
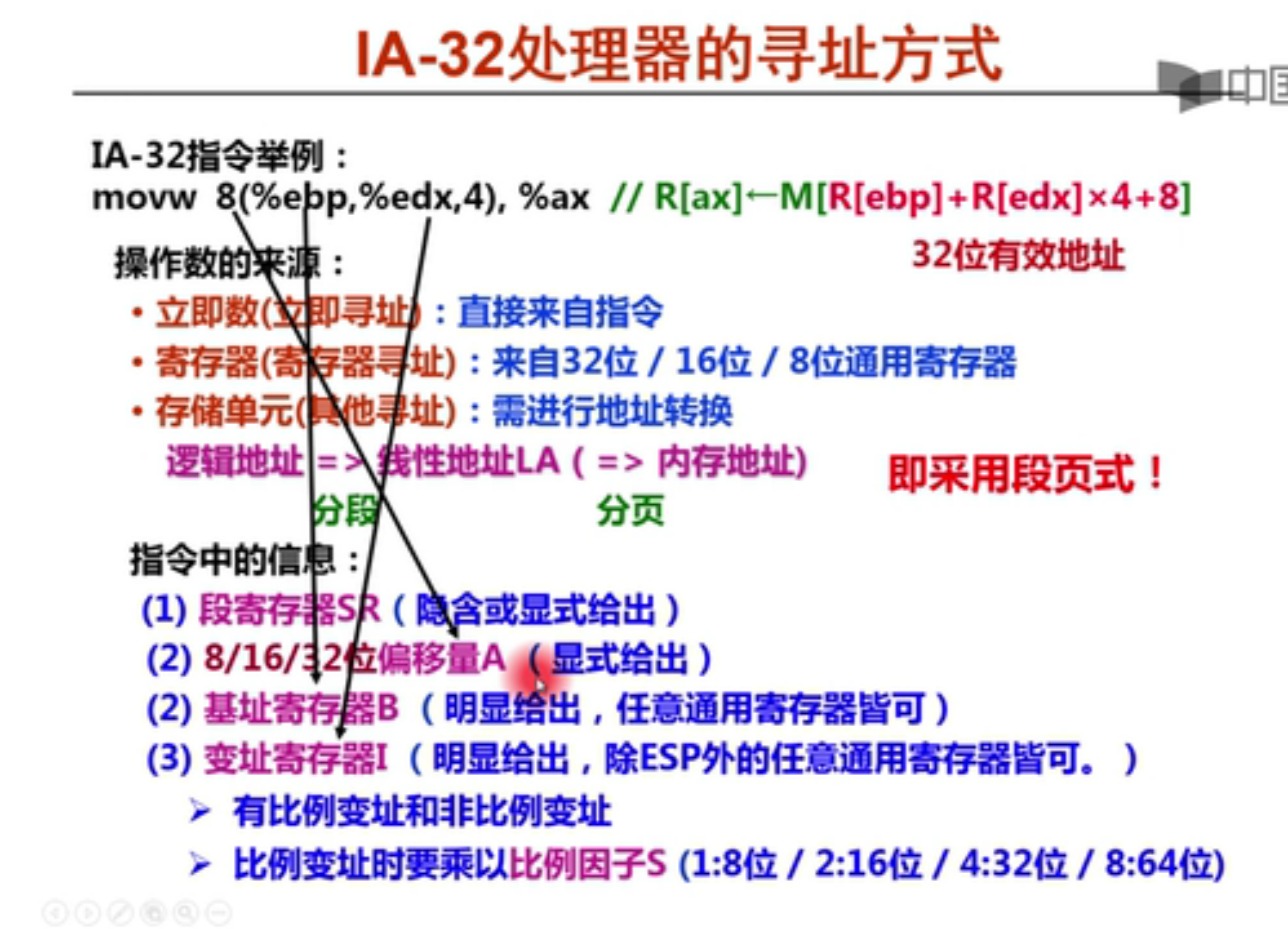
1.逻辑地址-》线性地址是 分段
2.线性地址-》内存地址是 分页
这里的8是偏移量A
%ebp是基址寄存器B,%esp是变址寄存器I,4是比例因子S
分段过程
线性地址的计算
段选择符是在上图的段寄存器里面的
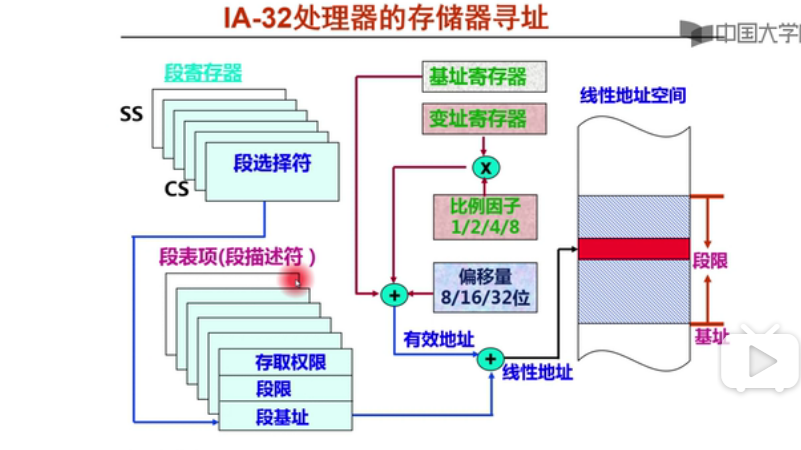
段选择符就相当于index位,分段方式中有一个”段表“(在主存),段表记录了段的长度,段开始的地方,存取权限等。
线性地址 = 段基址+有效地址
有效地址 = 基址寄存器+变址寄存器×比例因子
有效地址实际上是一个段内的偏移量,首地址+段内偏移量 = 线性地址。
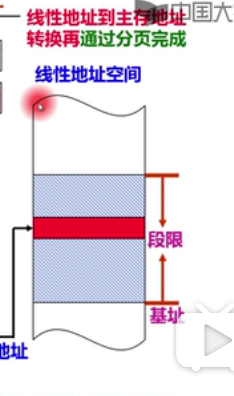
