Hyperparameter tuning
don’t use grid search
because you do not know which hyperparameters
matters most!

instead,use randomly chosen hyperparameter
coarse to fine
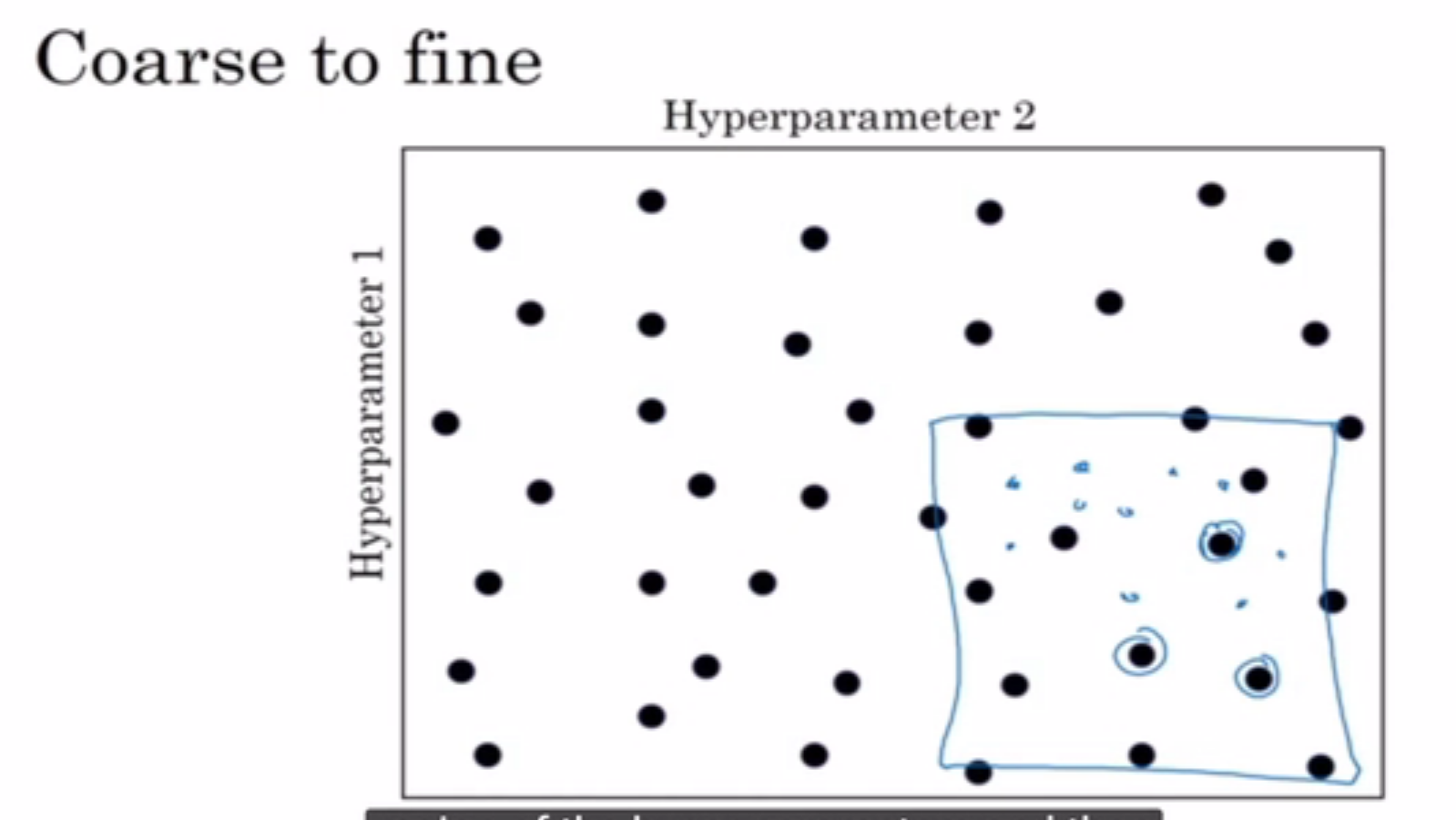
如果某些临近的参数效果不错,那么把选择的范围缩小。
scale for params
对数scale


如果beta 为0.9,当beta从0.9变成0.9005的时候,变化很小
但是如果beta很接近于1,当beta从0.999->0.9995的时候,就会变化很大
panda / caviar strategy
given the computational resources you have,if limited,then you can only watch over one model,so check its cost 每隔一段时间,if any problems occurs, stop and return to previous state.
while if you have enough computational resources,then you can watch out various models
at one time,and choose the best one.
Batch Normalization
实质是对hidden units做normalization

https://towardsdatascience.com/batch-normalization-in-neural-networks-1ac91516821c

fitting batch norm to nn
每个epoch对隐藏层做一次batch normalization
back propagate 的时候不用考虑db,因为在normalize的时候Z_TILDA = (Z-mean)/(sqrt of variance) 会把常数项减掉
why batch norm work?

