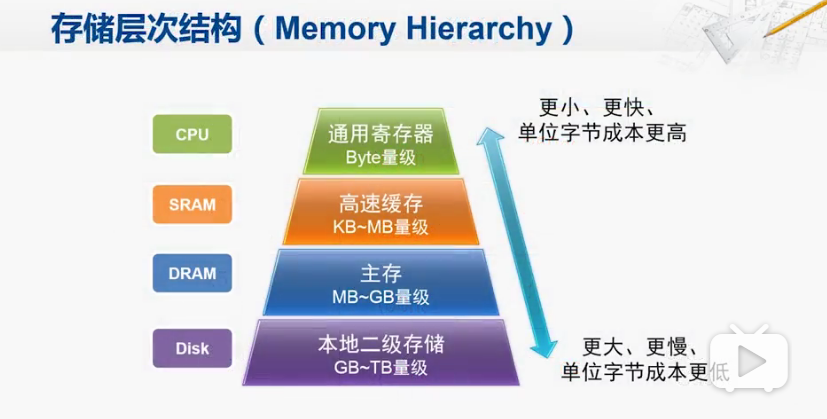
存储层次结构概况
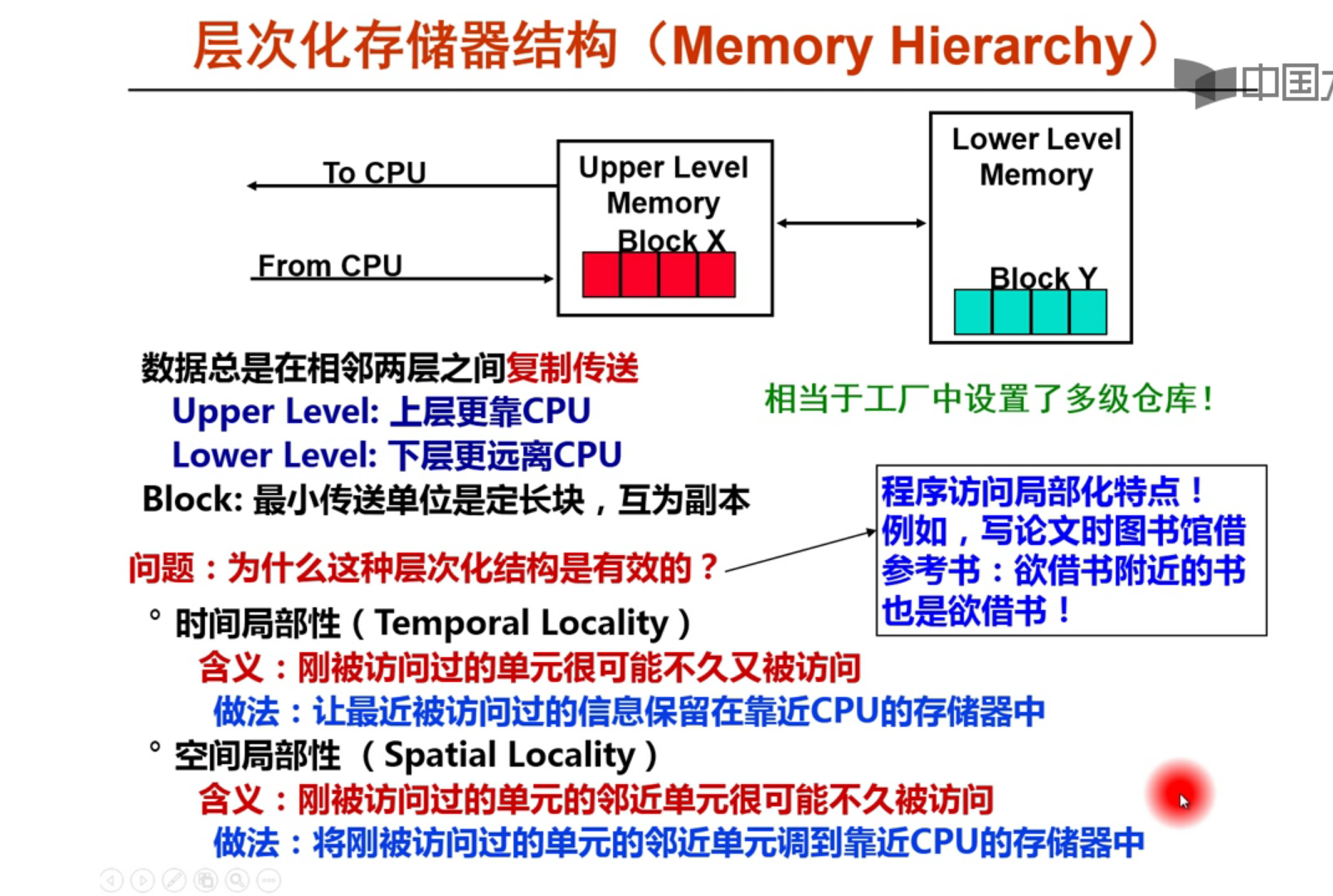
存储器的特性
1.非易失性,即断电后不会丢失数据
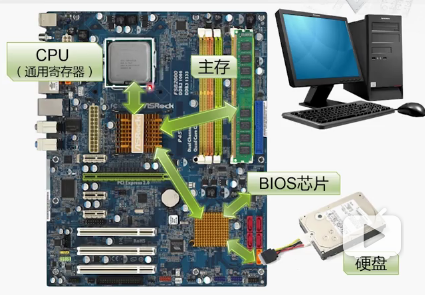
CPU和主存都是易失性,而BIOS和硬盘是非易失的
通电之后CPU通过BIOS芯片开始执行程序,把硬盘配置好后,再从硬盘读取数据搬运到主存,然后CPU才能够执行程序。
2.可读可写
3.随机访问
访问数据与其位置无关
主存与BIOS(basic input output system)能够实现随即访问数据。
但是硬盘则不是。
4.访问时间
主存速度高于硬盘访问时间
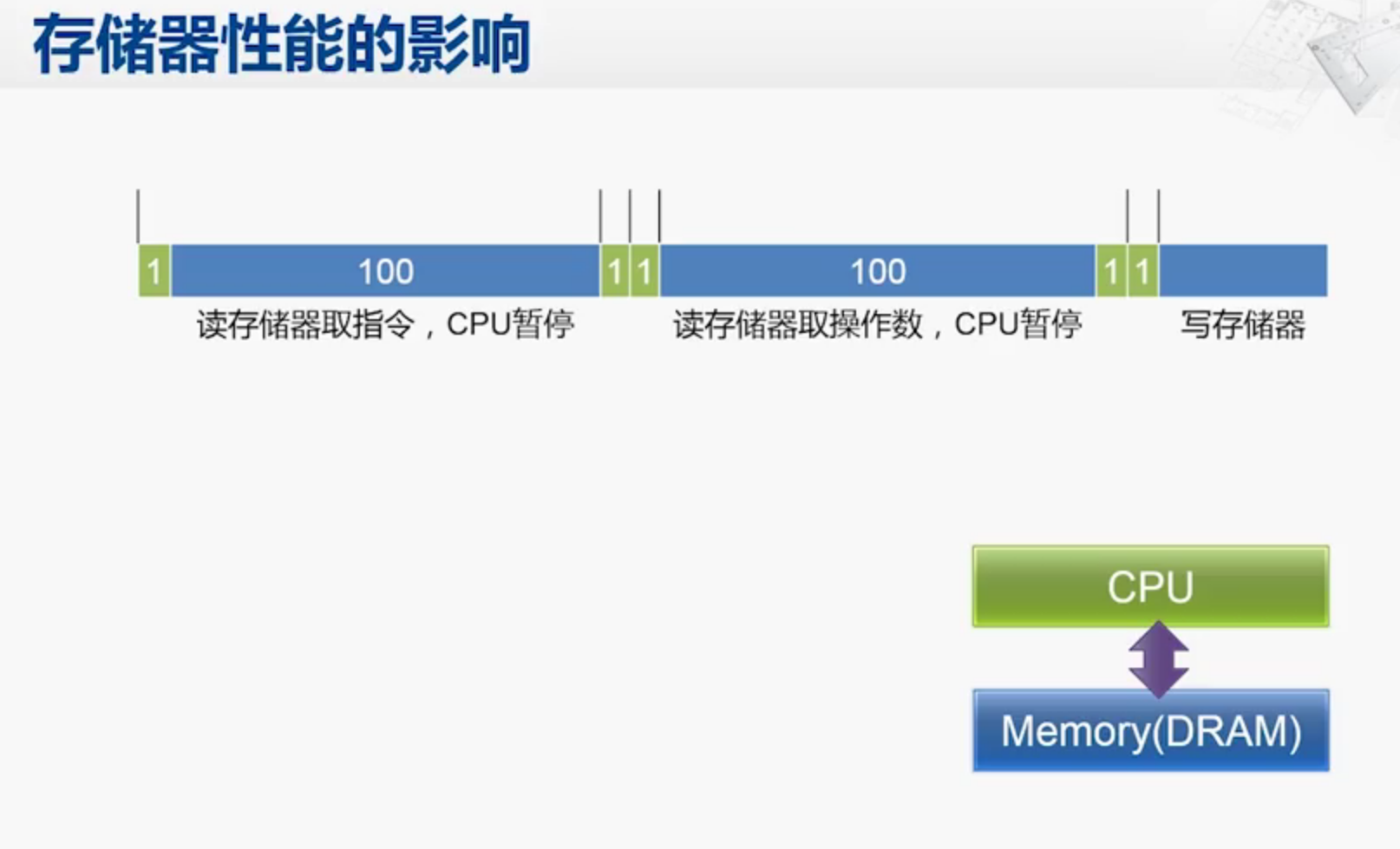
DRAM读取数据时间是CPU读取时间的一百倍,因此执行一条指令的时候非常的慢!
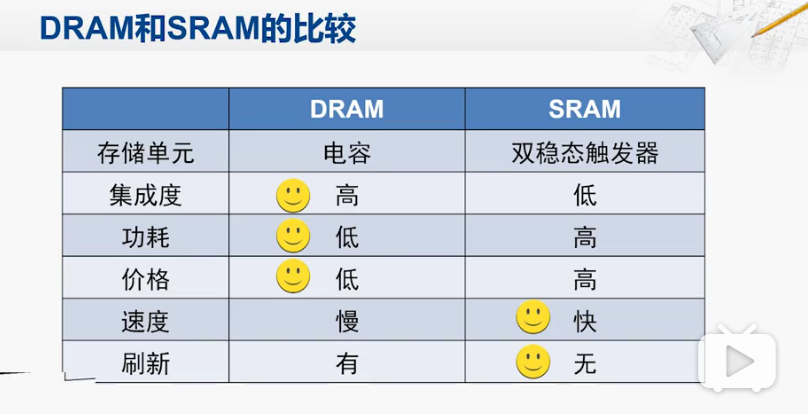
因此考虑在CPU 和DRAM之间添加一个SRAM,使得CPU所需要的程序和数据大部分时间存放在Cache中,大大缩短执行指令时候所需要的时间周期。
DRAM
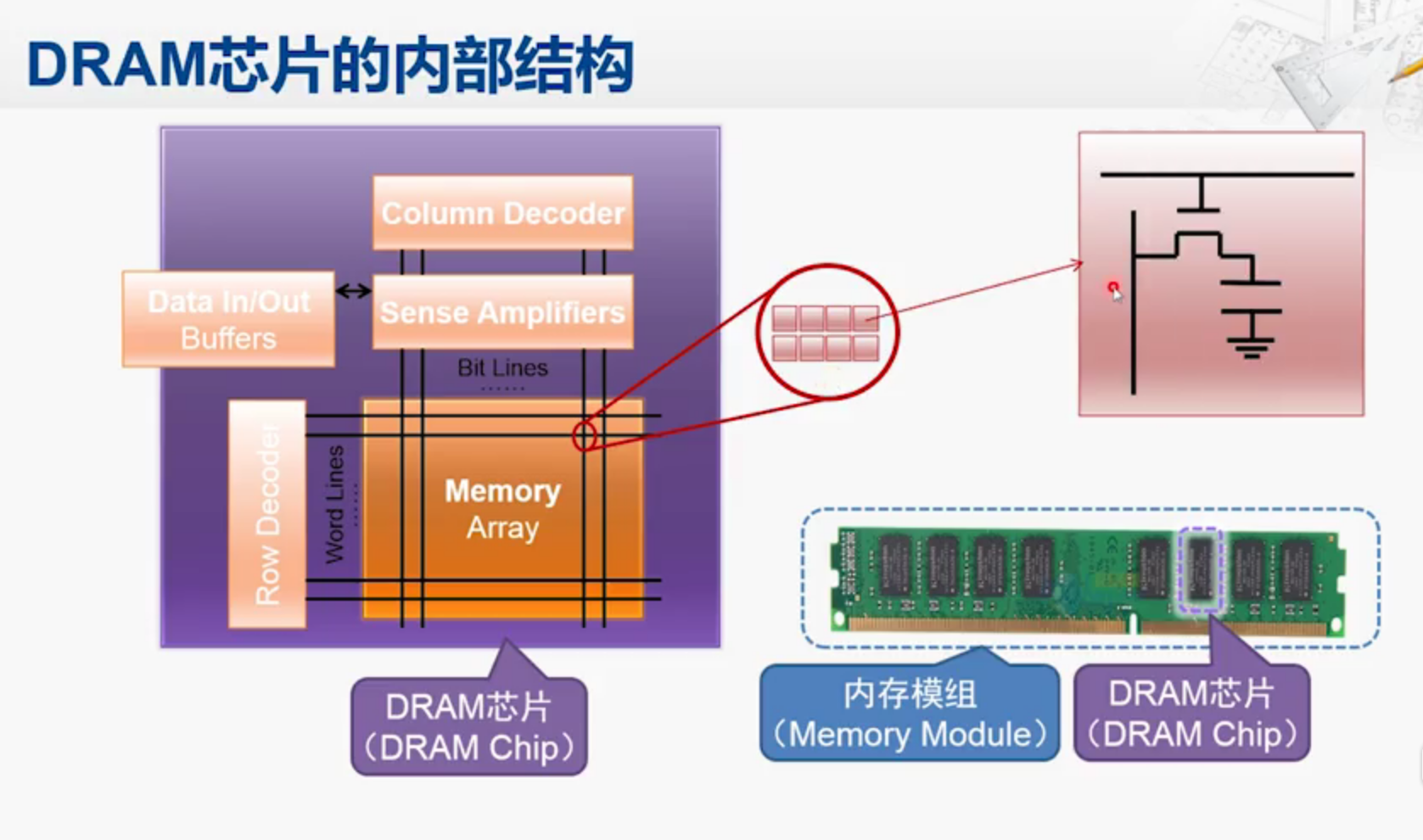