得到的线性地址再通过分页,通过页表转换为主存地址
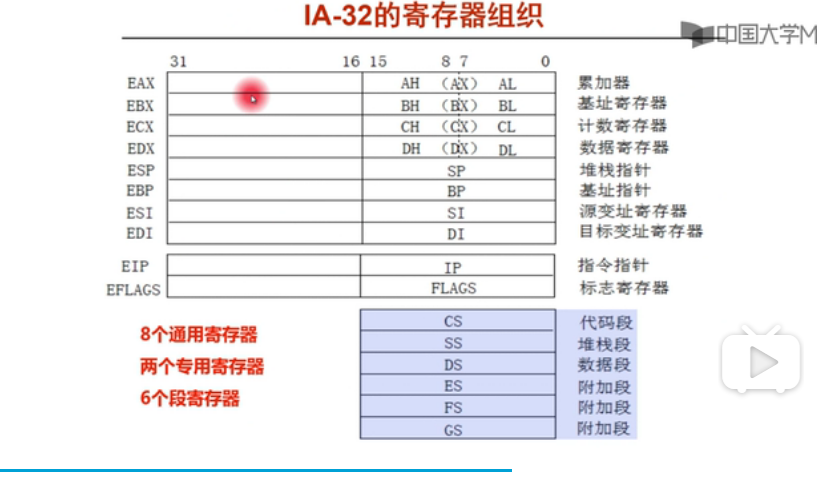
段寄存器的含义
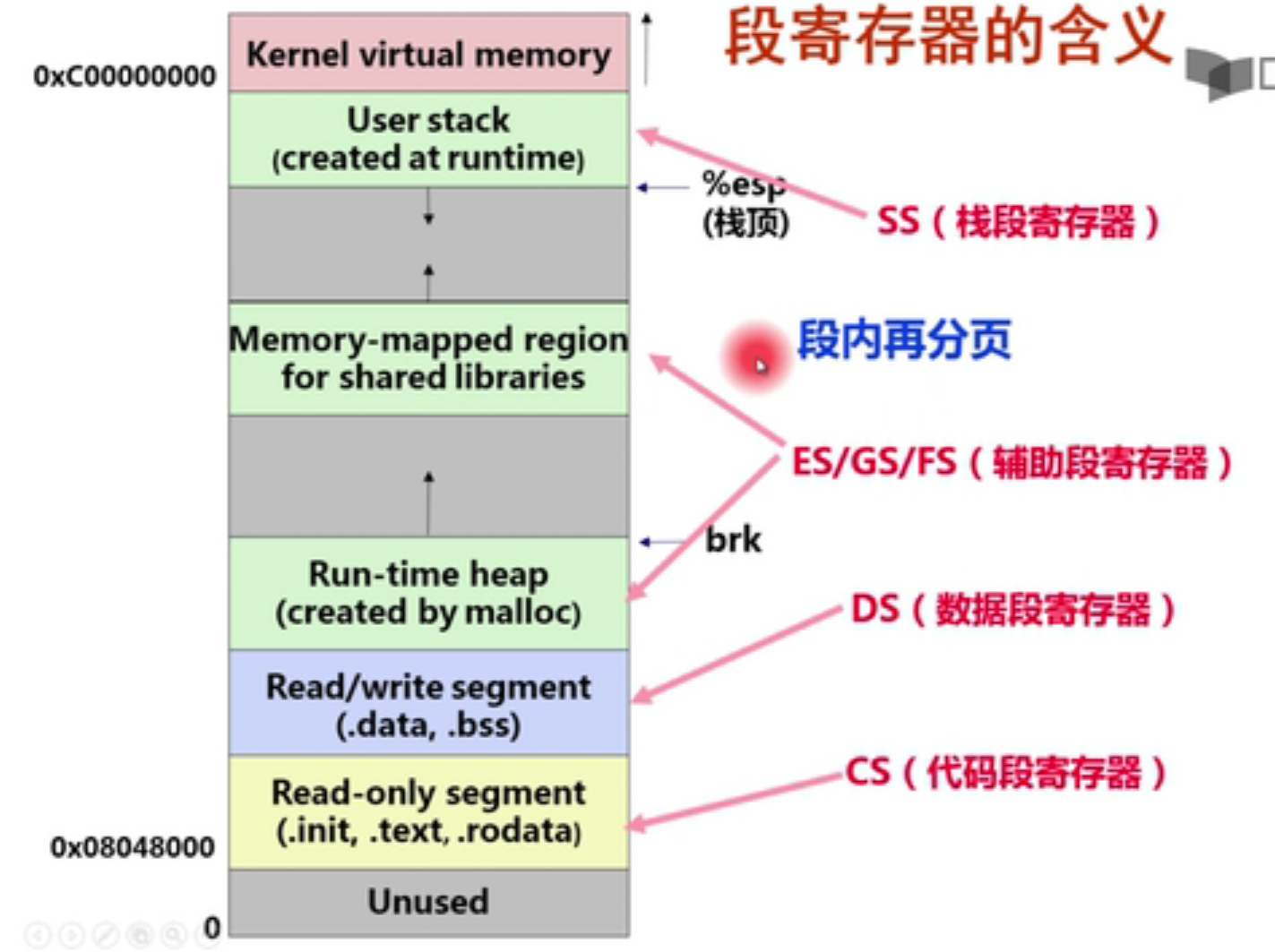
RPL: 最后两位表示管理状态(request privilege level)

段描述符和段描述符表

什么叫任务状态段?
这里的任务指的是进程,就是进程执行到某个阶段的时候,CS.SS.EIP,ESP,GPR内容等信息(代码算段,堆栈段,指令指针,栈指针,通用寄存器内容等)
中断门描述符记录了处理中断等异常处理的程序的首地址

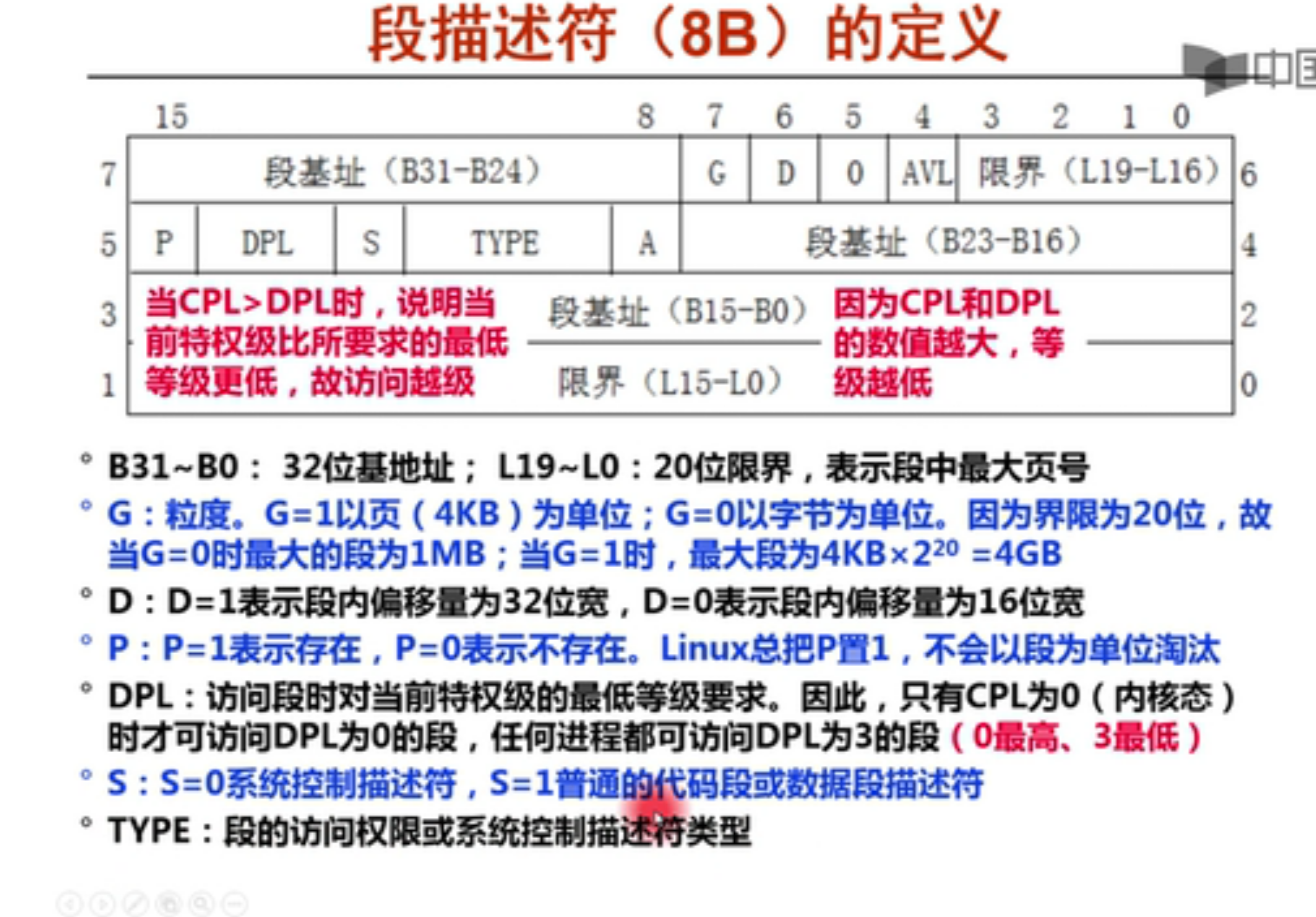
