General Useful Optimizations
Code Motion
reduce the frequency where computation performed
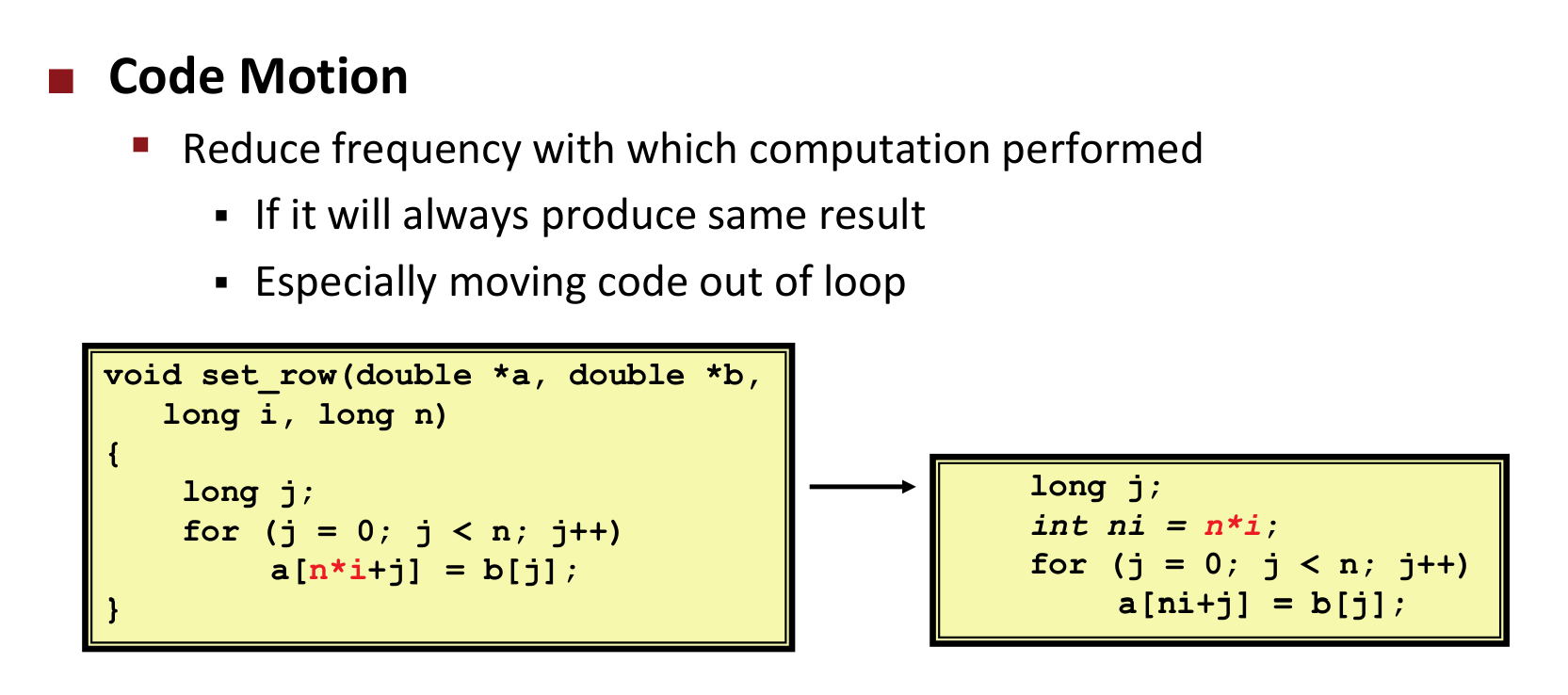
try to use shift,add to replace multiply
Reduction on strength
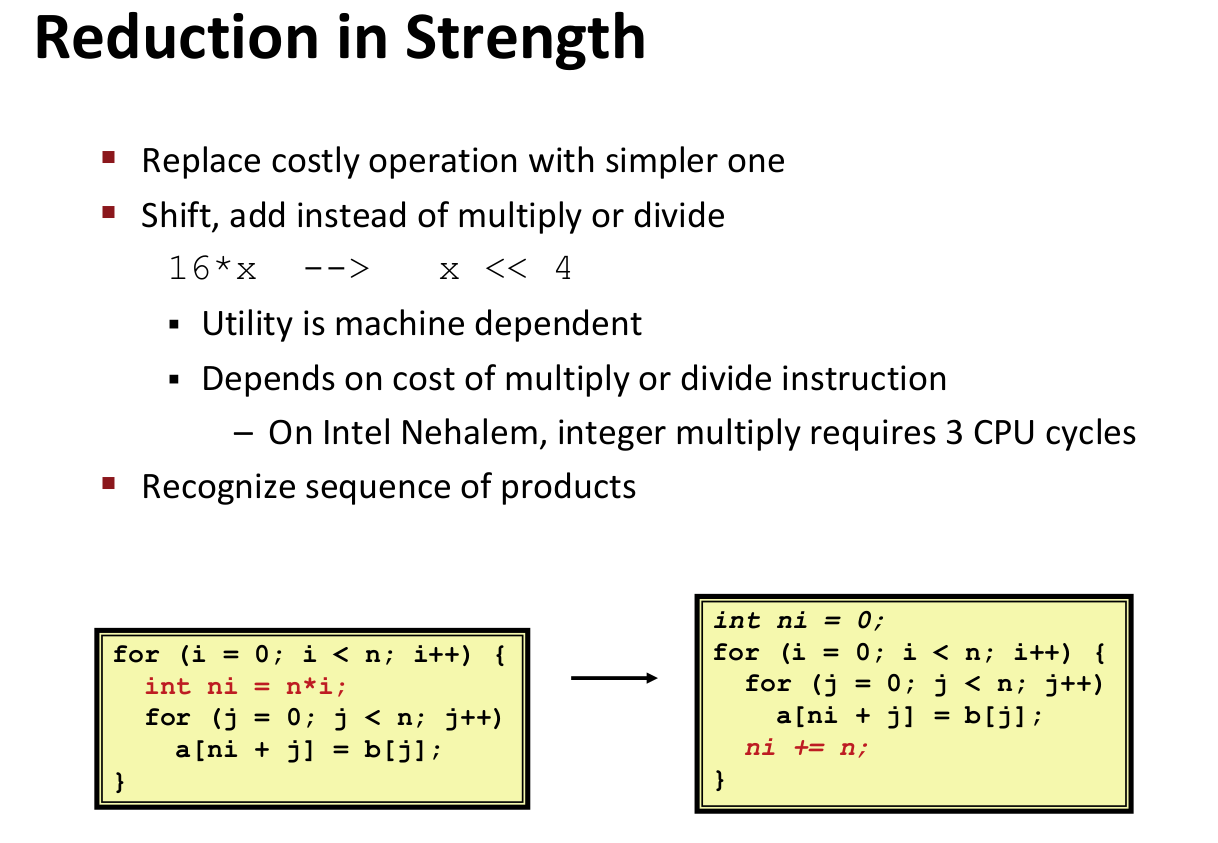
leaq (%rsi,%rcx),%rcx means %rcx = %rcx+%rsi
%rcx now is n
%rsi now is i*n+j
Share common Subexpressions

####
possibly the memory of A and B overlap and the change of B might affect A

Memory aliasing, closely related (arguably synonymous) to pointer aliasing, means that more than one variable name points to the same underlying stored value.