右下角就是内存条,通常也叫内存模组,是由若干个DRAM芯片组成的,核心就是左图的内存阵列,从外界输入行列信号,就可以读取一个基本存储单元,如红圈每个存储单元有若干个bit,通常是4个或者8个,每一个放大来看如右上角电路图所示。
基本存储单元
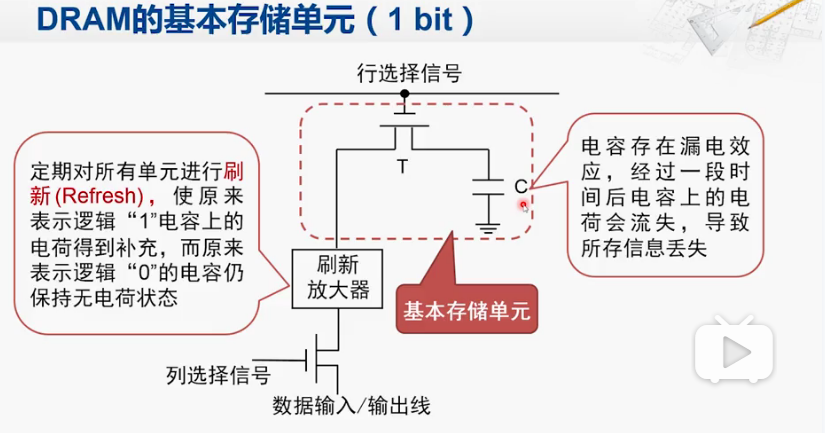
通过存储的电容来表示存储的bit信息,对SDRAM的读写,主要体现在电容的冲放电,而这个是很难再做提高的。
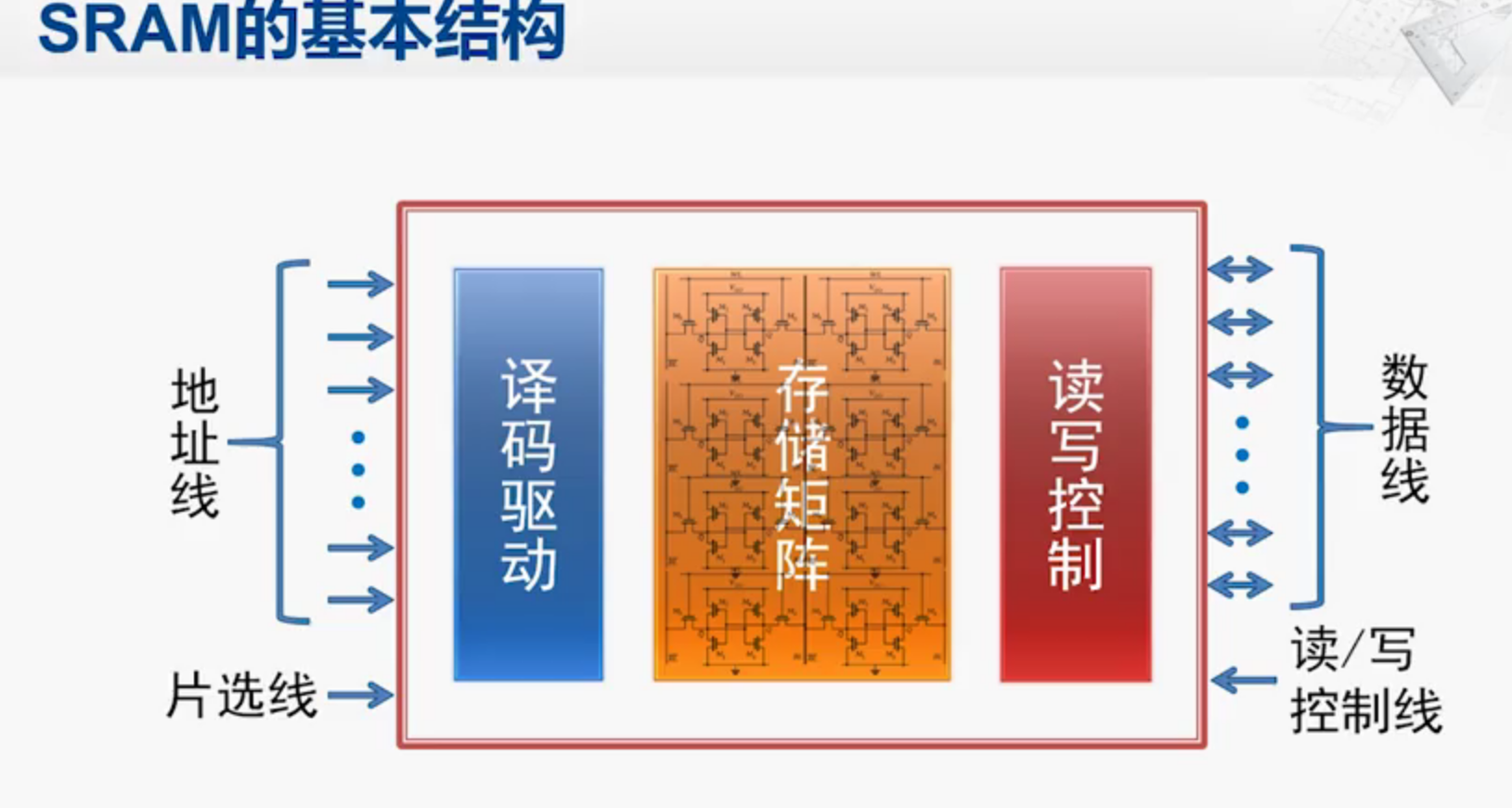
SRAM采取的是晶体管开关存储,远比电容充电放电要快,所以SRAM比DRAM要快,现代CPU的高速缓存通常用SRAM实现
内存工作原理
第一步,申请系统总线,获得总线控制权后,会把地址送到内存控制器中。
然后内存控制器会把地址分解为行地址和列地址
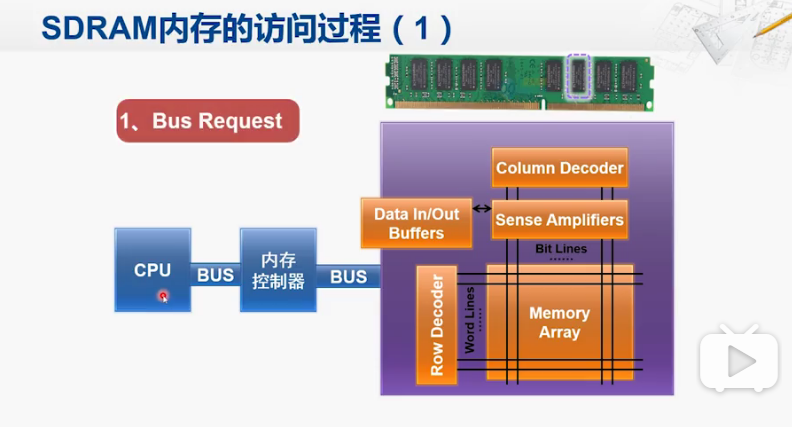
第二步 行访问
内存控制器向SDRAM发起访存操作
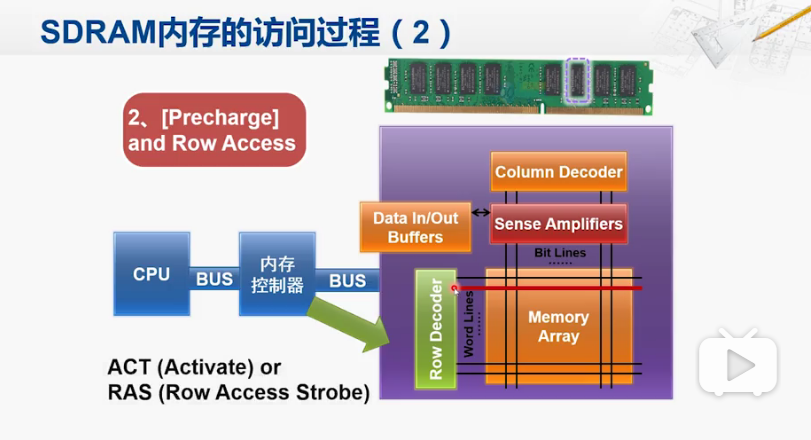
这一行当中所有存储单元的信号通过放大器之后会放在一个缓冲区当中。这就是激活/行访问
第三步 列访问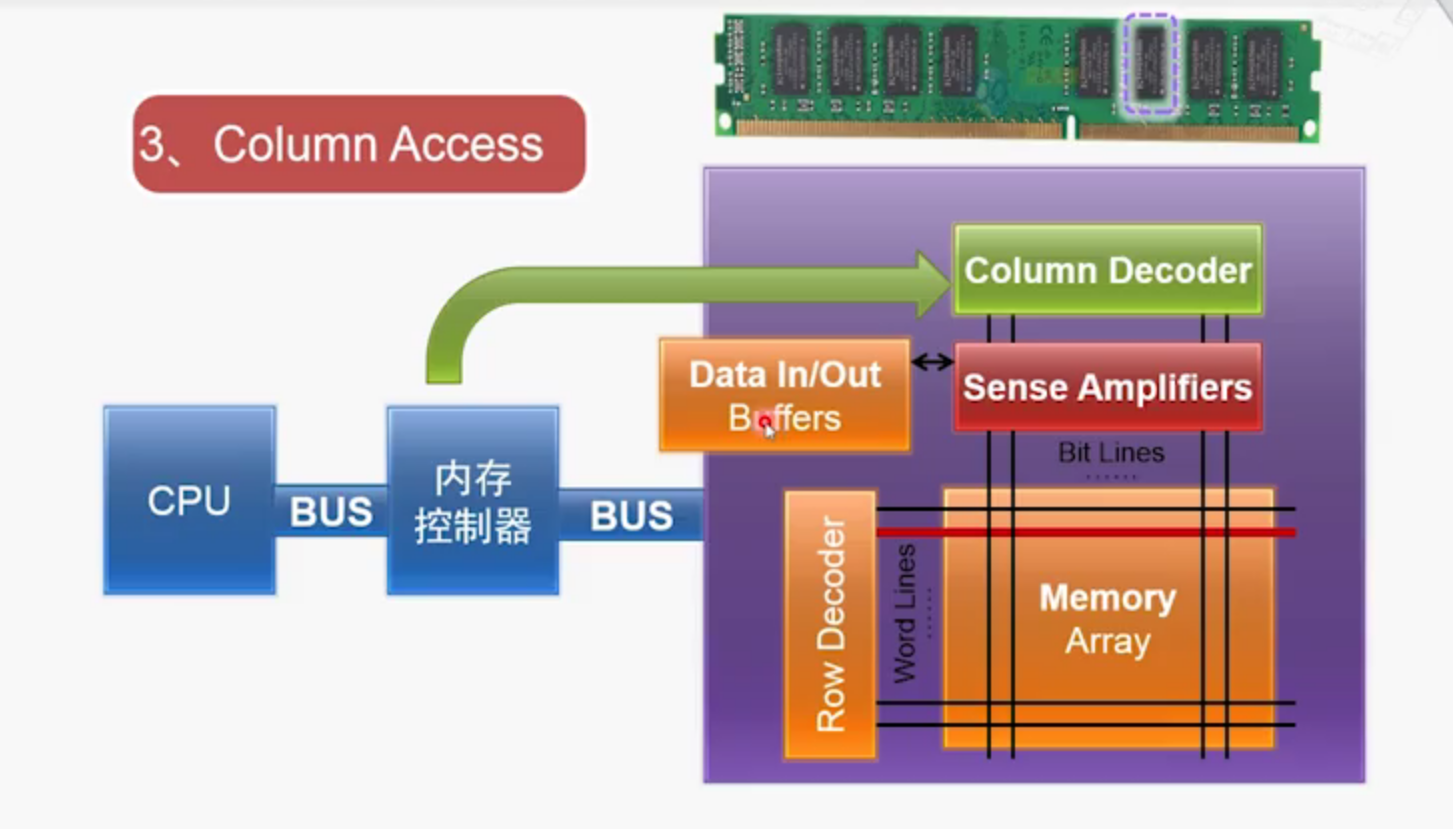
第四步 送回CPU
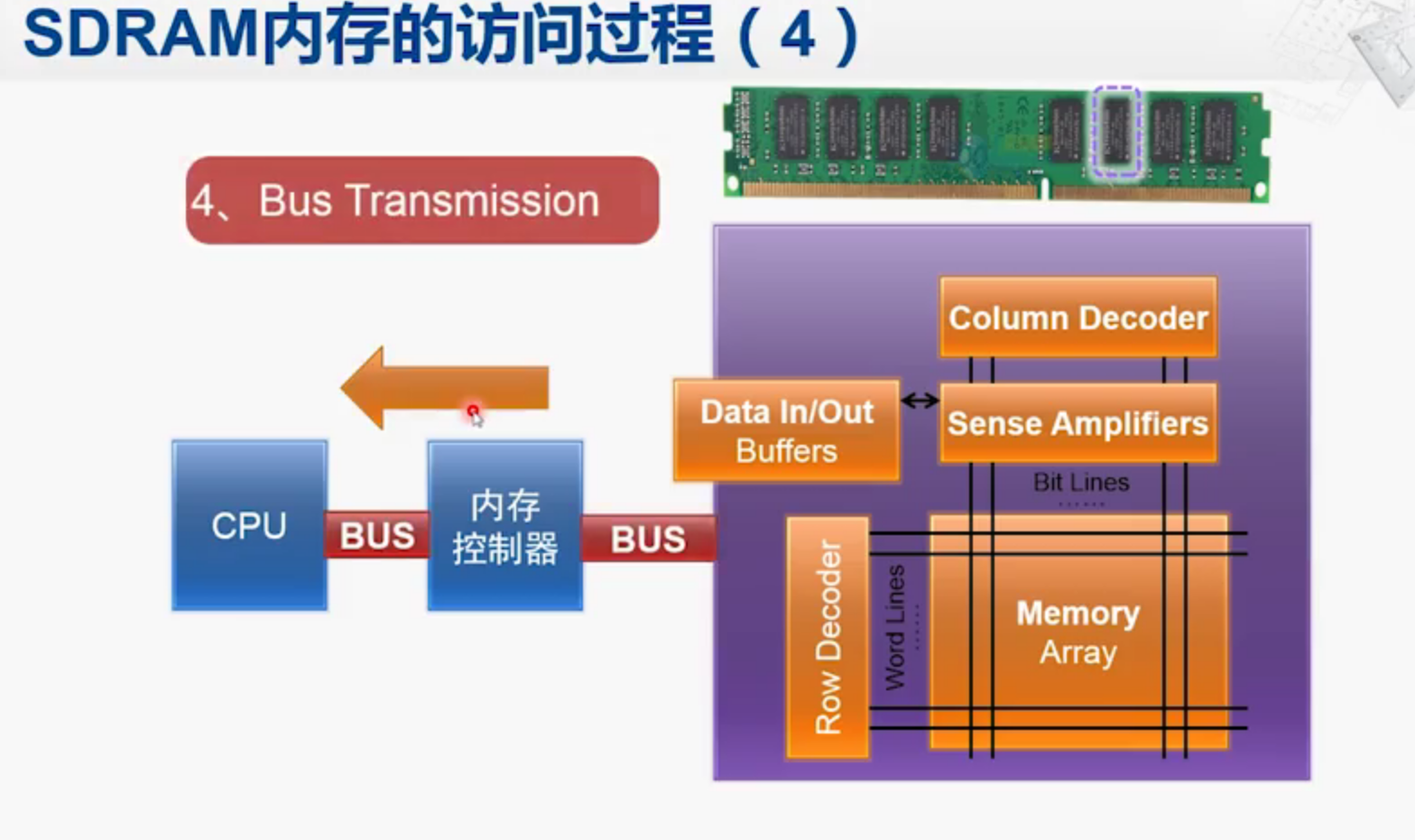
内存控制器把采样到的数据送回给CPU
CPU之后又发送地址信号,如果不是同一行,则就要把激活的行关闭。
