH X nW X nC
简单卷积网络

最后得到的7x7x40,一共1960个参数,就是最后输入激活函数的所有参数
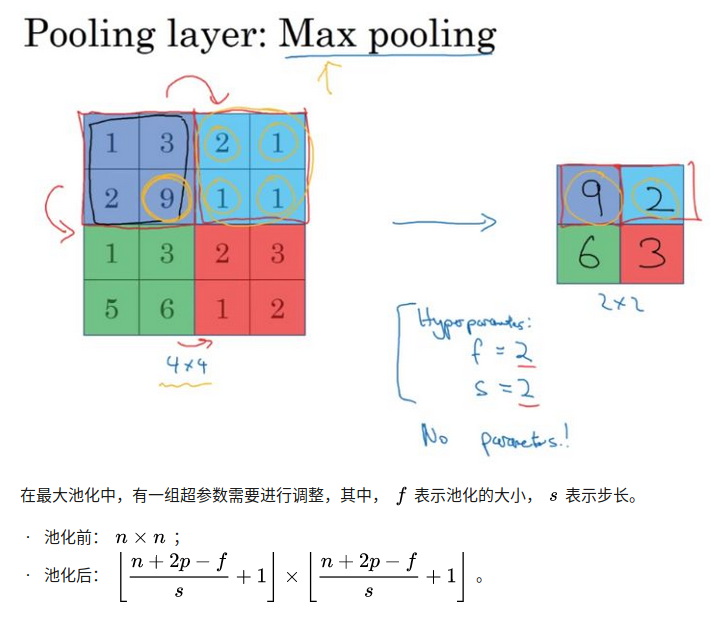
池化层
最大池化(max pooling)
把前一层得到的特征图进行池化减小,仅由当前小区域内的最大值来代表最终池化后的值。
平均池化
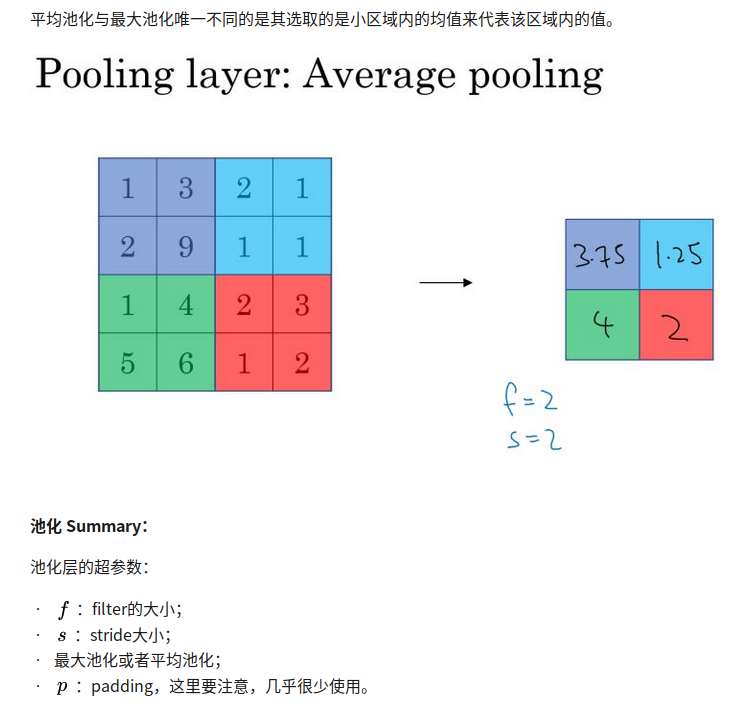
池化只需要设置好超参数,没有要学习的参数
总结
CNN的最大特点在于卷积的权值共享结构,可以大幅减少神经网络参数量,防止过拟合的同时又降低了神经网络模型的复杂度。
CNN通过卷积的方式实现局部链接,得到图片的参数量只跟卷积核的大小有关,一个卷积核对应一个图片特征,每一个卷积核滤波得到的图像就是一类特征的映射。
也就是说训练的权值数量只与卷积核大小与数量有关,但注意的是隐含层节点数量没有下降,隐含节点的数量只与卷积的步长有关,如果步长为1,那么隐含节点数量与输入图像像素数量一致。如果步长为5,那么每5x5个像素才需要一个隐含节点。
再总结,CNN的要点就是
1.局部连接
2.权值共享
3.池化层的降采样
其中1与2降低了参数量,训练复杂度下降并减轻过拟合。
同时权值共享赋予了卷积网络对平移的容忍性。
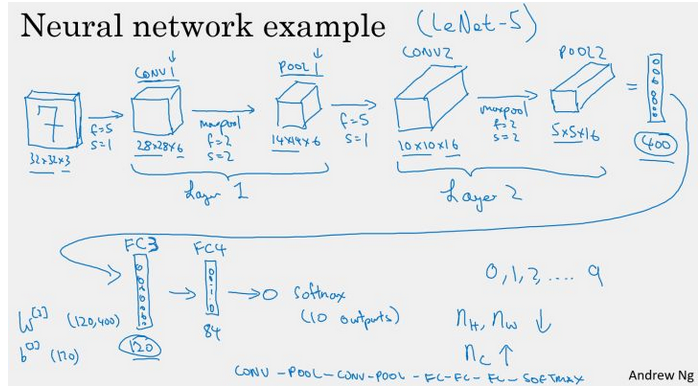
随着nn层数增加,提取的特征图片大小将会减小,但是同时间通道数量会增加
为什么使用CNN?
1.参数少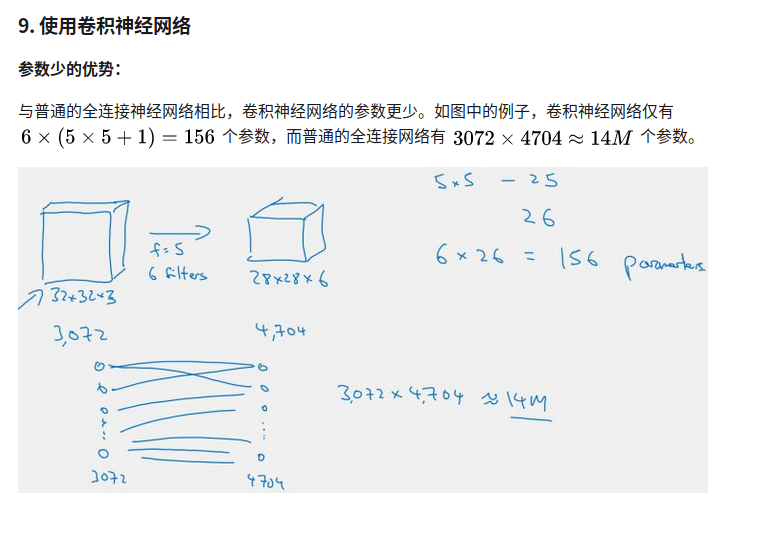
2.参数共享&链接的稀疏性
参数共享指一个卷积核可以有多个不同的卷积核,而每一个卷积核对应一个滤波后映射出的新图像,同一个新图像的每一个像素都来自完全相同的卷积核。