Benchmark Computation
Cycles Per Element(CPE)
Length = n
CPE =cycles per OP
T = CPE*n+Overhead?? what is overhead?

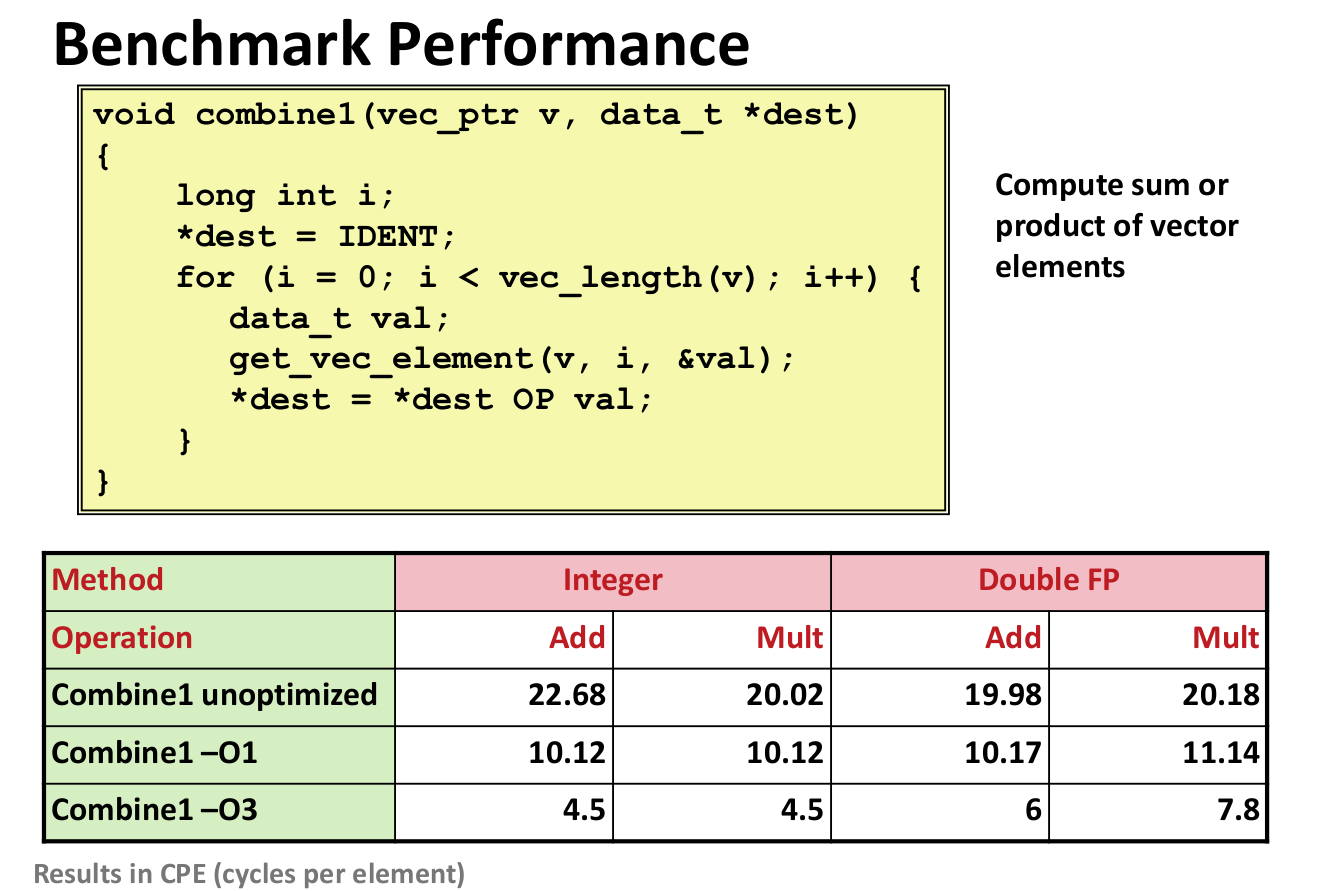
You don’t need to use get_vec in each loop,so avoid bound checking