这个过程叫做预充电
SDRAM的关键性能参数:
1.tRCD row to column delay 从行选到列选的延迟时间
2.CL CAS Latency 从列选到数据输出的延迟周期数
3.tRP 行预充电时间
数据个数就等同于内存条上DRAM芯片个数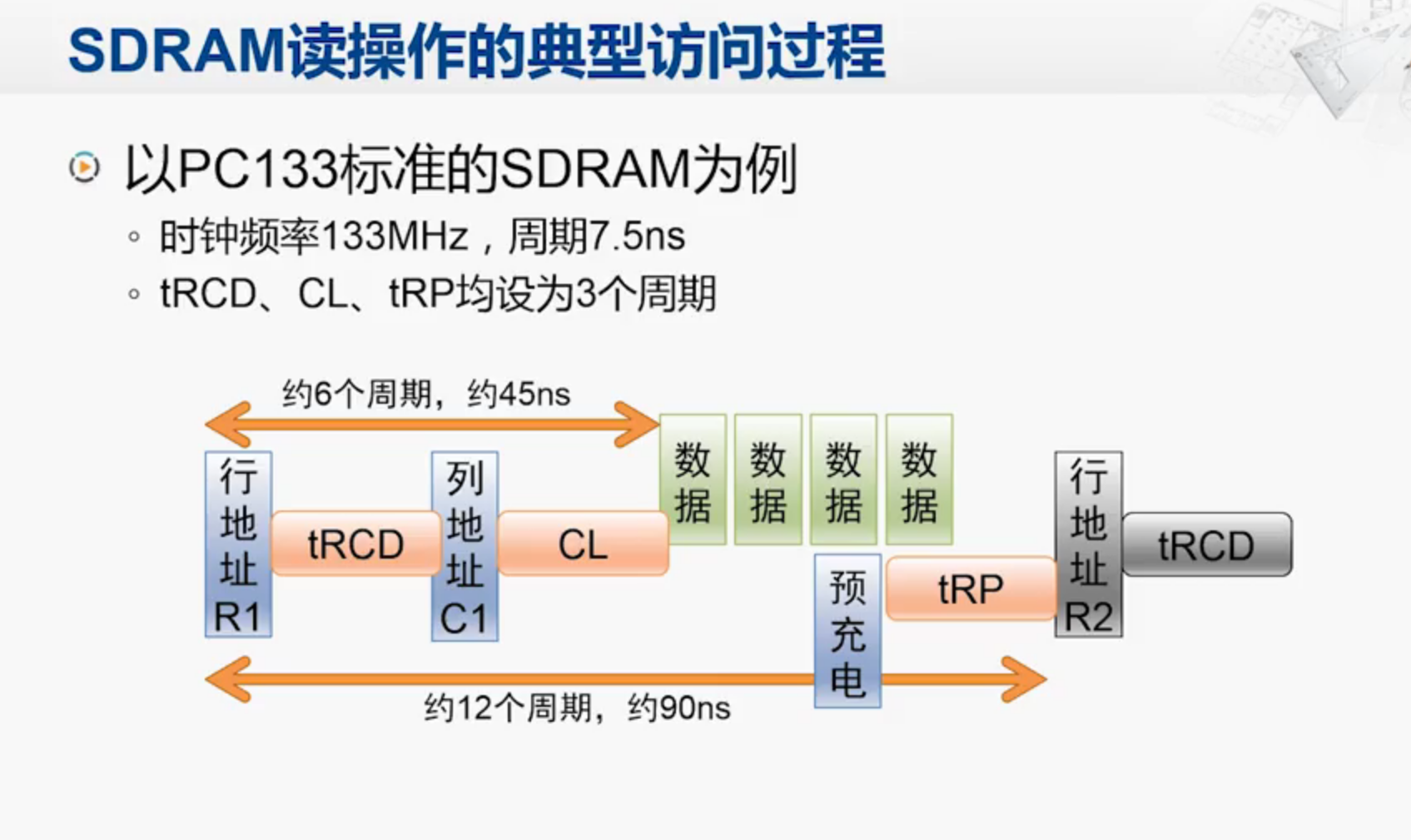
所以整个过程的周期并不等于7.5ns!
DDR SDRAM 比 SDR SDRAM 要快,原因是前者一次能比后者取多两倍的数据
DDR是数据传输的方式,不等同于内存
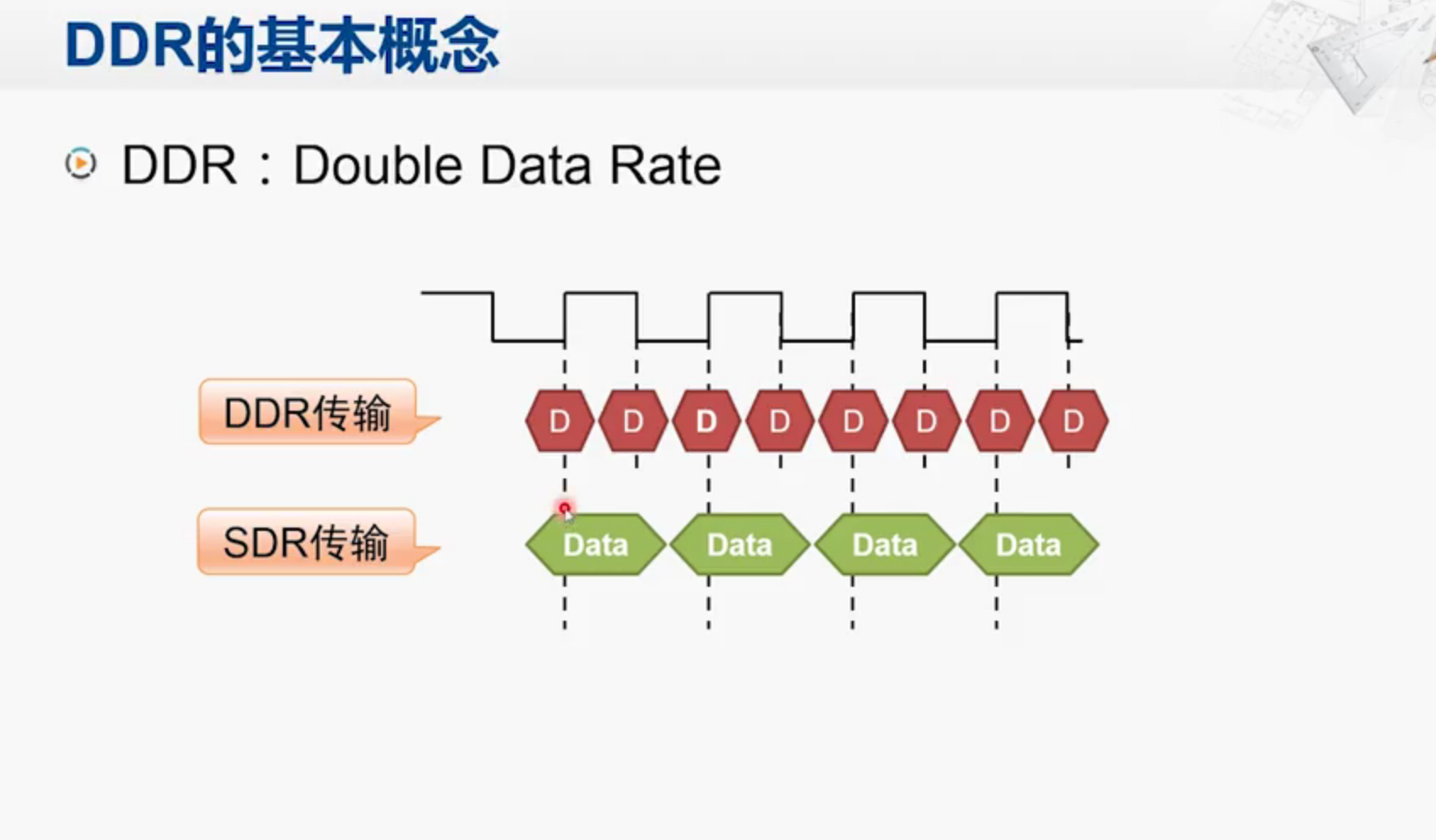
DDR 与 SDR 对比
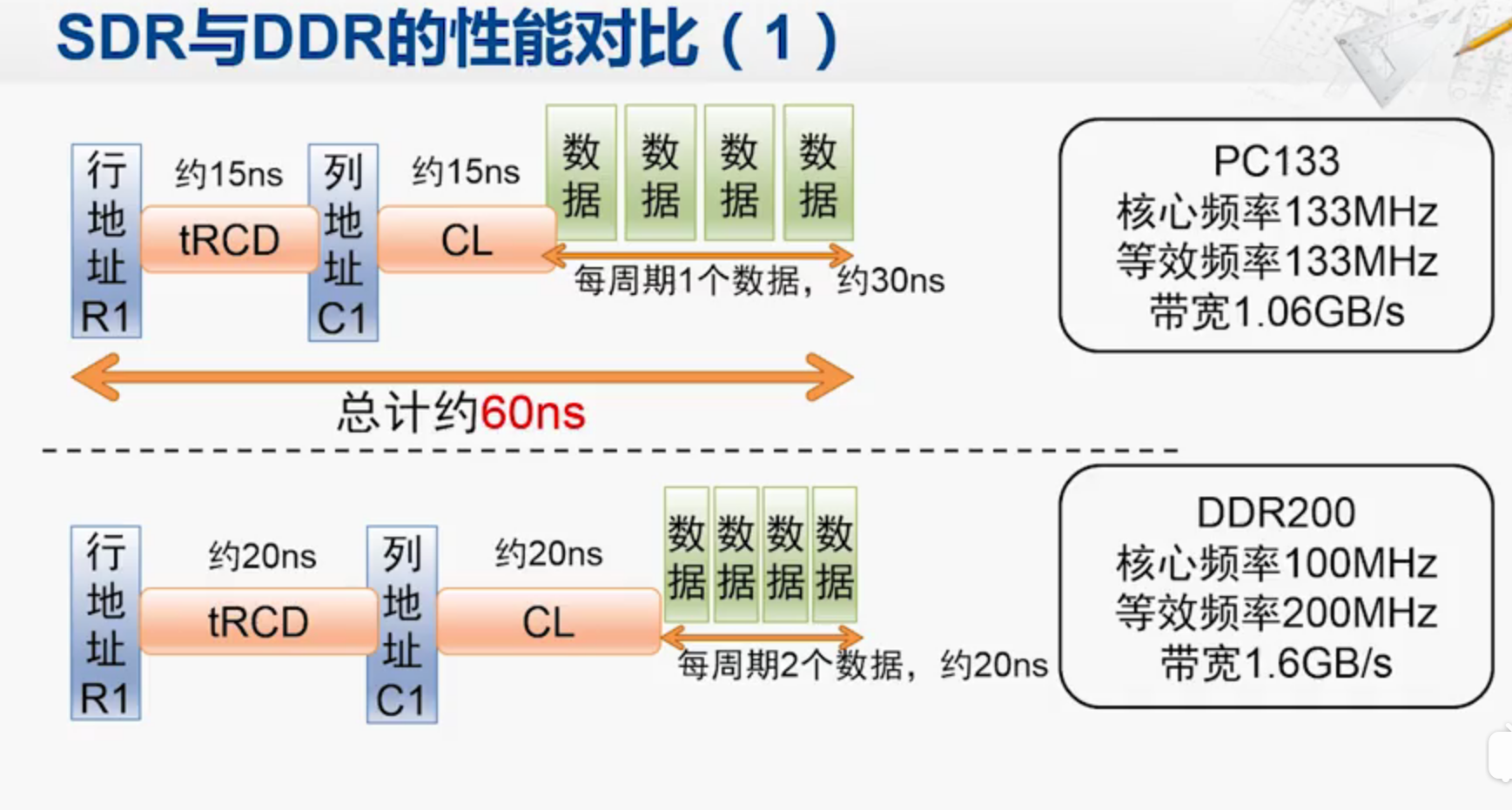
DDR由于一次读取两个数据,所以tRCD和CL变慢了,但是每个周期能同时取两个数据。
这里的带宽就是由每个周期取得的数据计算出来的。
衡量CPU有两个指标
访存带宽
单位时间内存储器所存取的信息量。
访存延迟
读出第一个数据所需要的时间。
Cache工作原理
空间局部性:
空间局部性是一旦一个指令一个存储单元被访问,那么它附近的单元也将很快被访问
时间局部性:
时间局部性是一旦一个指令被执行了,则在不久的将来,它可能再被执行。
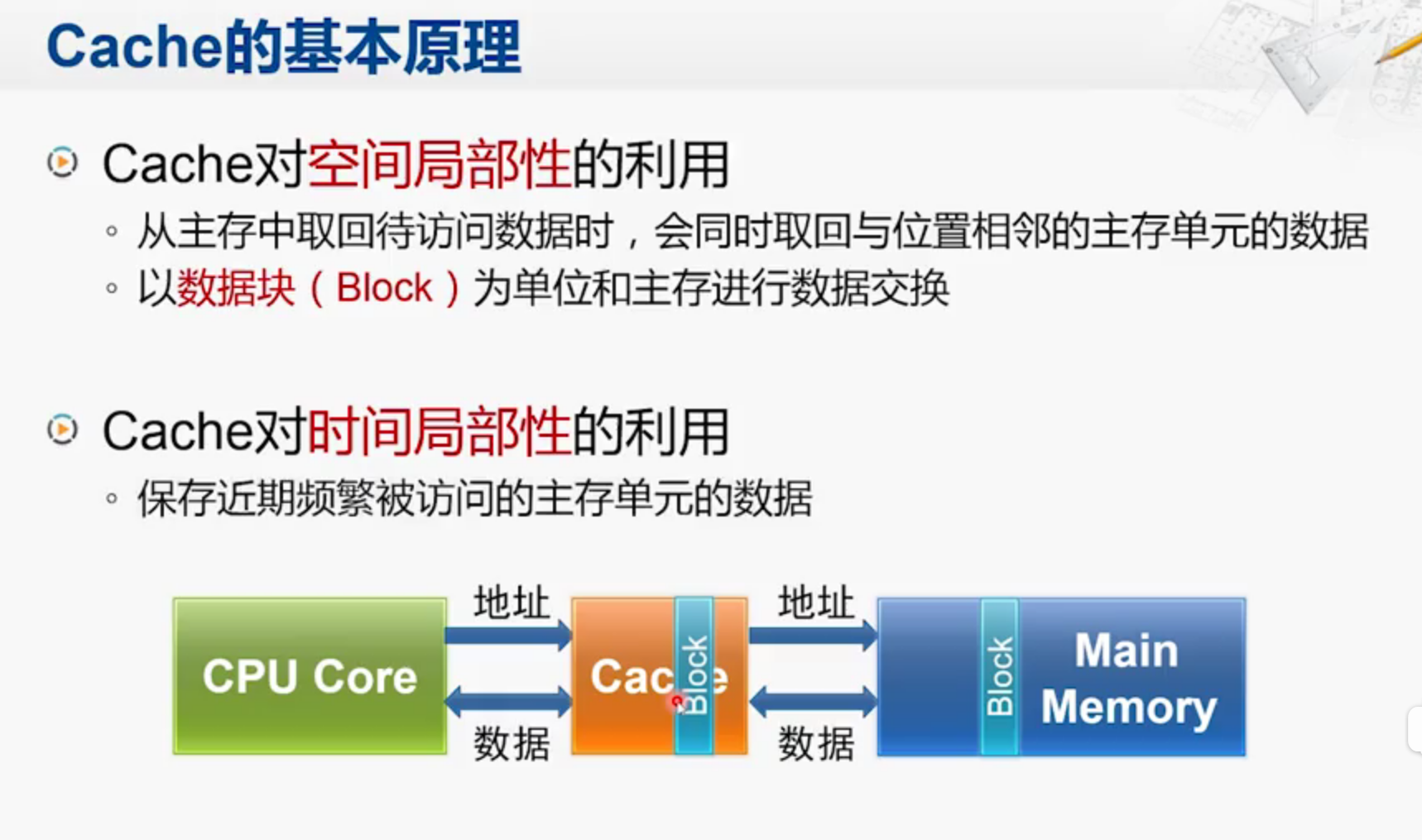
操作过程