为了减少从主存中找段描述符,使用cache
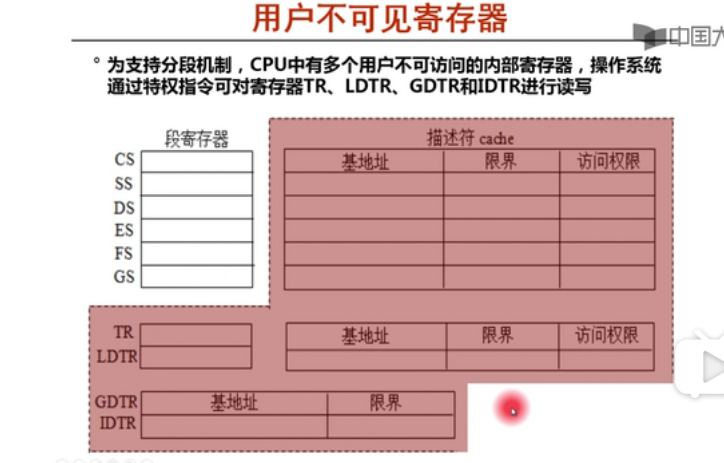

TSS描述符在进行进程切换的时候,TR里面的内容也要进行切换。
所有表的起始地址是放在GDR,而所有异常中断程序的首地址放在IDT,IDT的首地址也放在IDTR里面
1 | GDT和IDT只有一个,GDTR 和 IDTR指向各自起始的地方,根据TR取GDT中的TSS描述符的时候,GDTR给出首地址 |
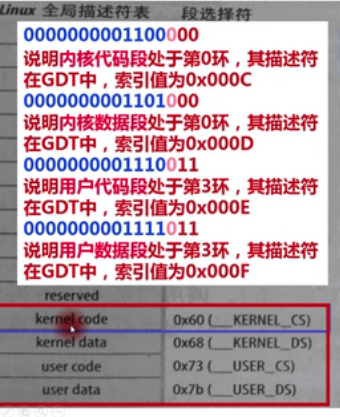
Linux的全局段描述符表
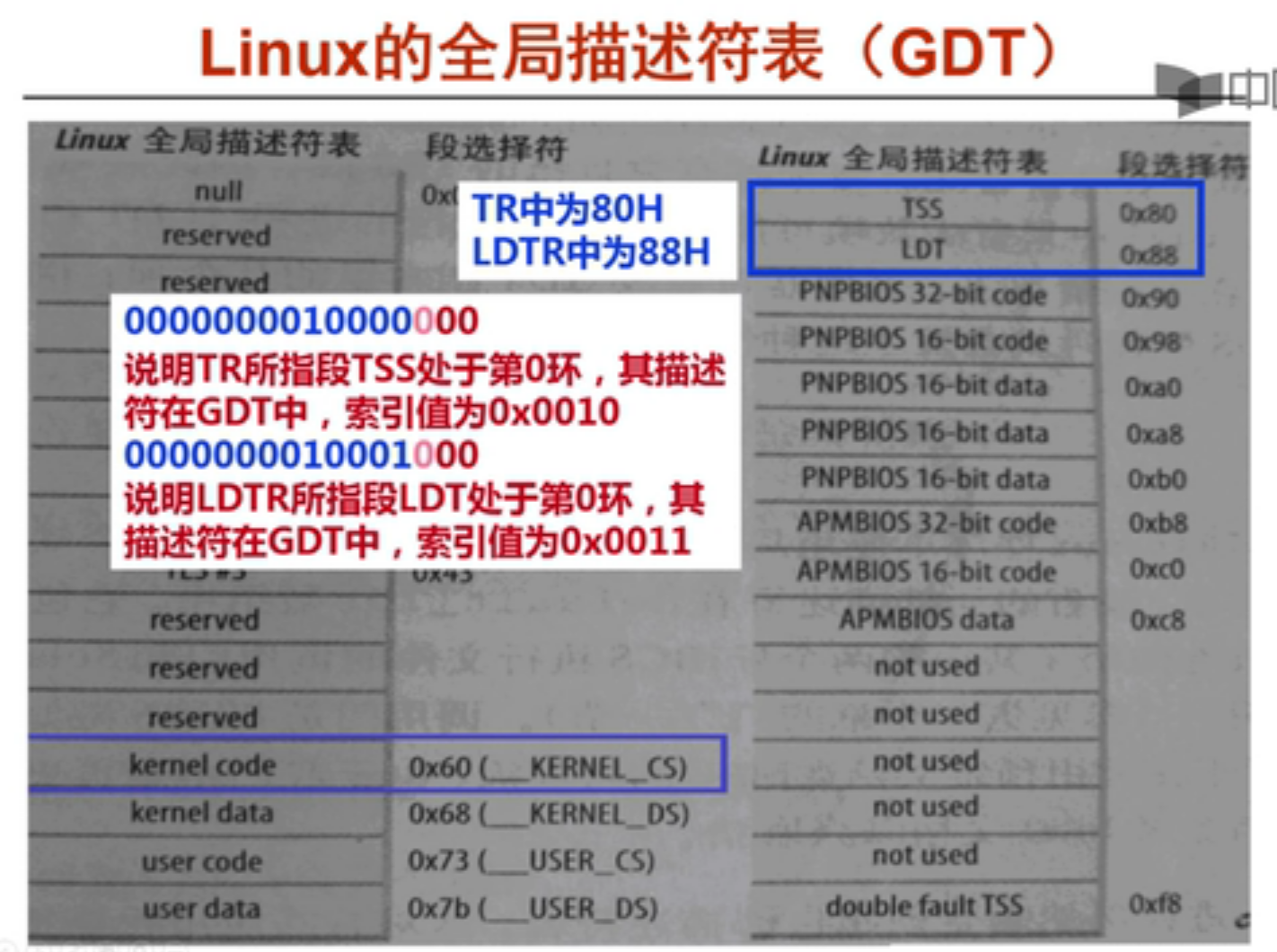
最后两位是RPL,都为0表示其在第0环,位于内核
倒数第三位表示这个描述符在GDT中,剩下的位便是索引号,