流水线的冒险
阻止下一条指令在下一个时钟周期开始执行的情况
1.结构冒险
所需要的硬件部件正在为之前的指令工作
2.数据冒险
需要等待之前的指令来完成数据的读写
3.控制冒险
需要根据之前指令的结果决定下一步的行为
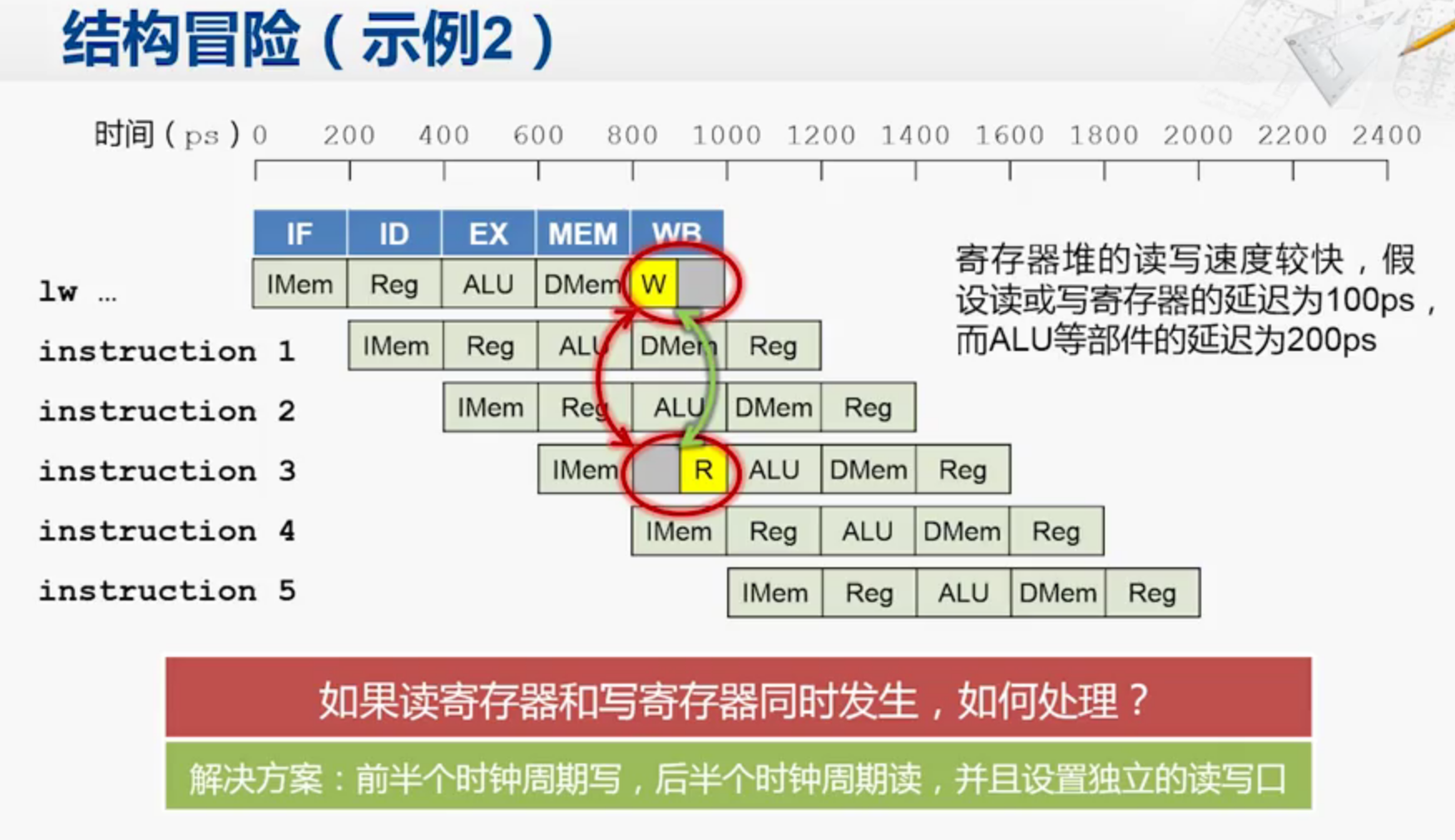
结构冒险
执行指令的硬件发生争抢

解决方案一: 冒泡停顿
但如果连续出现冒泡停顿,则会影响指令执行的效率