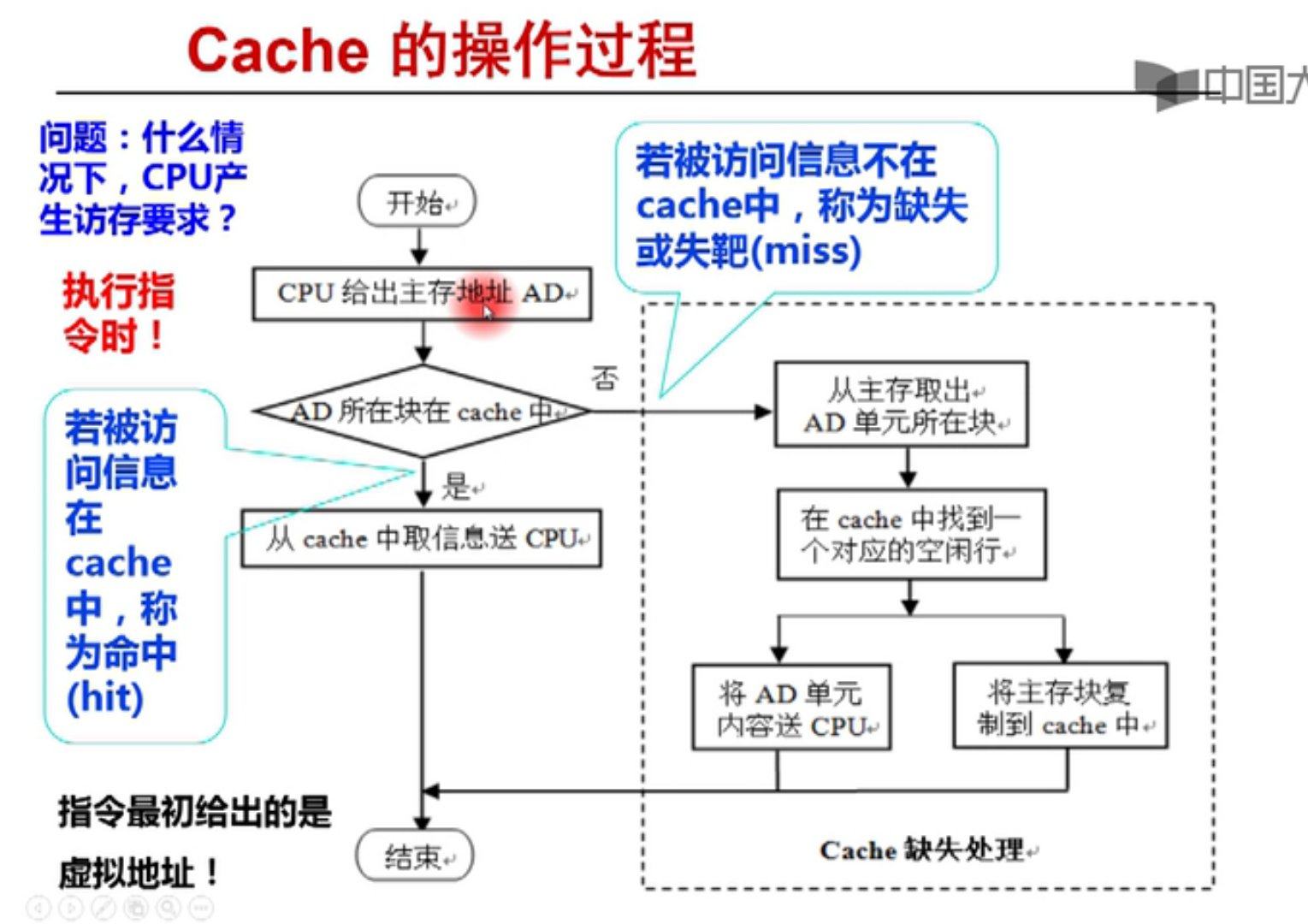
怎么把虚拟地址转化为实际地址是个问题
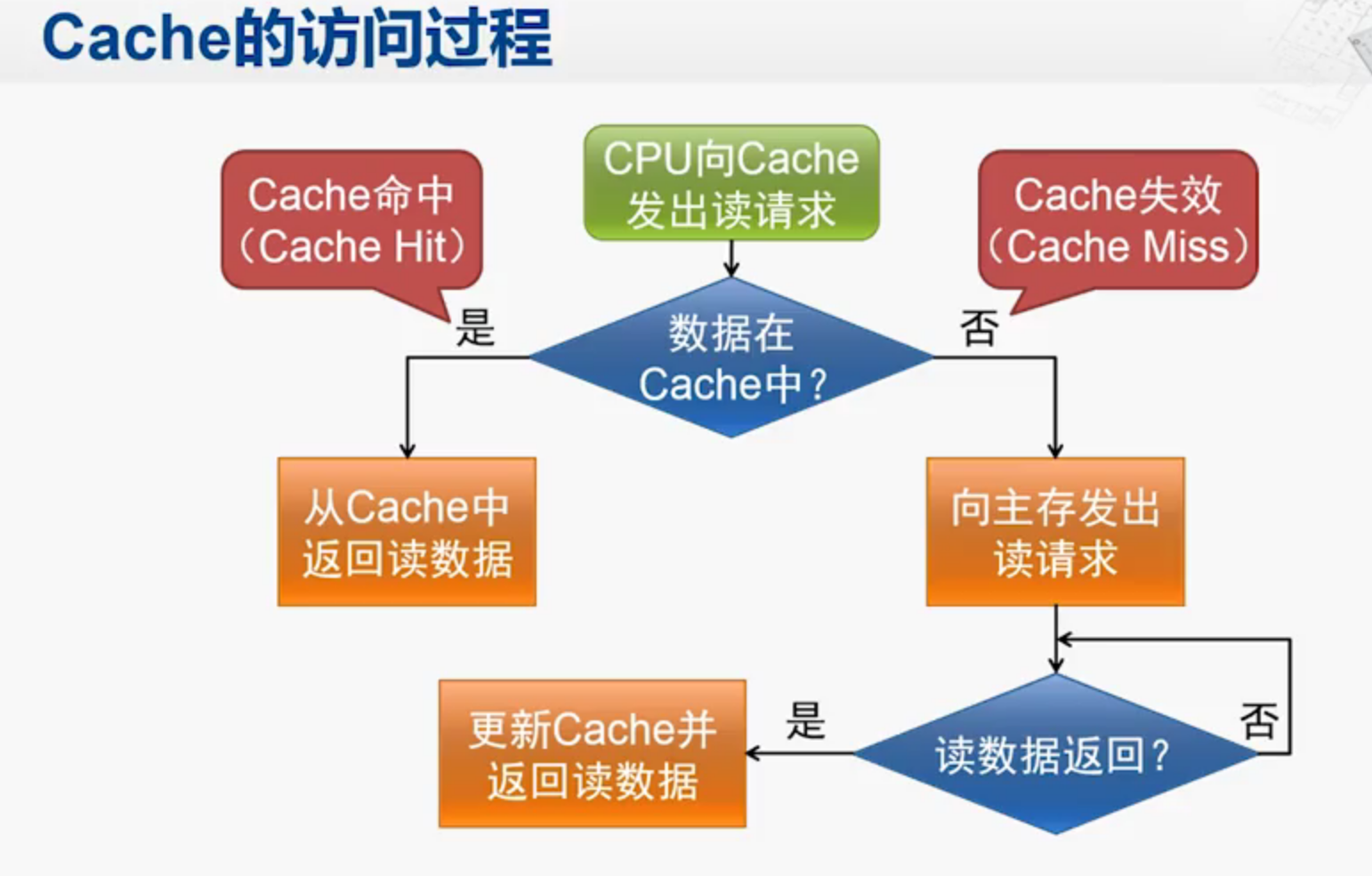
Cache读操作
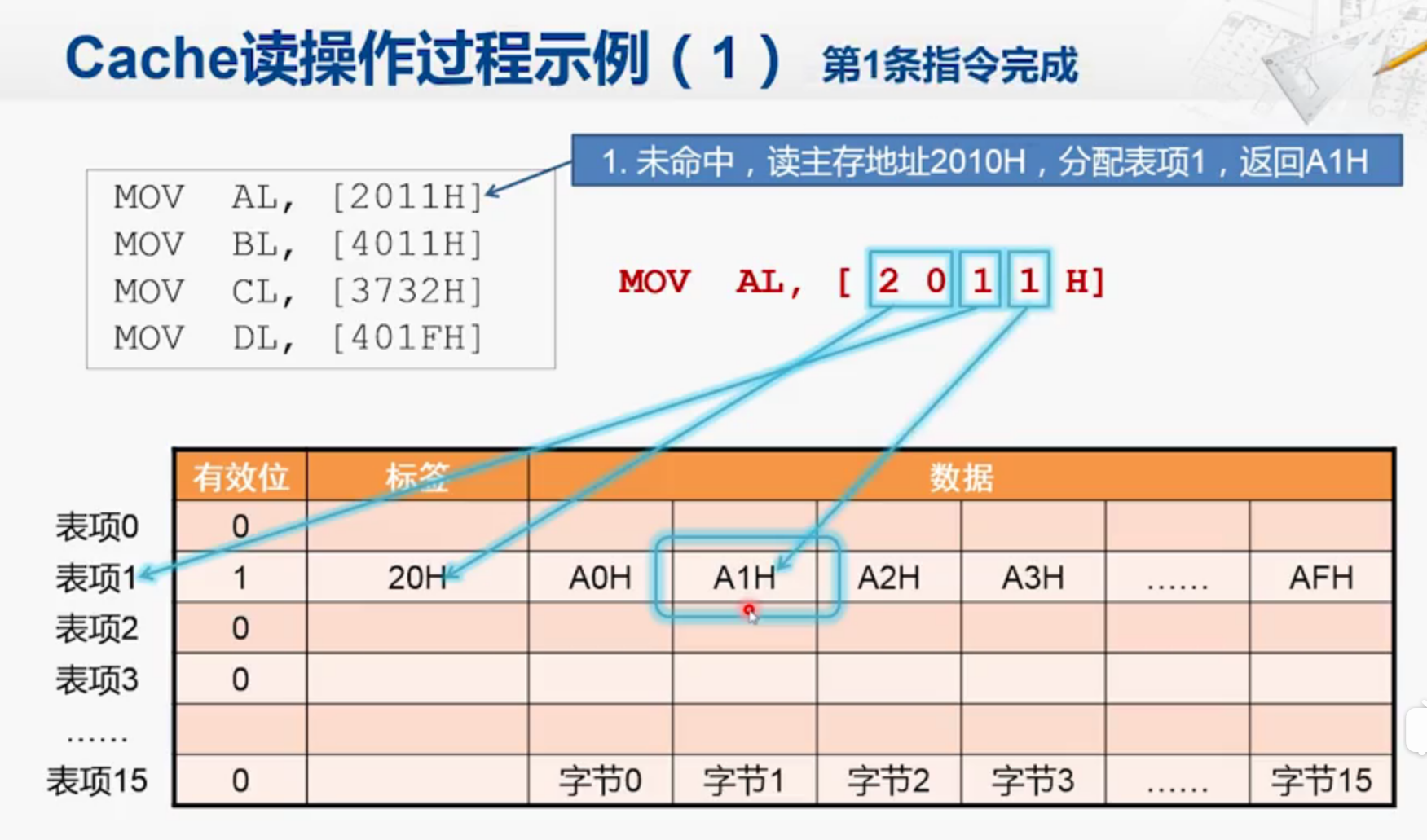
1.第一条指令,由于一开始Cache是空的,所以没有命中。因此Cache访问主存。
之所以分配给表项1,是由地址倒数第二个数字决定的。(不看H)
然后前面的所有项(20)放到标签处。
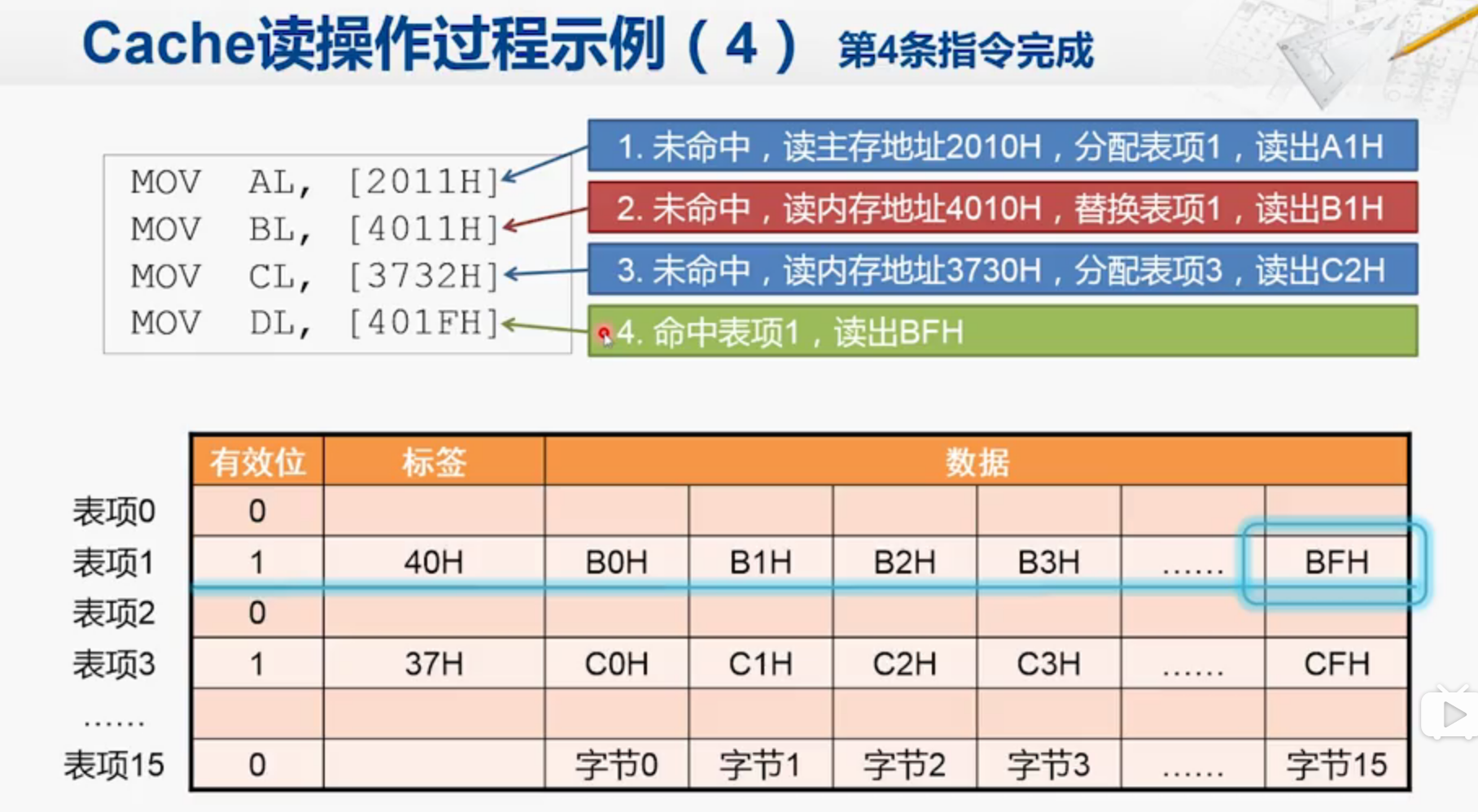
2.第二种情况,没有命中,因为表被占用了。
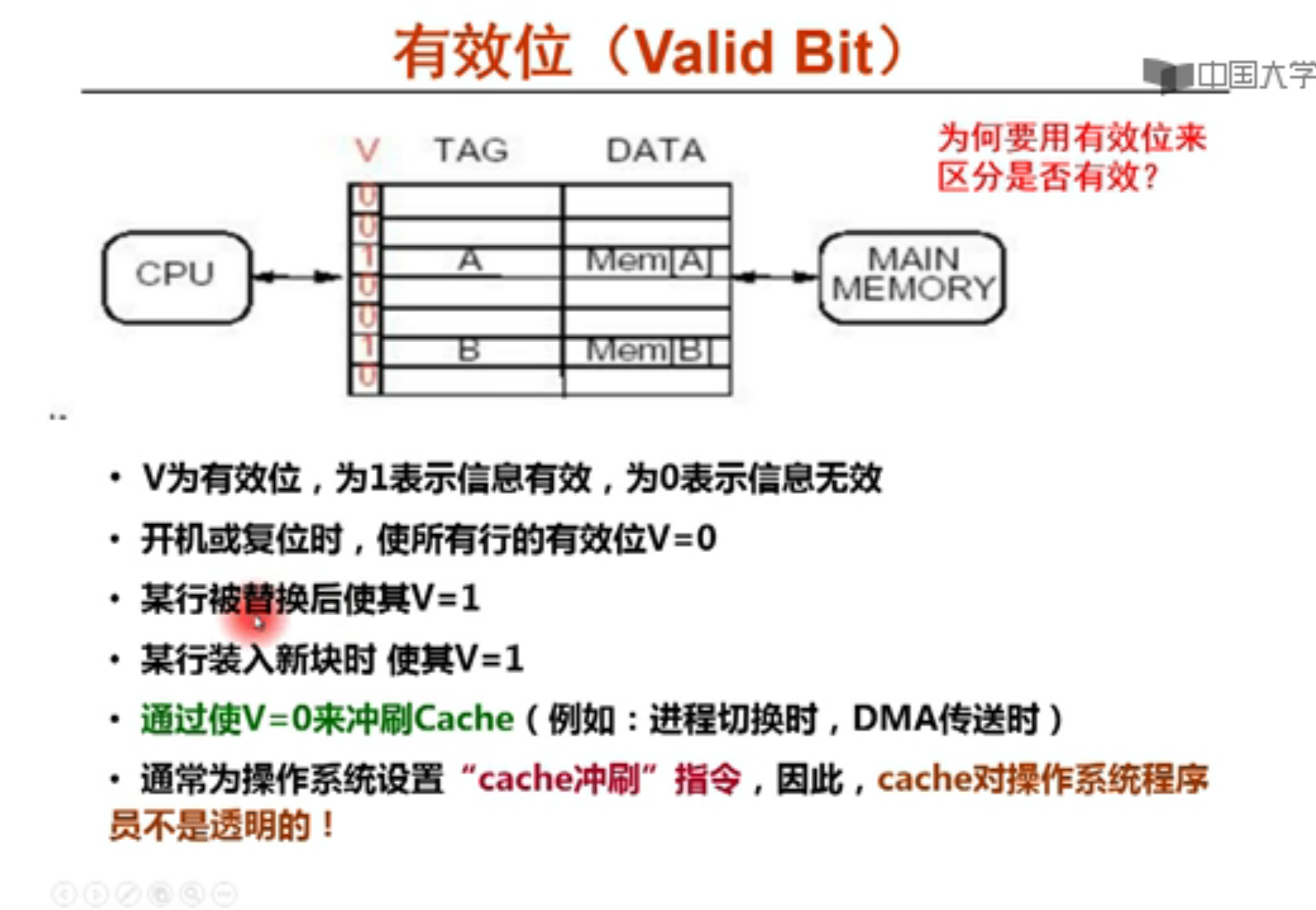
4011H,先检查有效位1,发现原来标签是20H,因此把地址替换掉。
Cache写操作

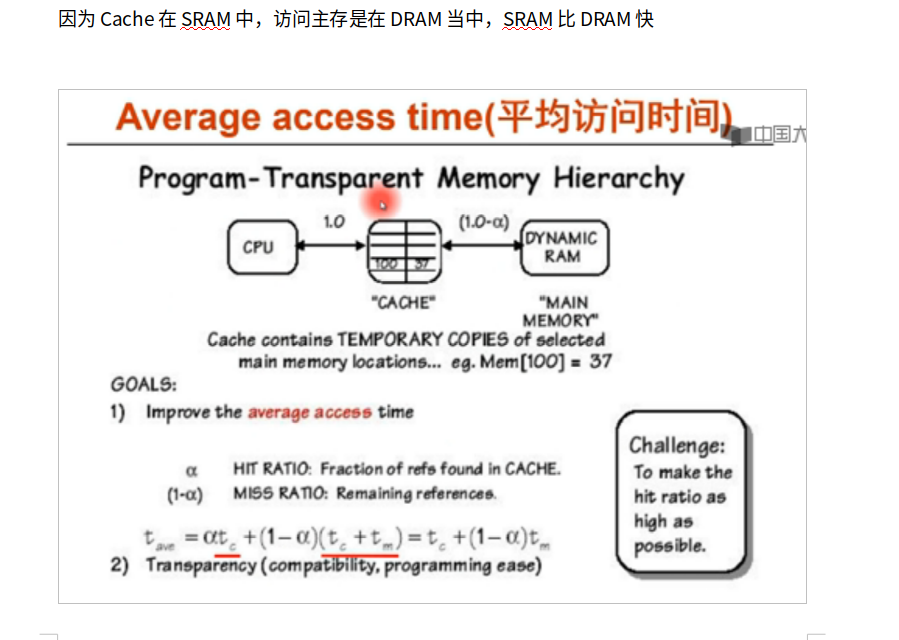
平均访存时间


Cache映射策略,直接映射会遇到这么一个问题:
就是存储器会每隔八个地址把数据映射到Cache中,如果程序交替访问这两个数据,那么每次访问都会访问主存,把地址写入到Cache中,这样性能比没有Cache的时候还要差。
也可以通过二路组,四路组相联策略,但是代价是每次取数据的时候,要取多个标签比较,如直接映射只需要取一个标签出来,如图中的0,而二路组则要2个。而且这样会使得硬件电路变得复杂化,增加了命中时间,得不偿失。