当你训练一个模型,得到一个x->y的映射之后,如果预测数据分布发生了变化,你需要重新训练你的模型。这叫做 covariate shift
例如你训练的都是黑猫图片,如果你用这个模型来测试彩色猫的图片,那么效果肯定会不好。
而对hidden units 做normalization (batch norm),即使前面输入数据x发生变化,那么对后面层的影响将会变小很多,因为每一层都’constrained to have the same mean and variance’ 提升了神经网络应付不同输入的健壮性。

1 | Consequently, batch normalization adds two trainable parameters to each layer, so the normalized output is multiplied by a “standard deviation” parameter (gamma) and add a “mean” parameter (beta). In other words, batch normalization lets SGD do the denormalization by changing only these two weights for each activation, instead of losing the stability of the network by changing all the weights. |
softmax layer
In mathematics, the softmax function takes an un-normalized vector, and normalizes it into a probability distribution.
我们已经知道,逻辑回归可生成介于 0 和 1.0 之间的小数。例如,某电子邮件分类器的逻辑回归输出值为 0.8,表明电子邮件是垃圾邮件的概率为 80%,不是垃圾邮件的概率为 20%。很明显,一封电子邮件是垃圾邮件或非垃圾邮件的概率之和为 1.0。
Softmax 将这一想法延伸到多类别领域。也就是说,在多类别问题中,Softmax 会为每个类别分配一个用小数表示的概率。这些用小数表示的概率相加之和必须是 1.0。与其他方式相比,这种附加限制有助于让训练过程更快速地收敛。
softmax function
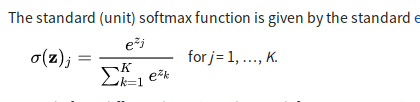
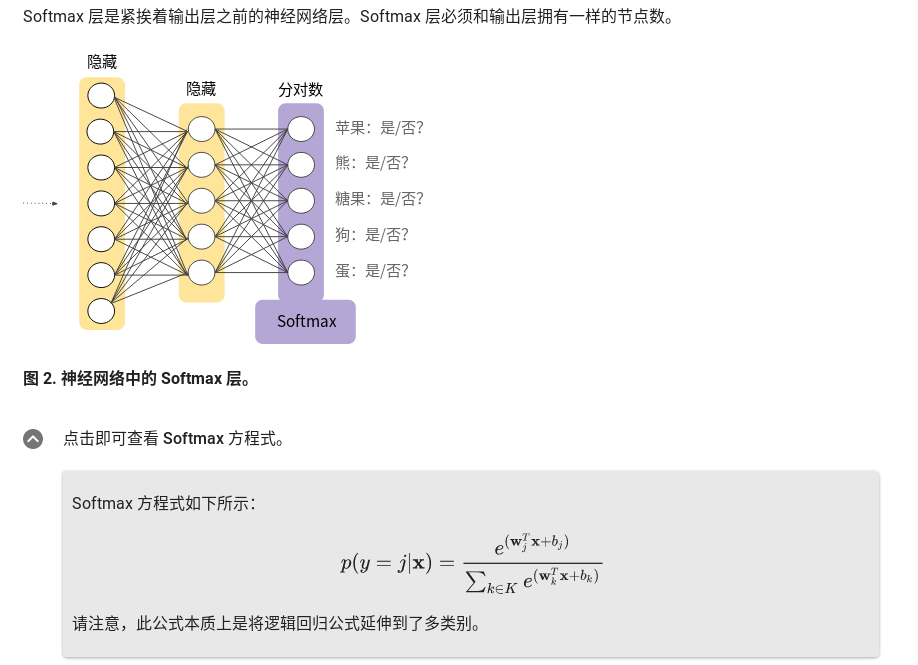
understanding softmax