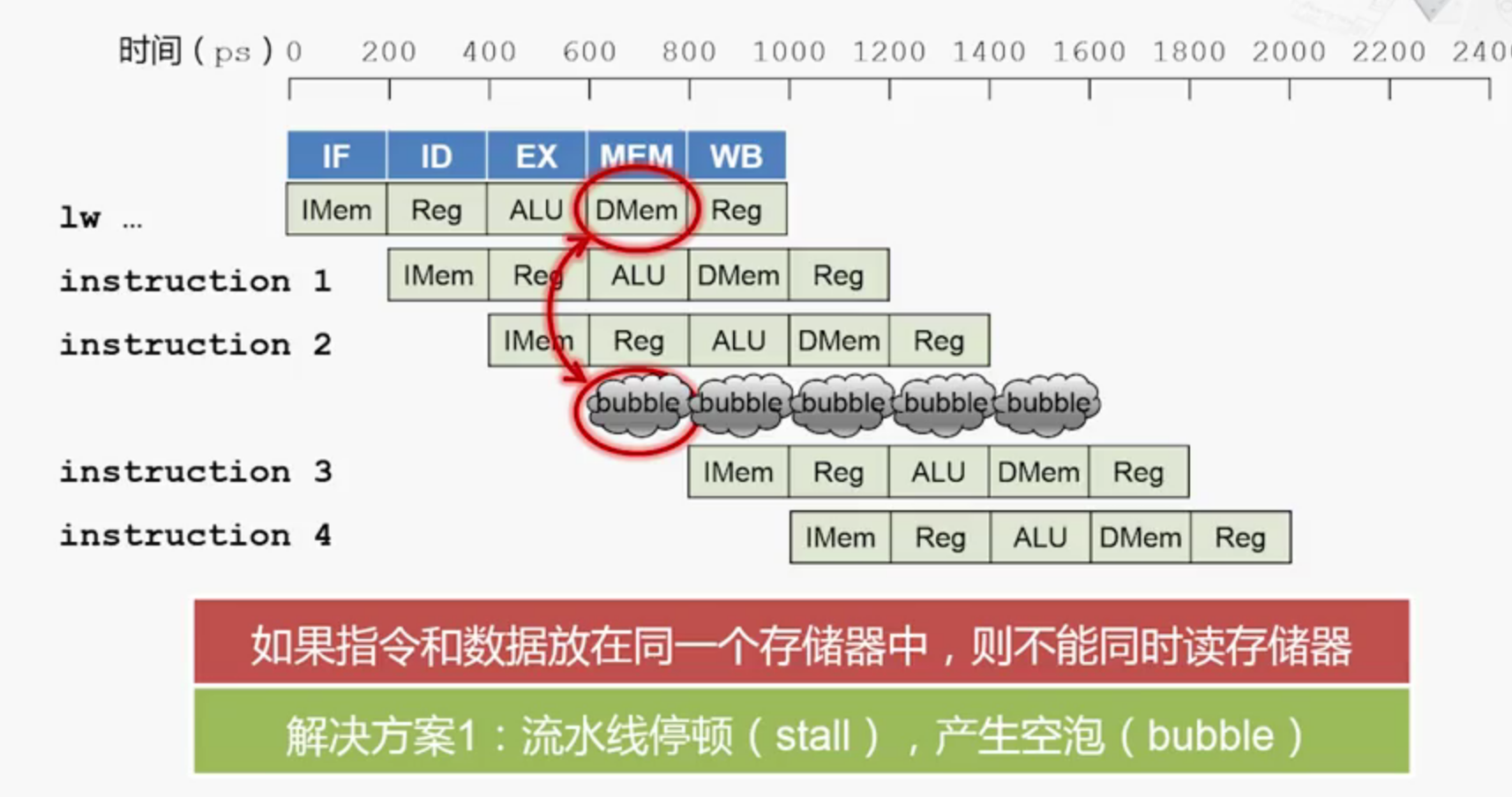
解决方案二: 把数据和指令放在不同的存储器
但值得注意的是,冯诺伊曼结构要求内存(主存储器)同时存放
数据和指令,而只是在CPU的高速缓存(cache)当中,数据和指令可以分开存放
这个在设计CPU就已经处理好了,但是如果要设计一个新的处理器,这是一个要考虑的问题
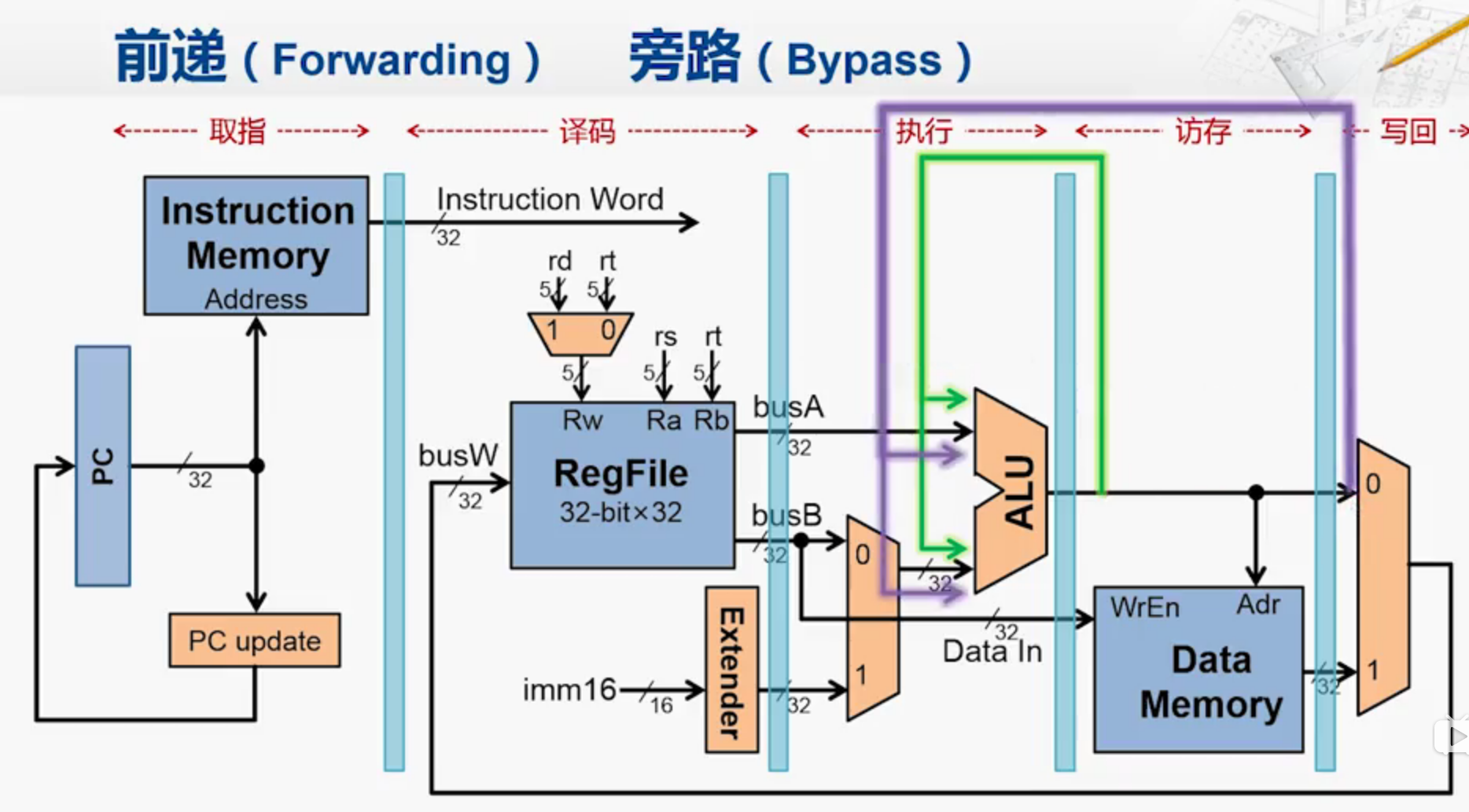
数据冒险