常见Cache替换算法

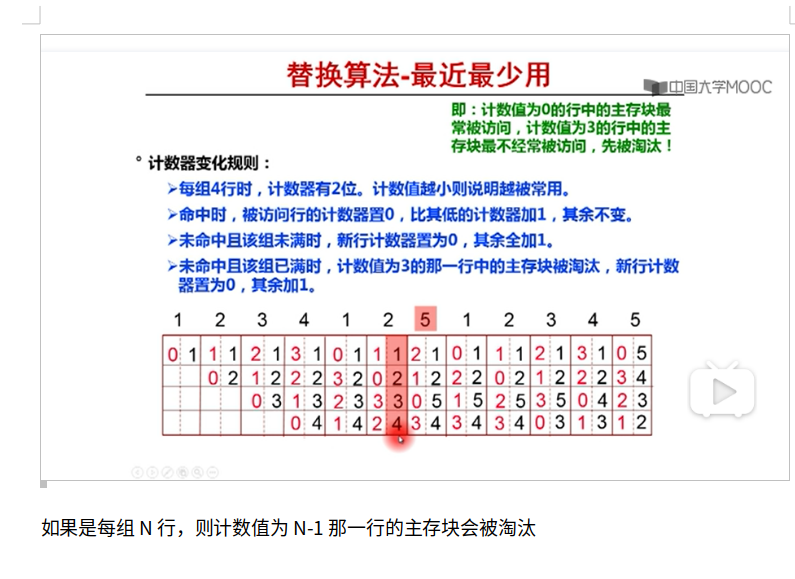
LRU的实现:
1.队列
2.用LRUnumber,例如初始化每块的LRUnumber为0,当要访问这块Cache的时候重新设置为0,然后其他块++1,然后LRUnumber最大的那个block就是最近最少使用的块。
计算机领域单位使用情况

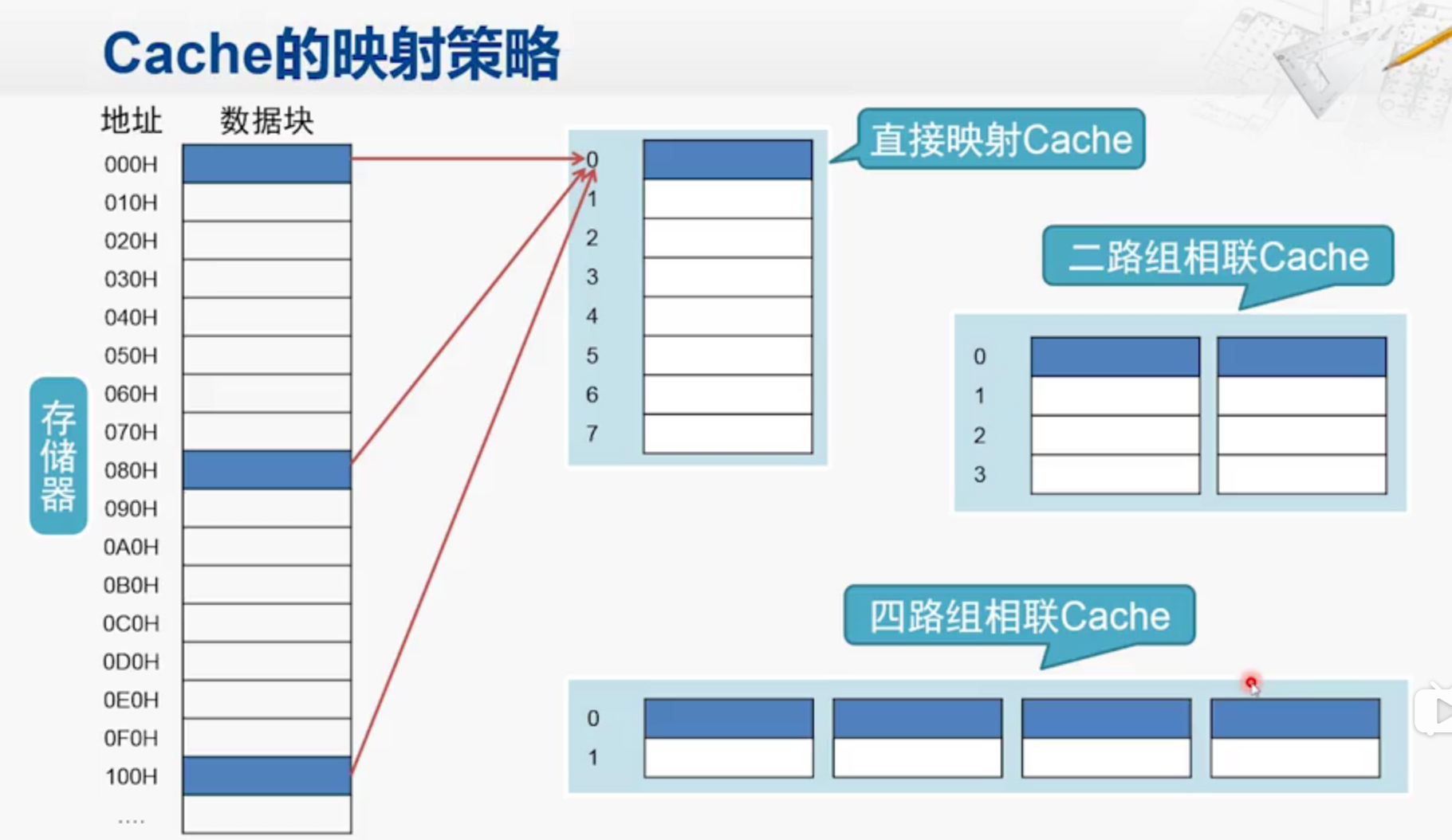
Cache 映射
直接映射
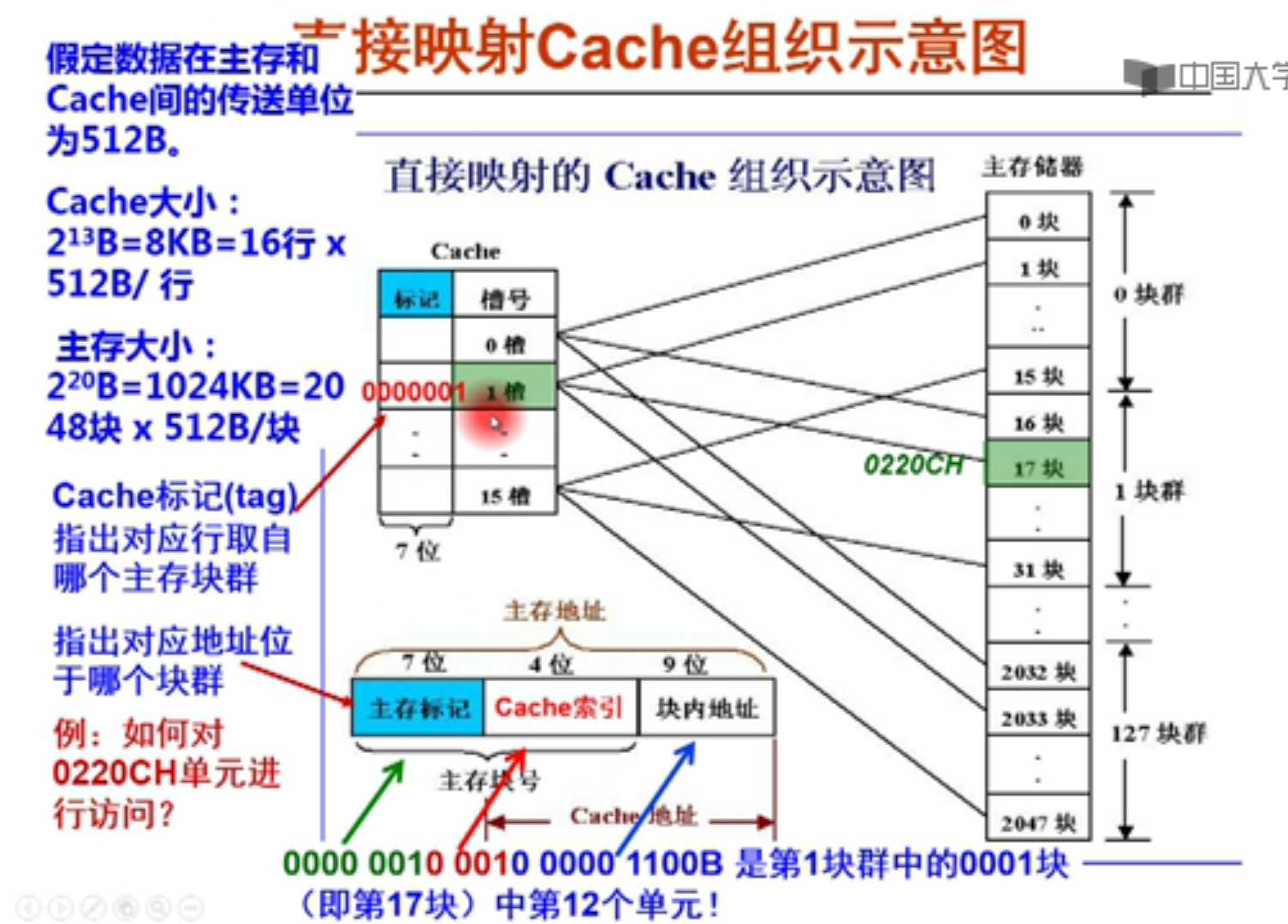
Cache 大小:
假设每个槽,就是cache的每个block能装512个(2^9)byte,说明b = 9
然后一共有16个sets,说明 s = 4,
因此cache地址一共是(s+b = 13位)
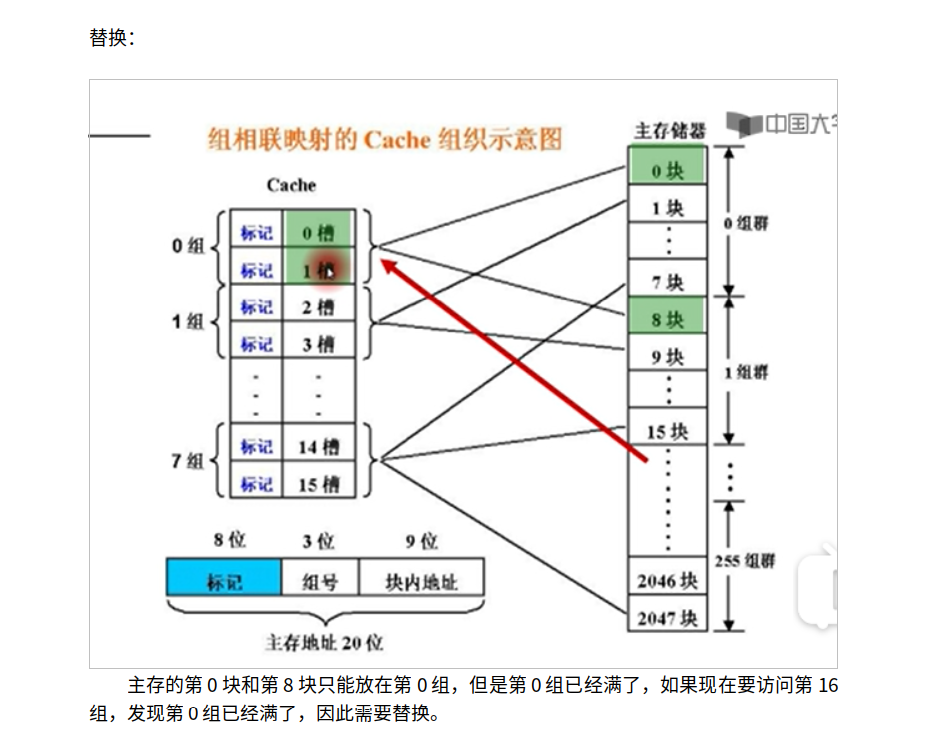
主存的第0块,第16块,第32块。。都能放在cache的0槽当中,但是怎么知道
是哪个块群的呢?因此用标记号来说明,那么标记号该有几位?就是块群的个数2^7=128
所以标记号就是7位,标记号用来指出对应行来自于哪个块群。
主存大小:
2048 块 512B/块 = 2^11 2^ 9 = 2^20
所以主存地址一共20位,包含了9位的块内地址,4位cache索引,剩下7位主存标记。