implementation
zero padding
benefits

1 |
|
forward convolution
1 | def conv_single_step(a_slice_prev, W, b): |
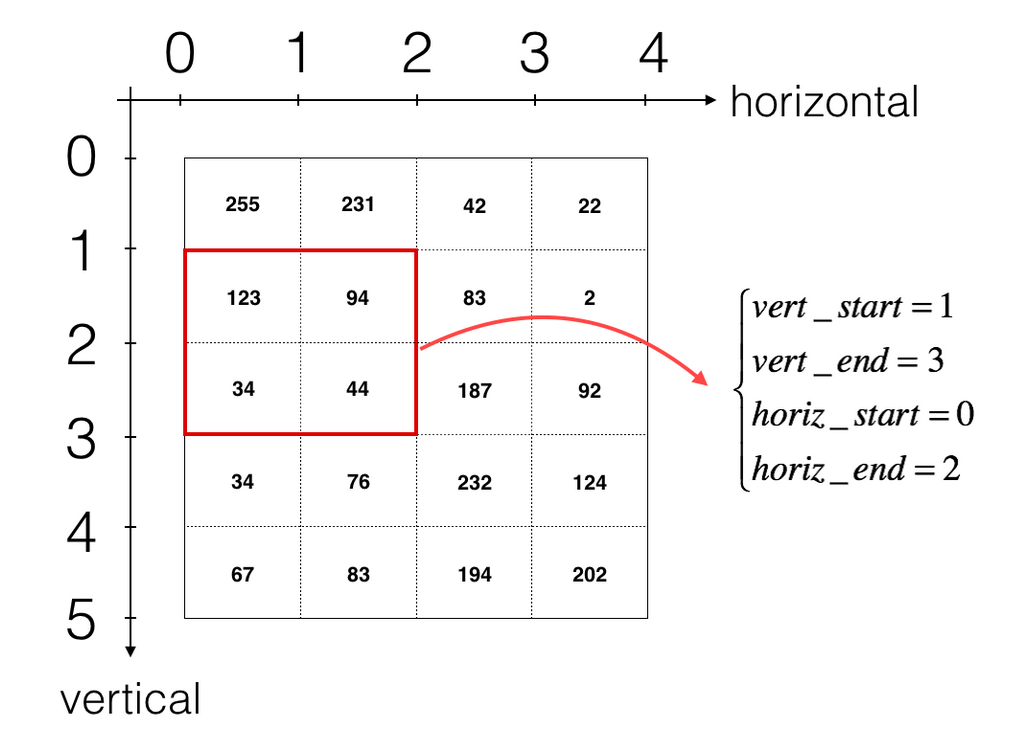
define a slice
1 | def conv_forward(A_prev, W, b, hparameters): |