解决方法1: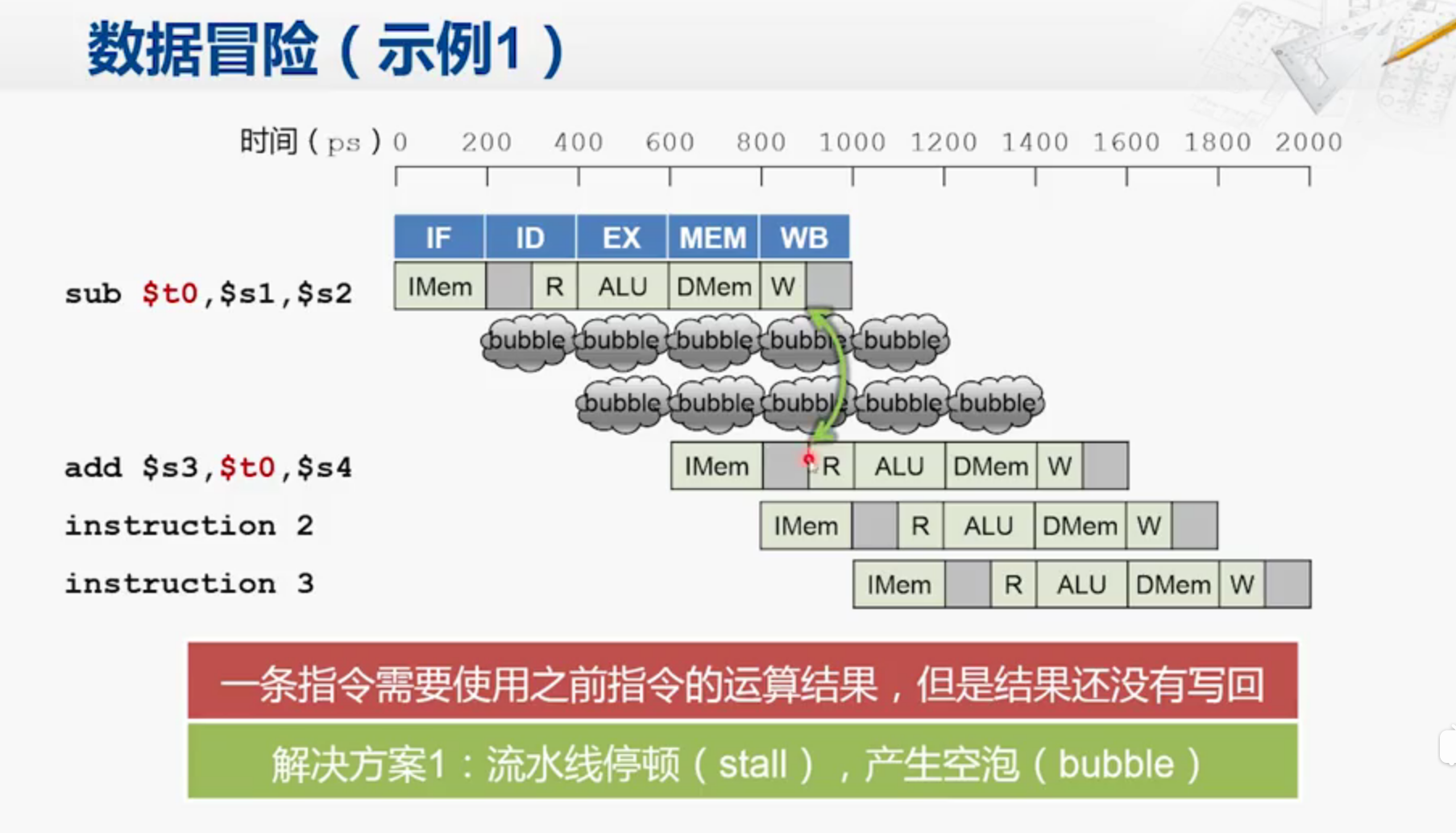
解决方法2:
冲突产生原因是add 指令 需要 read 上一条指令write的结果($t0)
但其实,$t0的值已经在ALU阶段就已经计算好,而add指令中,其实不是非得在
R阶段读$t0,只要在ALU阶段读取到数值就行。
那么就可以在sub指令中,把ALU计算得到的结果$t0送到流水线寄存器当中,
然后再送到add指令的ALU中。