主存一共2048(2^11)块,所以主存标记和cache索引用来标记主存的具体块号。
1 | 例如:给定地址 0220CH |
所以大概过程
拿来一个主存地址,然后划分为三段,根据中间索引号来寻找cache对应槽,然后看
valid位和标记位,如果valid=0,说明里面是空的,冷不命中,要从主存把地址送过来。如果valid=1,而且主存标记刚好是标记位,就根据块内地址在槽内寻找对应单元。
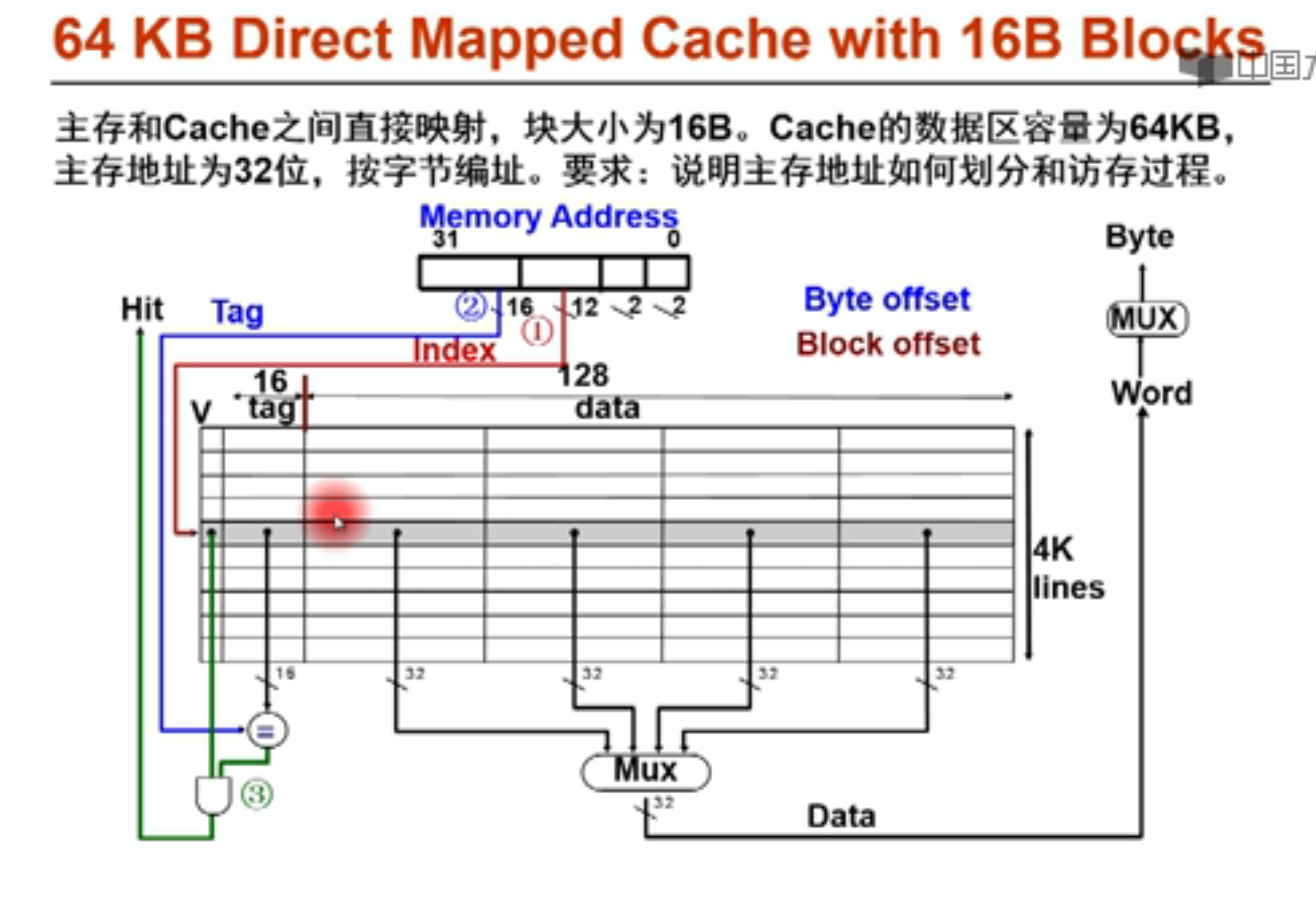
给定32位主存地址,划分为三部分。
首先由于块大小为16(2^4)B,因此b = 4,偏移位 4位
索引位呢? 中间的索引位决定于cache有多少行
因此行数=64KB/16B = 4K = 2^12 行
因此中间索引位一共有12位
剩下16位就是tag位,标记位
给定内存地址,先由中间12行找到cache对应的行,看tag位与valid位是否满足条件,(valid=1说明这一行有数据)满足条件就hit,hit了就根据偏移位寻找对应的数据。
块大小位16B,即128bit,使用多路选择器MUX来选择取哪个32位的data。
11 最左边 10 中左 01 中右 00最右边
如果取的是int型(word),由于word alignment,即内存地址最后的两位其实是不需要理会的。那么只看第三第四位,就是所谓的block offset。决定所取int放在哪个block.