TSS索引是0x0010,即全局描述符表的第16项,LDT索引是0x0011,是第17项
因此在上上图中,操作系统会分别把0x80与0x88放在TR与LDTR中
逻辑地址向线性地址转换
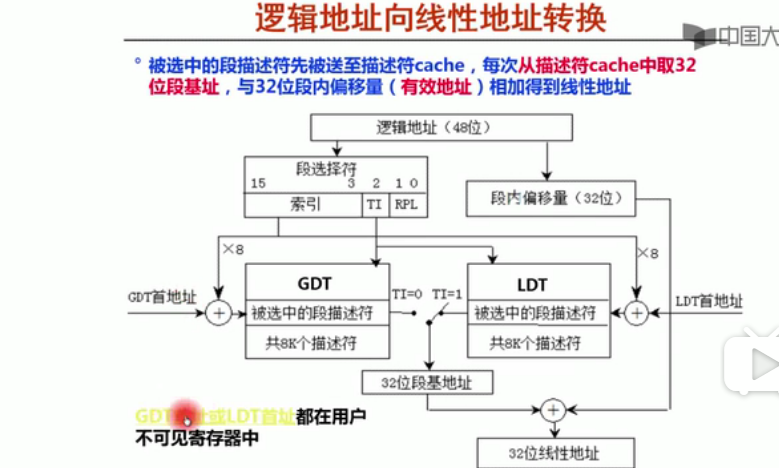
逻辑地址(48位)=》 线性地址(32位)
16位的段选择符,根据TI选择去GDT还是去LDT,其中GDT,LDT的首地址分别存储在GDTR和LDTR里面,(不可见寄存器)
段描述符 = 首地址+8×段选择符的索引
所以得到的段基地址加上段偏移量,就得到32位线性地址
段描述符只有在第一次进行访问,访问过后就放在了cache里面,所以之后求线性地址,只需要在cache里面取基地址然后相加就行