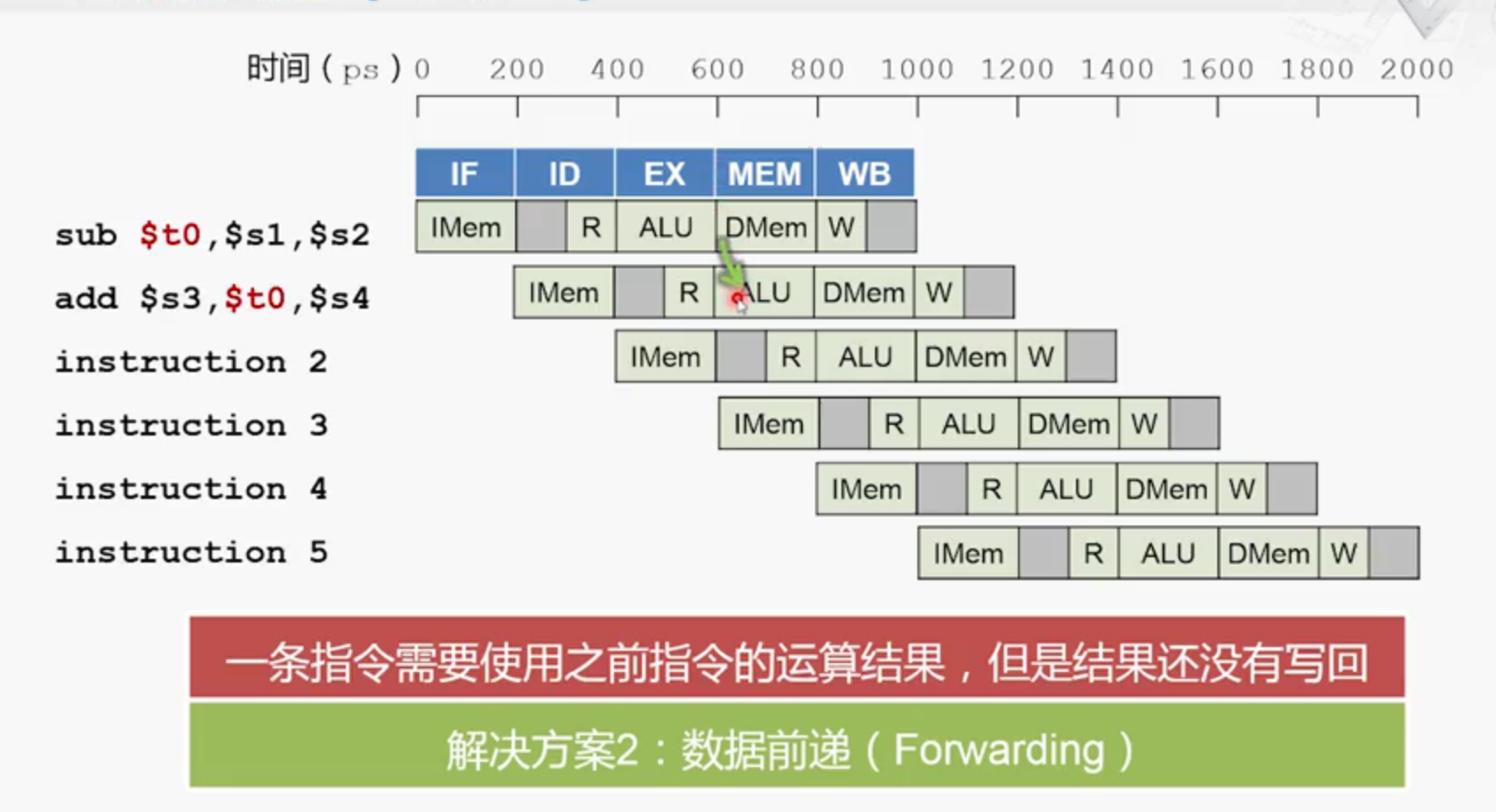
从硬件角度来看,我们要这样修改:
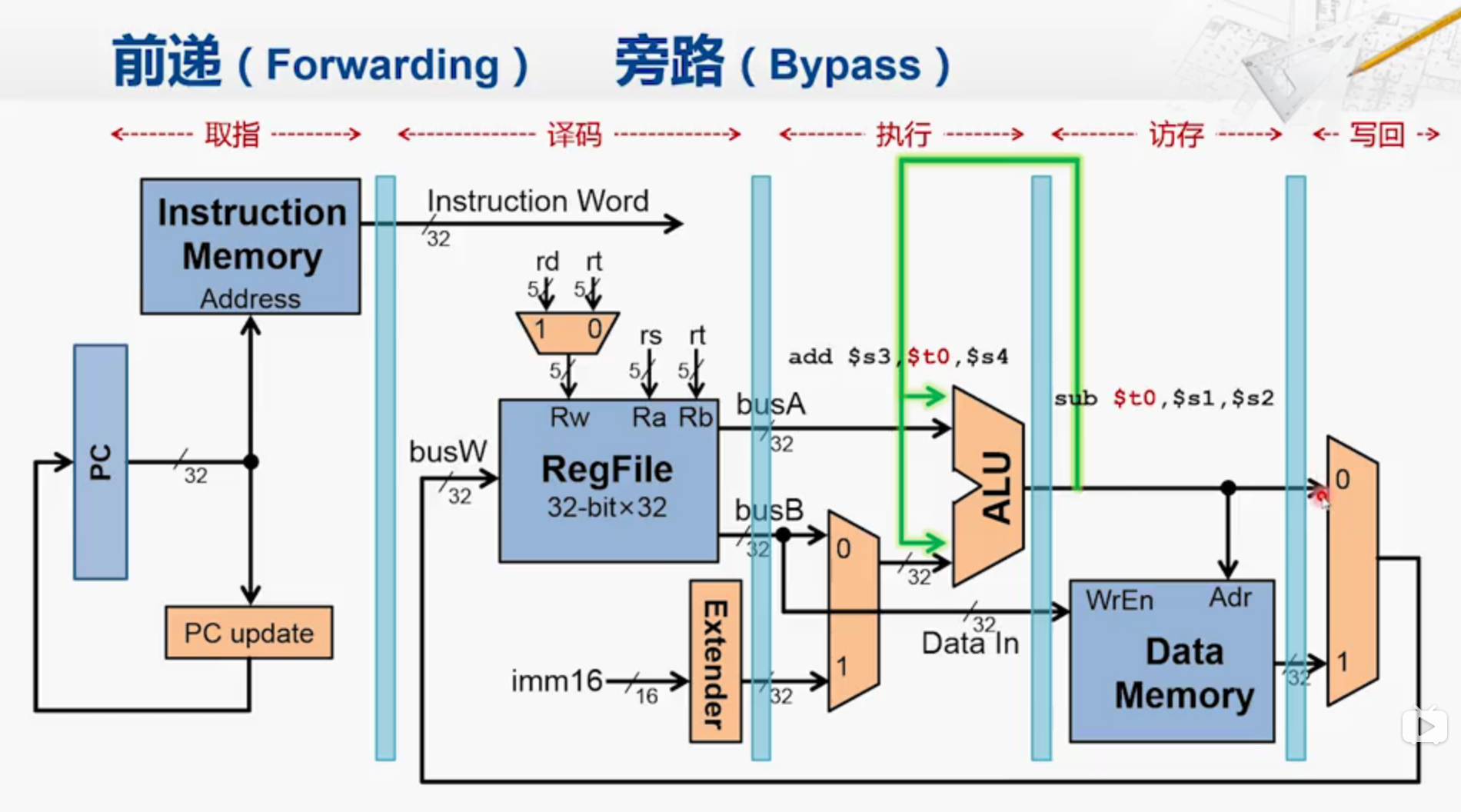
sub先执行,所以在前面,add后执行,所以在后面
add指令需要用到前一条指令的结果,因此设置了绿色的旁路,
以是否有数据冒险情况作为激活信号。
第二种情况
对应下图
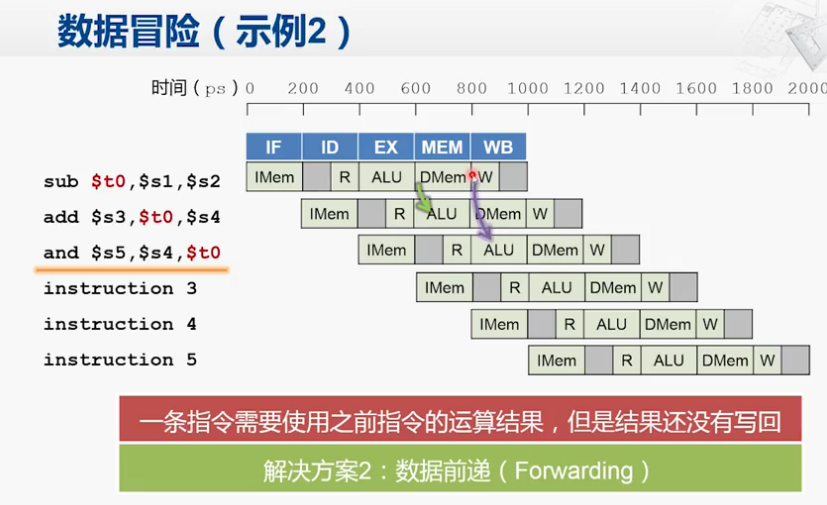