而如果要取的是char型,要在取了word之后再通过一个MUX,根据主存地址最后两位(Byte Offset)来得到要取哪个byte。
cache 容量
上图中容量为 行数 X(每一行的bit数)
(16+1)4K + 64K 8 = 72.5KB
数据 64KB/72.5KB =88.3%
有一个64行,块容量为16bytes的cache
十进制地址 1200应该映射到哪一行?
方法一: 【1200/16】mod 64 = 11
方法二: 1200转换为二进制 0100 1011 0000
索引号 = 6 ,即看中间存的是哪一行,001011 就是 11
实现一个直接映射,16K行数据,块大小为1个字(4B),32位主存地址的cache需要多少容量?
16K = 2^14 行数据,即中间索引有14位
byte =4B ,b = 2
所以tag = 32-2-14 =16
因此16K(1+16)+16K4B =16K*(1+16+32) =784Kbits
(1+16)中,1是valid位
特点

全相联映射方式
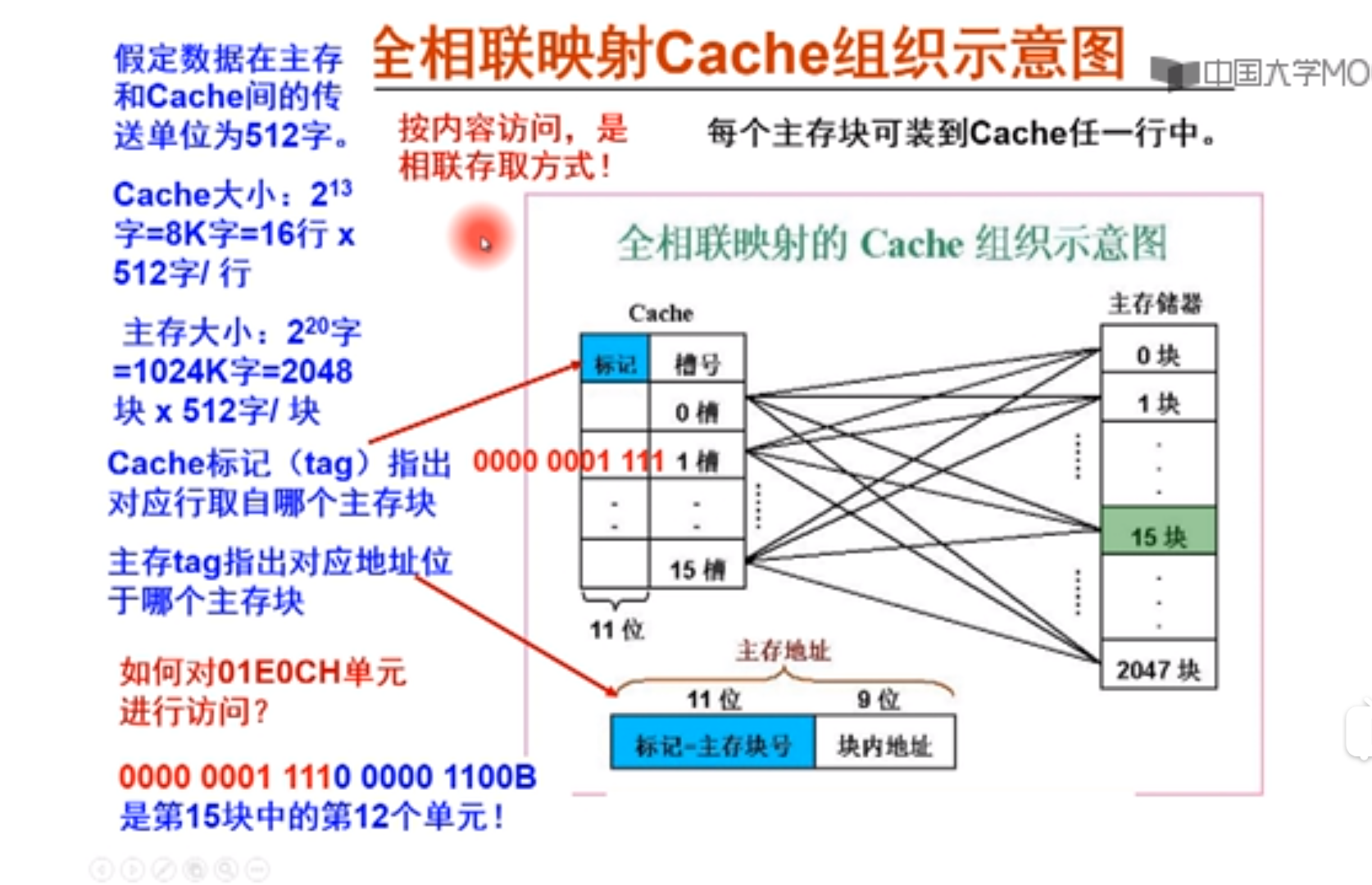
给定地址,根据标记主存块号找到数据所在主存的哪一块,00000001111就是第15块,但是不知道在Cache的哪个槽中,所以只能一个一个槽比较。所以叫按内容访问。
为什么没有cache索引字段?
因为其可以任意映射到某一个行当中.
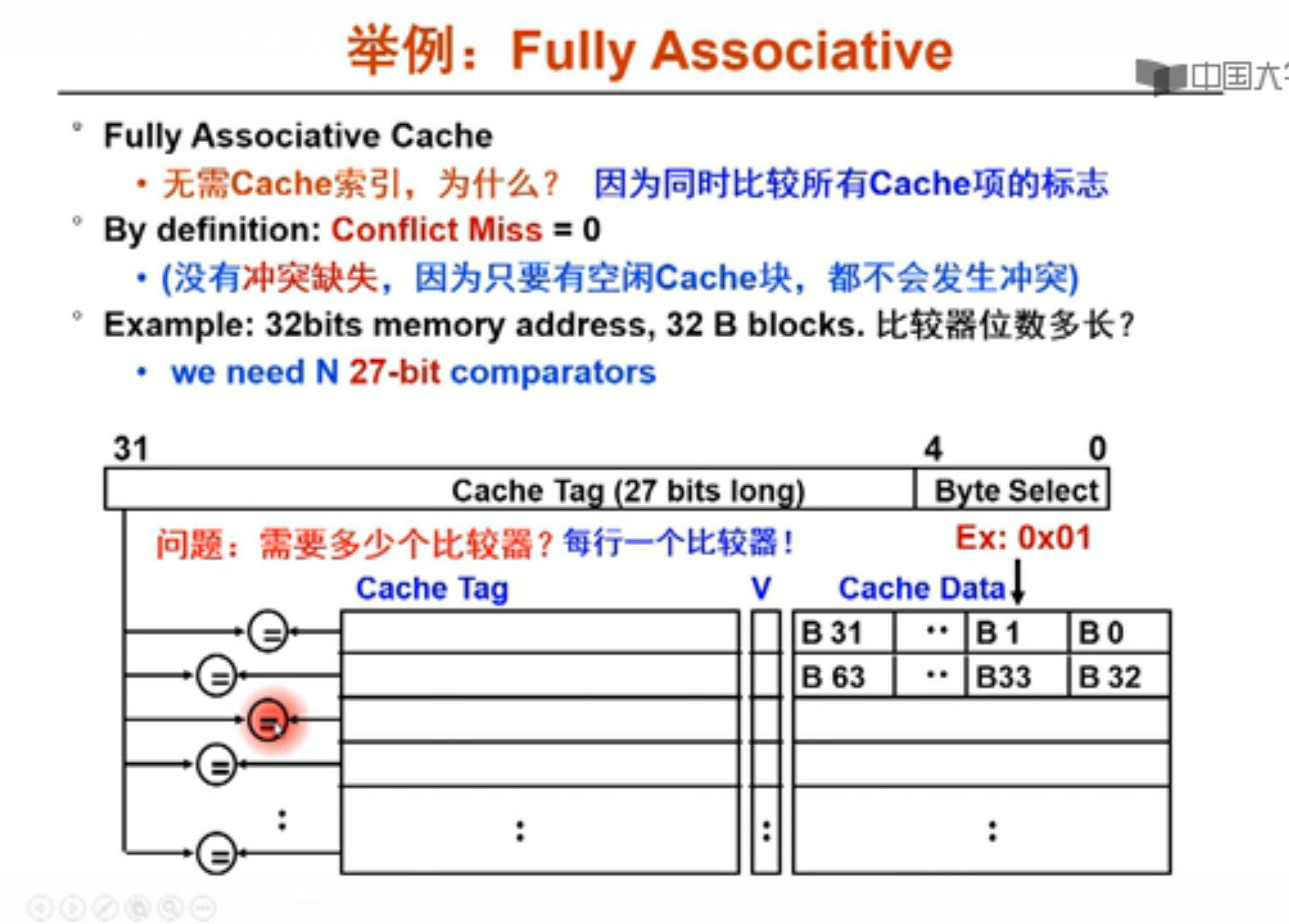
优点就是没有冲突,时间相对加快,但是tag长了,而且每一行都有一个比较器,比较时间长了,相当于命中时间会加长,而且比较成本也增加了,cache容量也变大了!
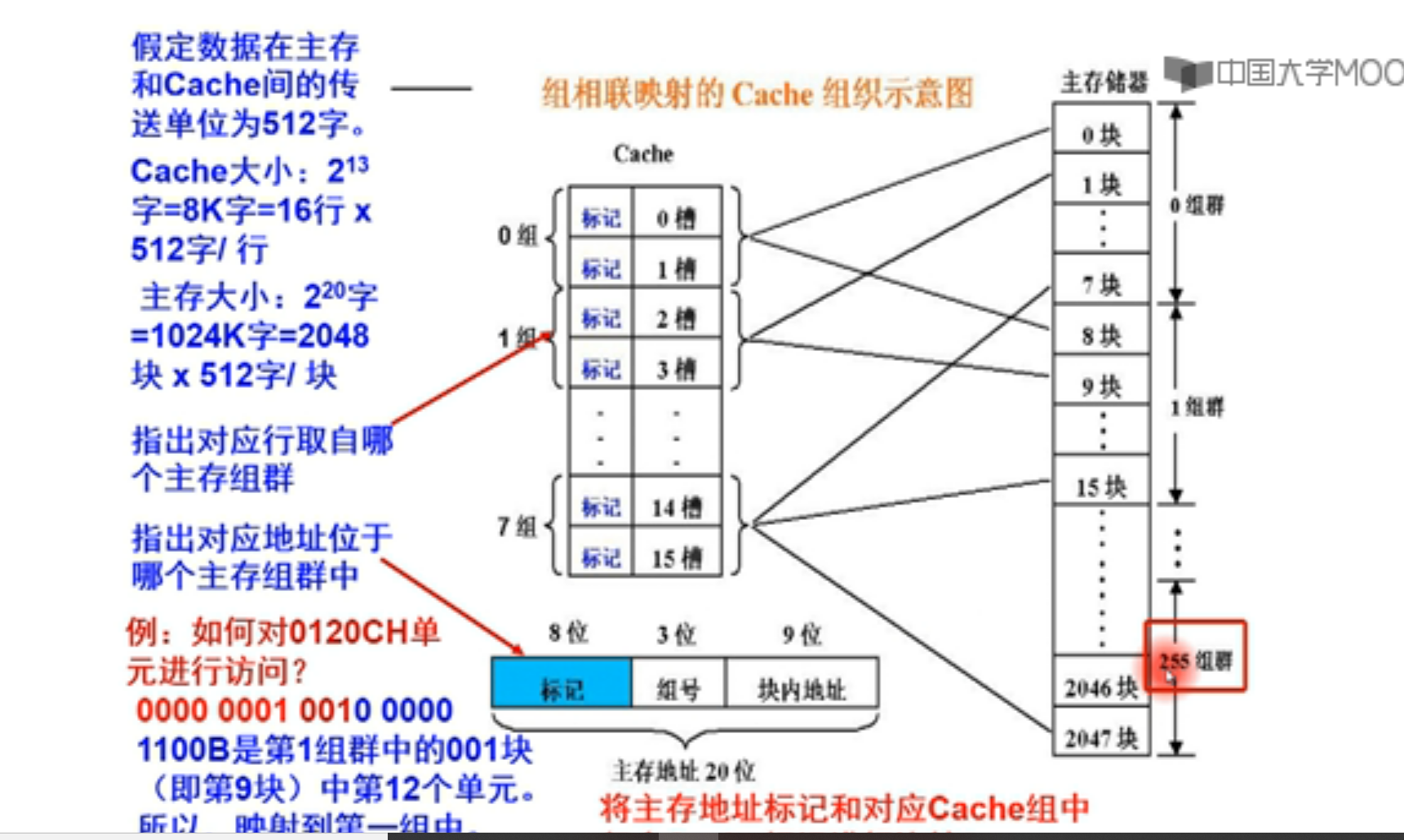
前8位标记表示cache属于哪个组群
中间3位表示属于哪个组
后面9位表示偏移量,表示要找到那个数据
Eg: 地址 0000 0001 001 00000 1100
前8位表示在第一组群 中间三位(cache索引)表示cache的第一个set ,就是第一个族群的第001块,就是第九块,把这一块映射到cache的第一组当中。
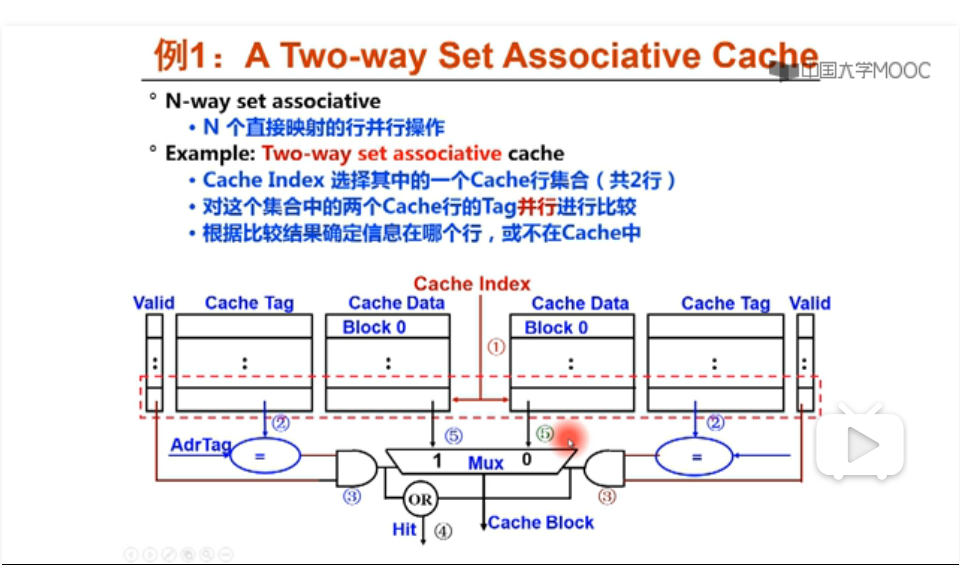
两个比较器并向同时比较,最多有一个cache的tag与主存地址的tag相同,OR选择器的结果就是hit的结果。
通过多路选择器把所要找的cache data的block找出来!