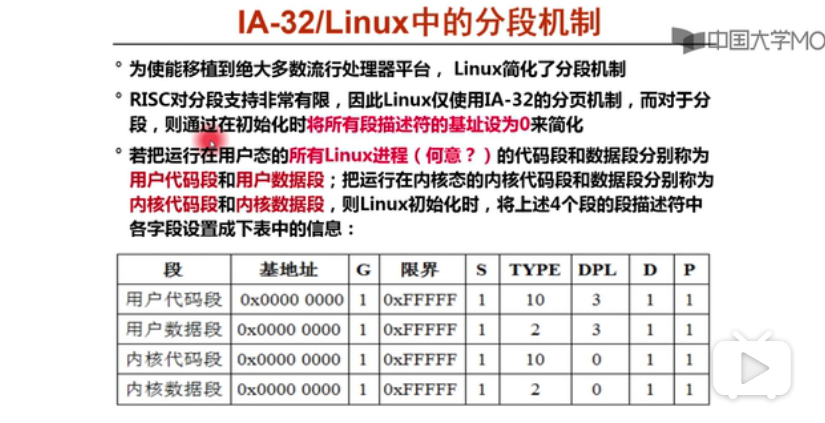
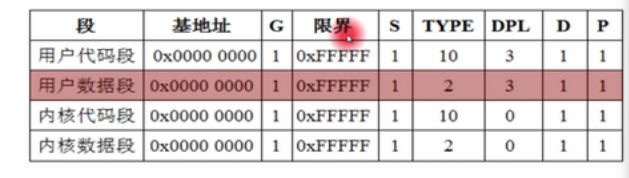
1.就是初始化时候上述4个段描述符放在GDT中
2.每个段都被初始化在0-4GB的线性地址空间中
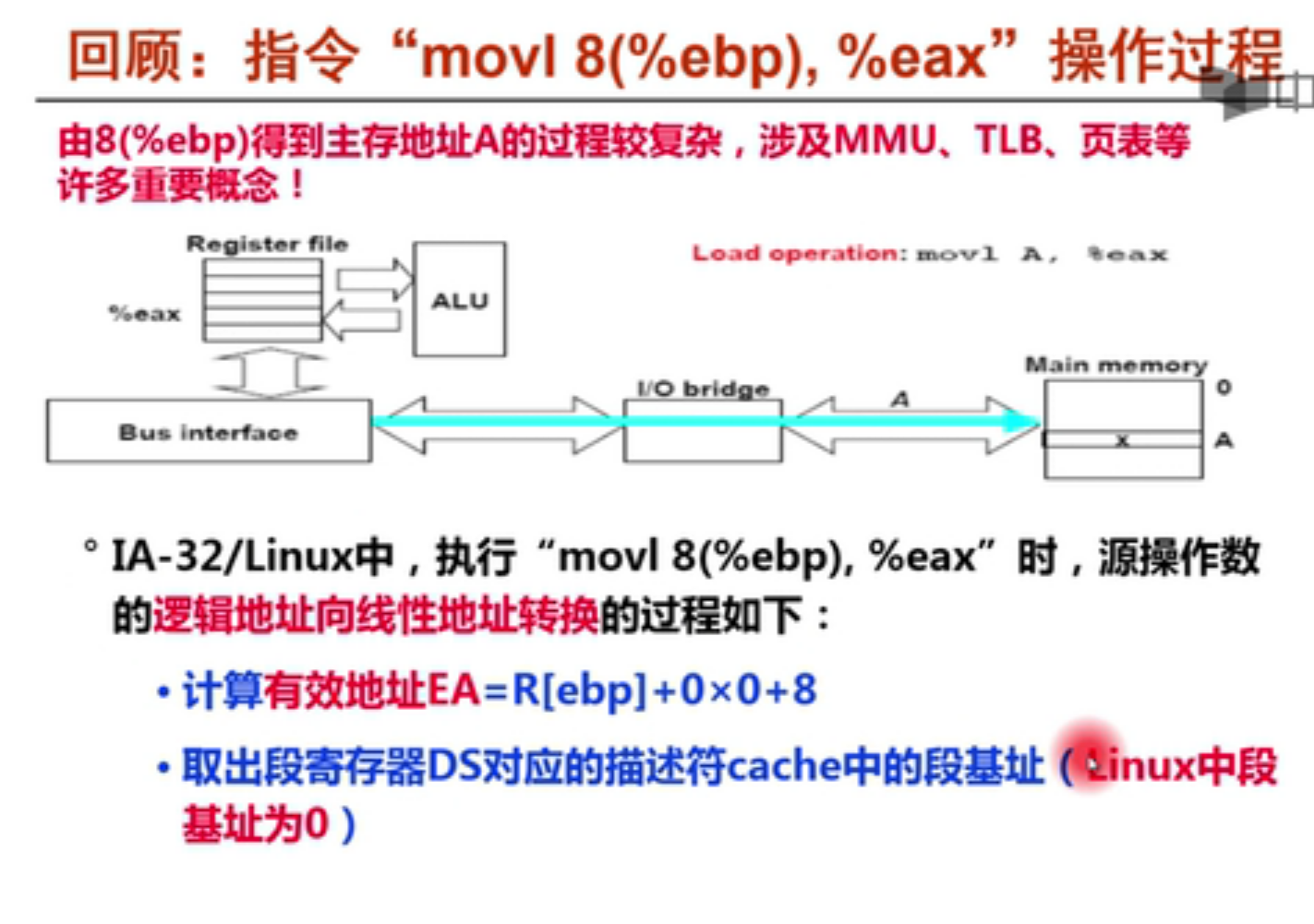
有效地址(偏移量) = 基址寄存器+变址寄存器×比例因子
所以线性地址就等于EA = 有效地址
线性地址 = 基地址+有效地址
所谓EA其实只是一个segment内的一个段内偏移量

指令的线性地址 = 代码段基地址+有效地址,而linux编译器默认了代码段基地址位0,因此指令的线性地址就等于有效地址就等于段的偏移量。