第三条指令需要用到第一条指令得到的结果,第一条的$t0在DMEM与write back阶段之间,所以呢,就是对应上上图,在访存阶段末期,通过旁路把数据传回给ALU
如果 instruction 3也需要用到$t0,因为R阶段之前,第一条指令刚好完成了write back,因此可以正常运行
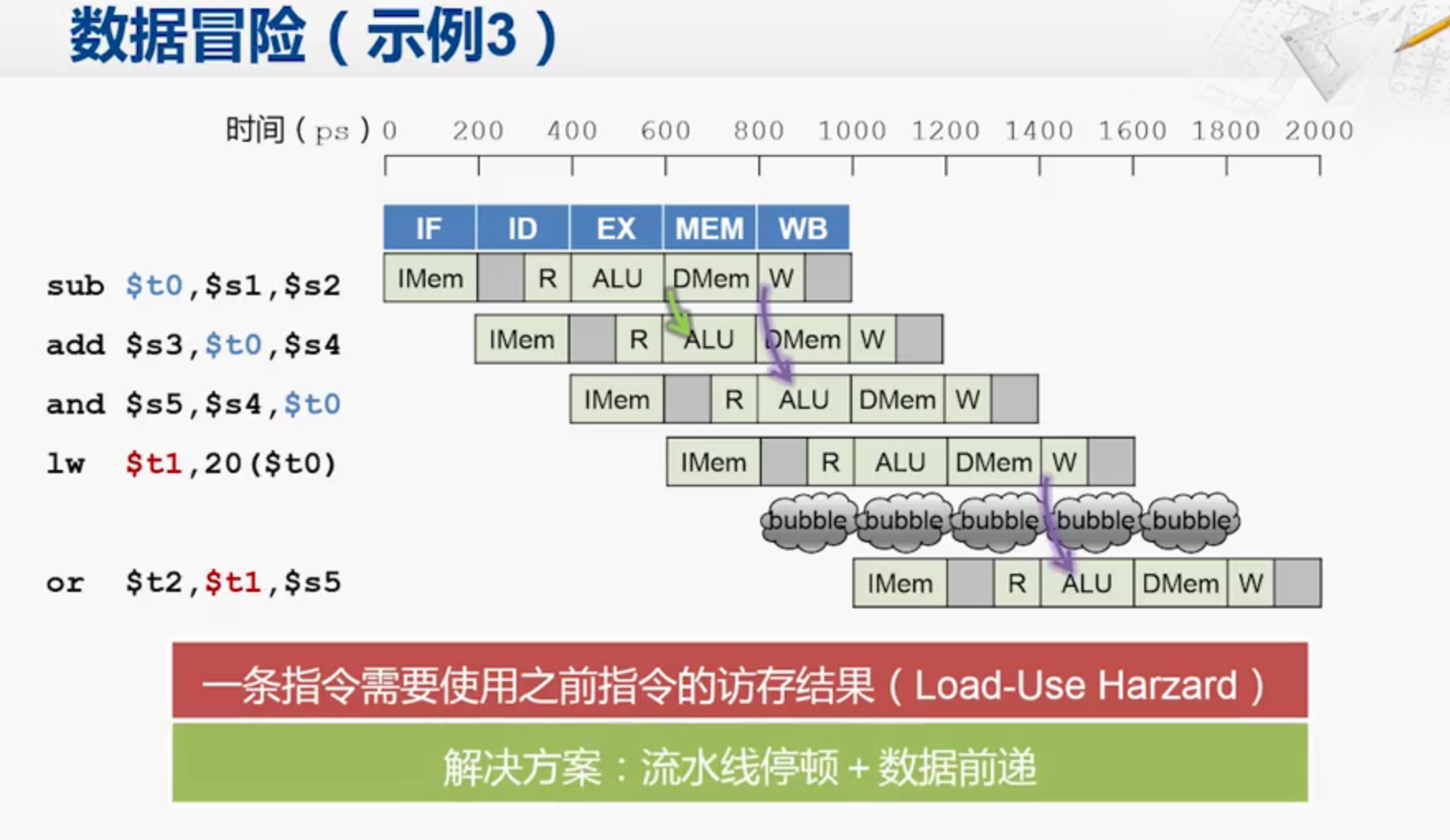
load-use冒险,不能用数据前递来解决
