线性基函数模型
线性回归模型 y(x,w) = w0+w1x1+w2x2+…wDxD
而为了改进模型,把xi替换为非线性表达式

本实验使用了多项式基函数,高斯基函数和sigmoid基函数,以及混合型(多项式+sin正弦)而损失函数有两种选择,交叉熵函数以及均方误差,这里选择均方误差,求导比较方便。
推导
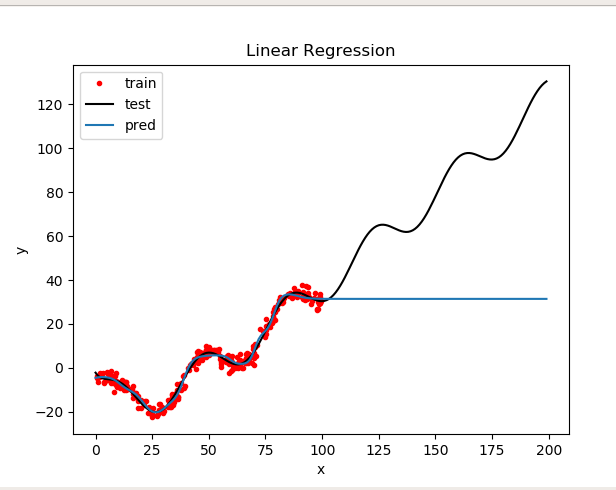
多项式基函数
y = w0+w1x1+w2x2^2 + b
λ2是L2正则化系数,可以解决过拟合问题
正则化意义:https://blog.csdn.net/jinping_shi/article/details/52433975
推导

代码实现
1 |
|
result
参数:n=2 epochs = 100000 lr 1e-7
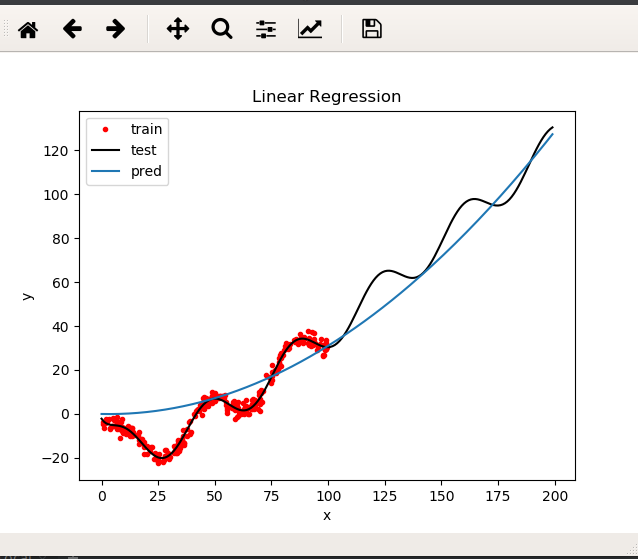
高斯基函数

推导

代码
1 | import numpy as np |
参数:f = gaussian.main(x_train, y_train,3,500000,1e-2,0)
结果
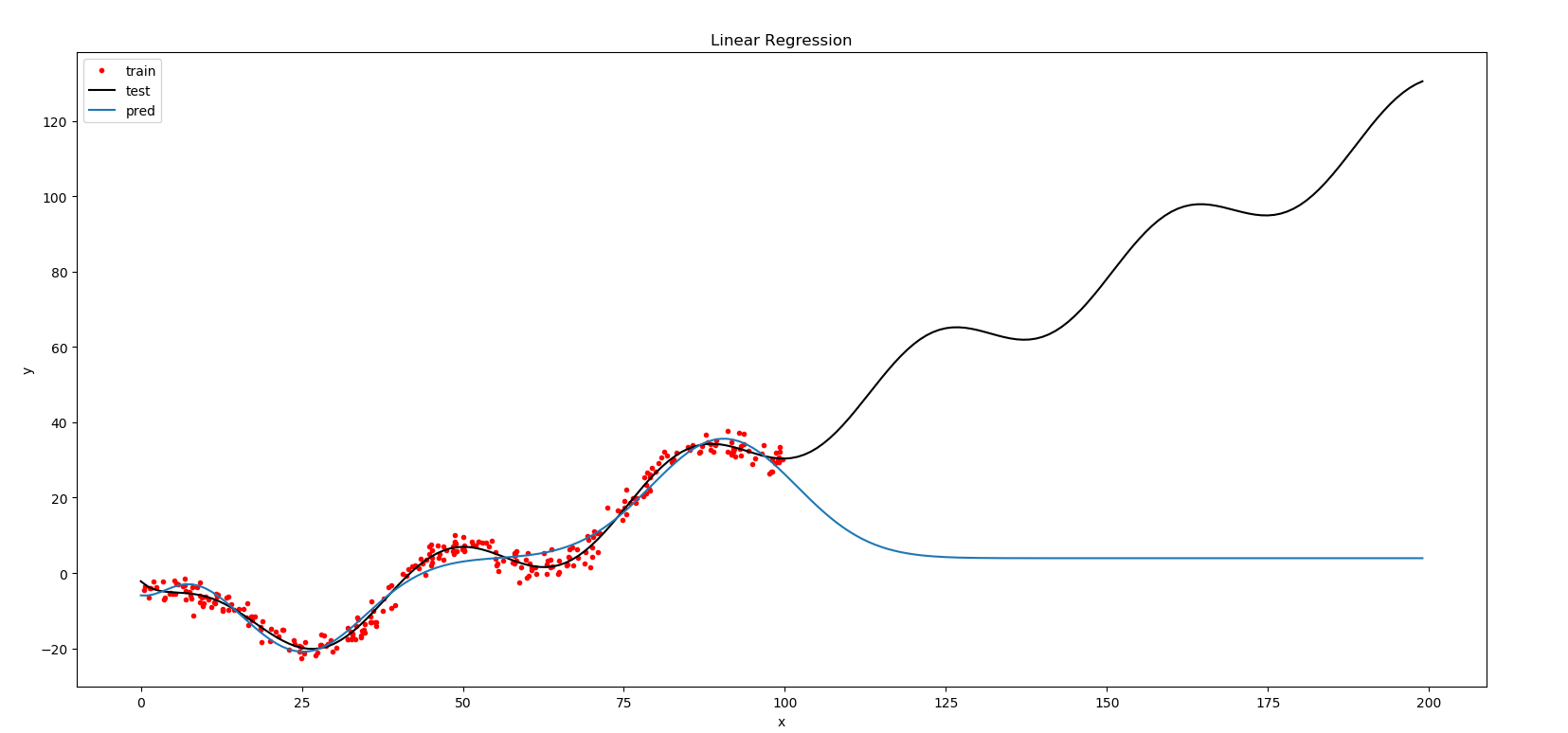
sigmoid 函数

推导
结果与高斯类似

代码
1 | import numpy as np |
参数: f = sigmoid.main(x_train, y_train,10,100000,1e-2,0)
结果
reference
https://github.com/Haicang/PRML/blob/master/lab1/Report.ipynb