而数据的线性地址 = 数据段基地址+EA =0+ R[ECX]+R[EDX]*4
0X8048A00+(400)的16进制,注意进制的转换
分页过程(线性地址-》物理地址)
如果页大小为4KB,每个页表项占4B则理论上一个页表大小:
项个数:2^32/2^12 = 2^20 ,因此每个页表大小位4MB
比页还要大,因此采用多级页表方式来存储
—————————————————————————————————————————
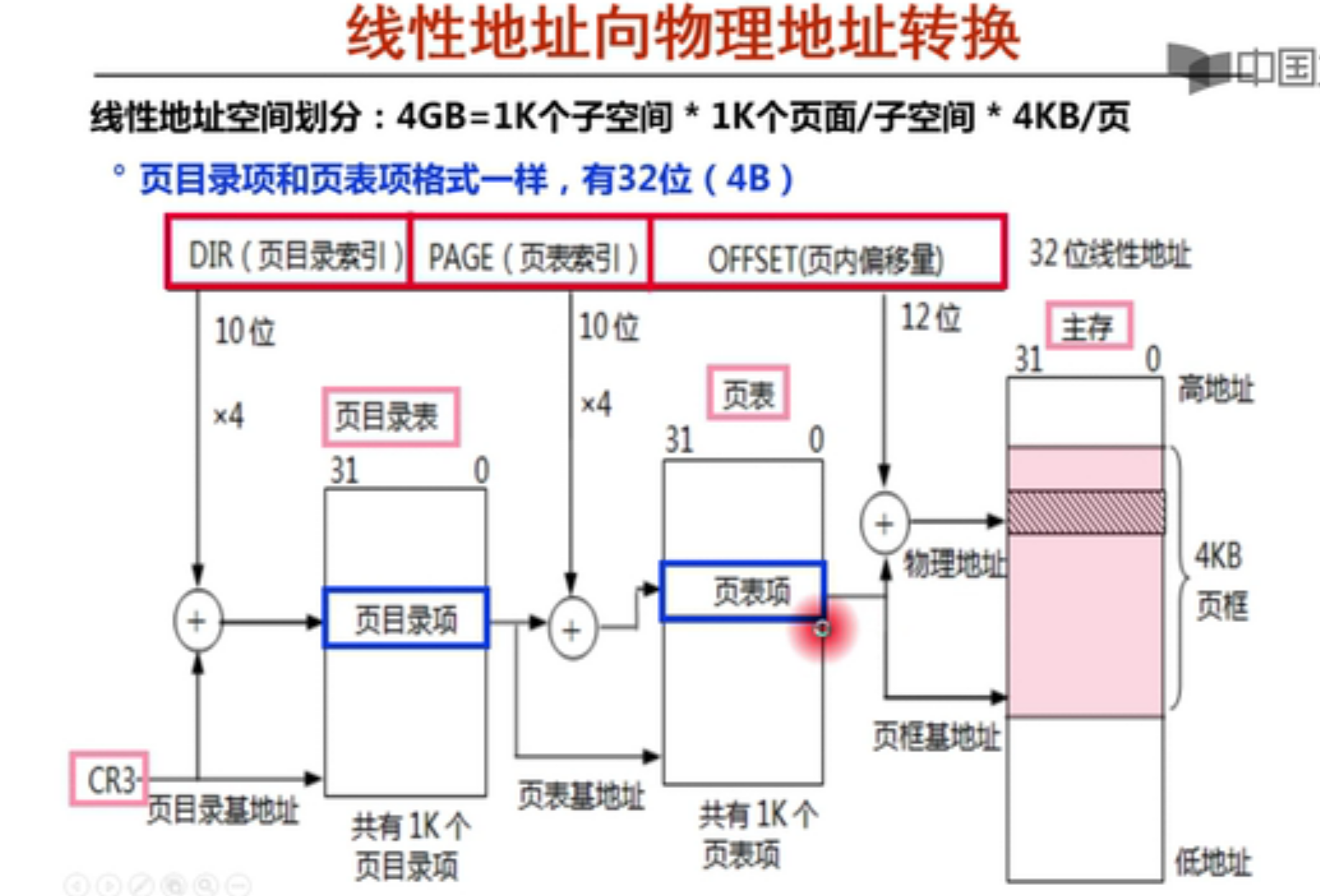
IA-32采用二级页表方式来存储

每个页表起始位置按4KB对齐意思就是每个页表起始的20位都是相同的,只有后面的12位(4KB)不同
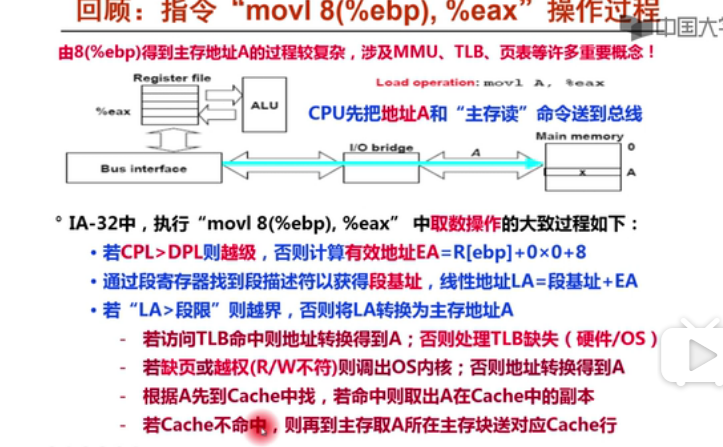