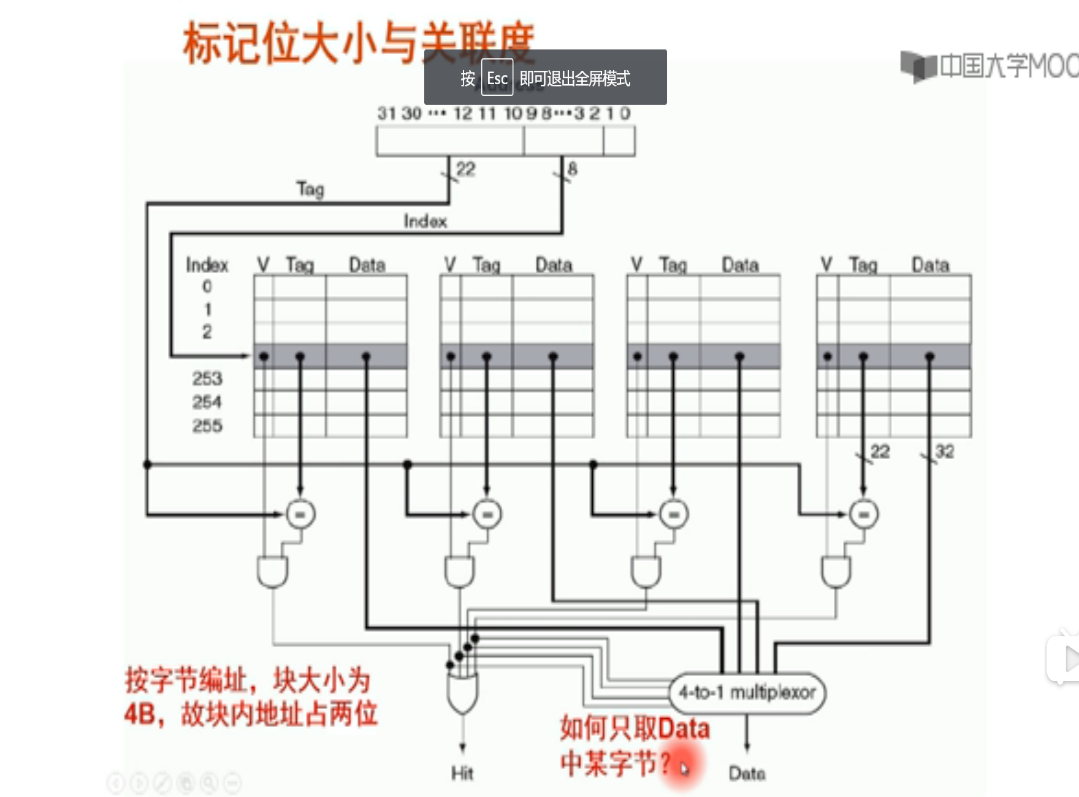
顺便讲一下什么叫按字节编址,按字编址。
字 word = 4byte
字节 byte = 8bit
位 bit




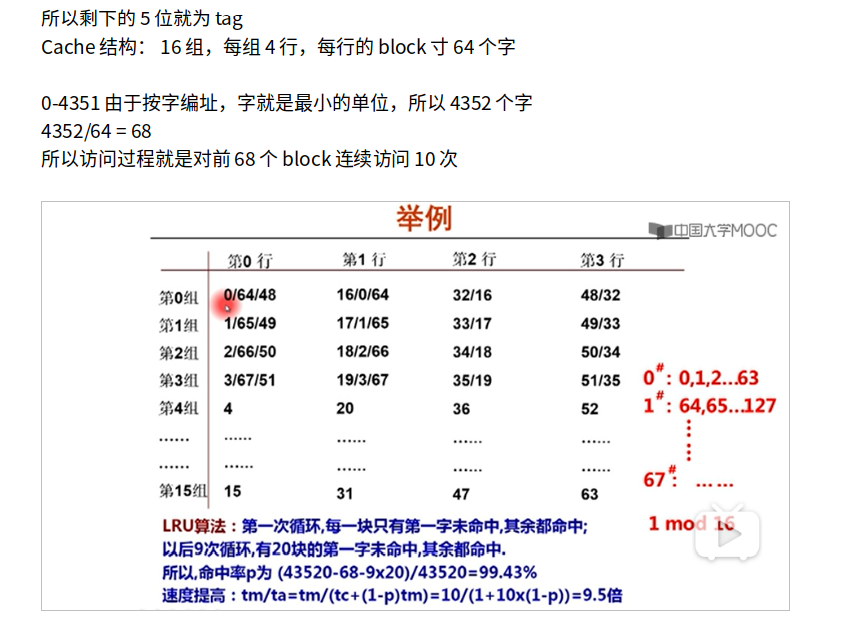
上面的图怎么看?
1. 每一block64个字。访问第0block,冷不命中,放到第0组。那哪一行呢?都可以,一般按照顺序来,因此放在第0组第0行。然后第0组所有元素就都在第0组第0行中取。
2. 然后访问第1组,冷不命中,放在第1组第0行。第0,16,32,48block都放在第0组,分别放在第0,1,2,3行。
3. 当取到第64block的时候,miss,根据LRU把第0组行第0行替换掉。一直到第67block结束第一次循环。
4. 然后来到第二次循环,想要找第0组,但是已经被刚才第64组替换掉了,而且第0block只能放在第0组,因此根据LRU,替换掉第0组第一行,一直到第四个block的时候,这时候第4block放在第4组的的第0行,没有miss。
5. 由于第16,17,18,19个block已经被替换,当访问第16,17,18,19个block的时候,根据LRU,分别吧0,1,2,3组的第二行的32,33,34,35block替换。同理,当访问32,33,34,35block的时候,又把第三行的48495051替换。同理,访问48,49,50,51的时候,又miss,又把第一行的对应64,65,66,67替换掉。
6. 所以第二次-第九次循环,每次都有5*4=20次miss
命中率: (43520-68-9*20)/43520 = 99.43%
Cache读和写的一致性问题


同时写cache和主存,但是主存要慢得多,这样写完了cache之后要等待主存。
所以可以增加一个buffer 写缓冲。
就是CPU可以把数据写到cache中。写完了之后不等写道主存,继续写cache,写到主存的工作就交给write buffer,由memory controller传回到DRAM
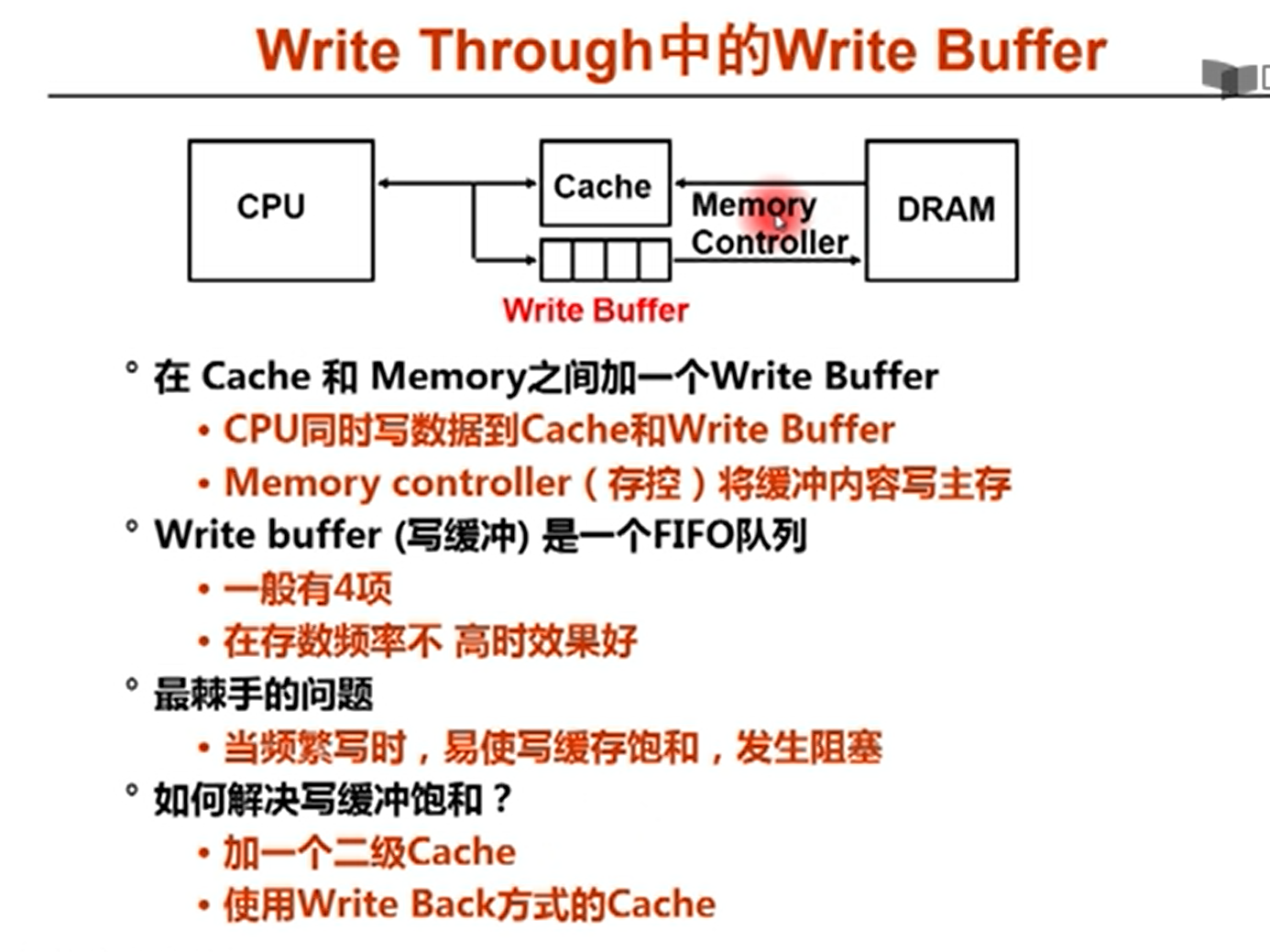


写穿透就是同时写cache和主存,写分配就是同时更新主存和cache
Write Trough 算法
如果能够找到i,使得TAG(i) == X,
如果是读操作,就直接返回块内地址DATA[i];
写操作就除了要写块内地址,还要写主存
如果miss掉
读操作就是读主存的数据,然后打标签,送到cache
写操作就是先写主存,然后打标签,最后在块内new一个新的数据
Cache越大越好,命中率越高,但是越大的话成本越高
Block 不能太大,也不能太小
Cache 数目

L1,分立cache,为了实现流水线,同时取数据和指令,提高并行性。
第二个问题:
因为他有L1,L2两个cache,即使不命中也没有关系
第三个问题:最后Level的cache与指令流无关,不需要考虑并行。因此优先考虑空间的利用率,同时命中率比命中时间更重要。
L1比L2容量小,(越大命中率越高)比L2快,命中时间短,如果L1不命中,只好寄托在L2身上,因此L2的命中率就显得特别重要。
Cache 实现举例
用2个状态位:
S: SHARE
E:EXCLUSIVE
M: MODIFIED (是否dirty bit)
VALID 是否有效
LRU用1位:
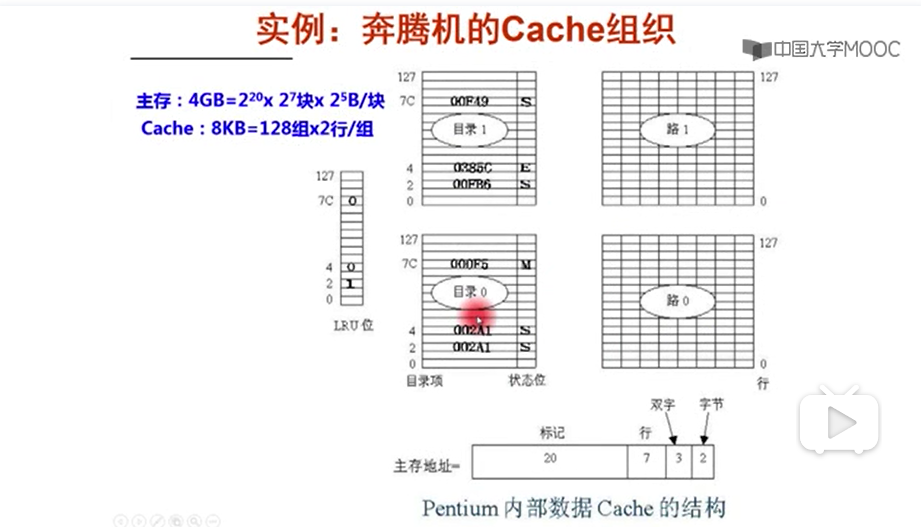
例题

1. 不考虑一致性:dirty bit ;替换控制即LRU位
256MB 表示主存地址 28位
64B – b = 6
Cache 8行 -中间索引位 3
Tag位 19位 别忘了要考虑valid位
(1+19)8 + 648*8 (每行一个block)(64B是64byte,1byte 8 bits)
2. 64B-16个元素 一行16个元素
A[0][31] 地址 320+4*31 = 444 [444/64] = 6
因此主存块号为6,6mod8 = 6因此在第六行。
或者444 为0000110111100B 中间三位是索引位,就是第六行
而A[1][1] = (320+256*4+8 )/64 mod 8=5 同理也可以把地址转化为二进制来计算。
3.A 每隔16元素一次冷不命中,命中率(15/16)
B 每次相隔256个元素,256/16 = 16 块,16mod 8=0,每次访问后面数组元素的时候,总会把上一次装入到cache中的主存块覆盖掉。
所以每次访问的时候都会发生冲突,替换,因此没有一次命中。