MMU 完成从逻辑地址到线性地址的过程
CPL,RPL,DPL区别与联系
1.CPL是当前进程的权限级别(Current Privilege Level),是当前正在执行的代码所在的段的特权级,存在于cs寄存器的低两位。
2.RPL说明的是进程对段访问的请求权限(Request Privilege Level),是对于段选择子而言的,每个段选择子有自己的RPL,它说明的是进程对段访问的请求权限,有点像函数参数。而且RPL对每个段来说不是固定的,两次访问同一段时的RPL可以不同。RPL可能会削弱CPL的作用,例如当前CPL=0的进程要访问一个数据段,它把段选择符中的RPL设为3,这样虽然它对该段仍然只有特权为3的访问权限。
3.DPL存储在段描述符中,规定访问该段的权限级别(Descriptor Privilege Level),每个段的DPL固定。
当进程访问一个段时,需要进程特权级检查,一般要求DPL >= max {CPL, RPL}
下面打一个比方,中国官员分为6级国家主席1、总理2、省长3、市长4、县长5、乡长6,假设我是当前进程,级别总理(CPL=2),我去聊城市(DPL=4)考察(呵呵),我用省长的级别(RPL=3 这样也能吓死他们:-))去访问,可以吧,如果我用县长的级别,人家就不理咱了(你看看电视上的微服私访,呵呵),明白了吧!为什么采用RPL,是考虑到安全的问题,就好像你明明对一个文件用有写权限,为什么用只读打开它呢,还不是为了安全!
ref:https://blog.csdn.net/better0332/article/details/3416749