如下图,因为or需要用到上一条指令的$t1,但是or至少要在ALU阶段读取$t1的数值,然而lw只能在完成了访存阶段后才能把结果写回到$t1,因此只能通过冒泡来延后or指令的执行时间了。
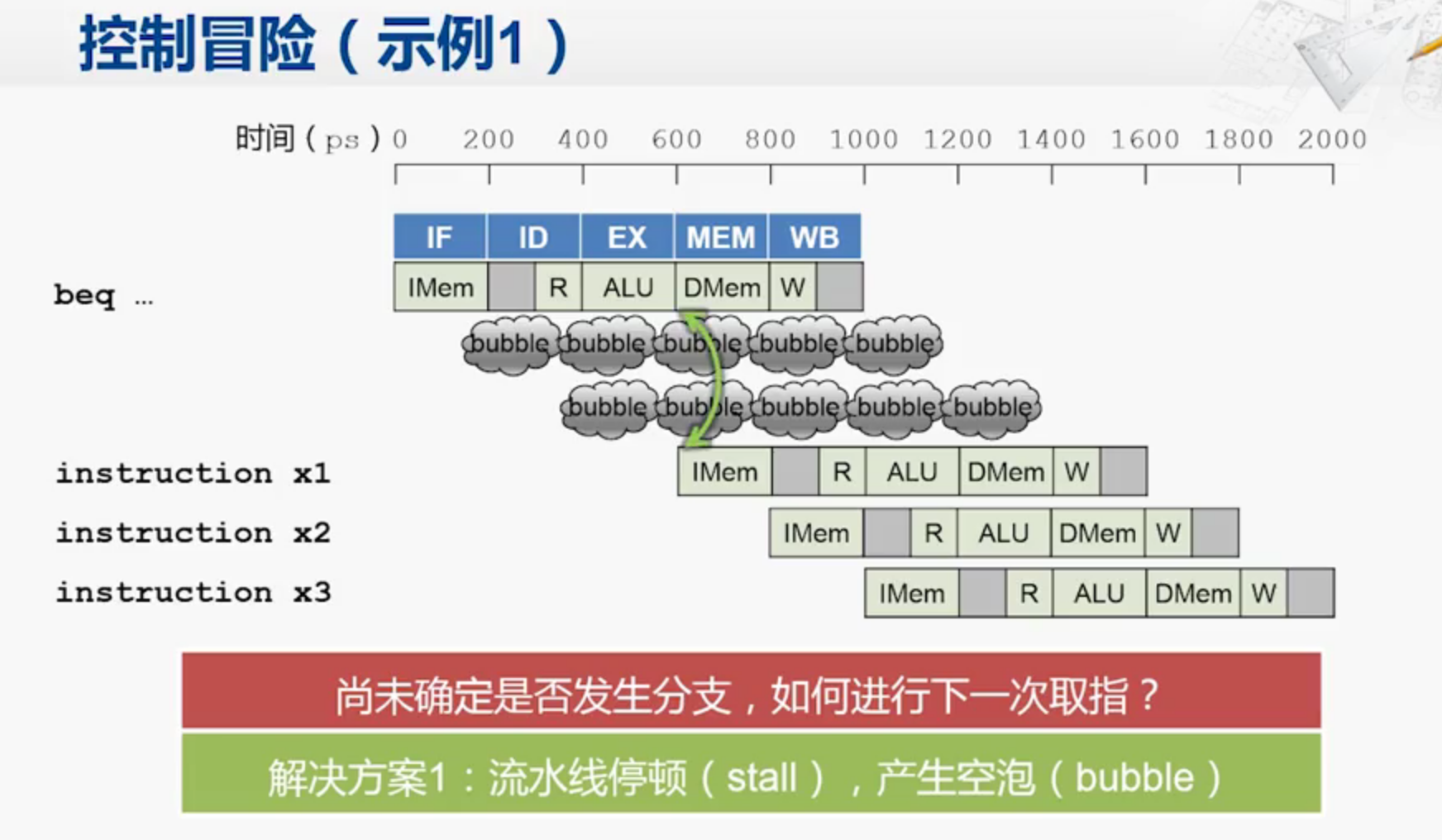
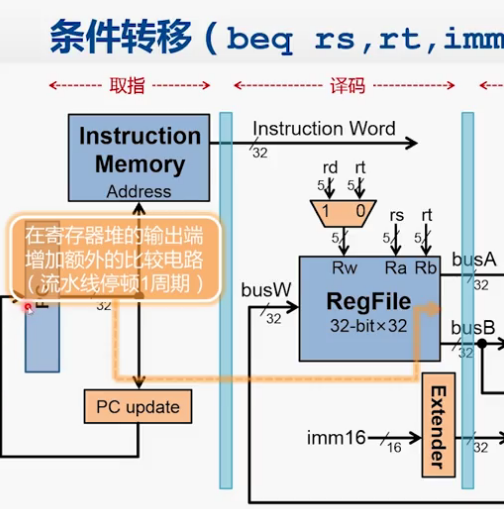
控制冒险
要到ALU阶段才能决定是否要取分支
转移指令对流水线的影响
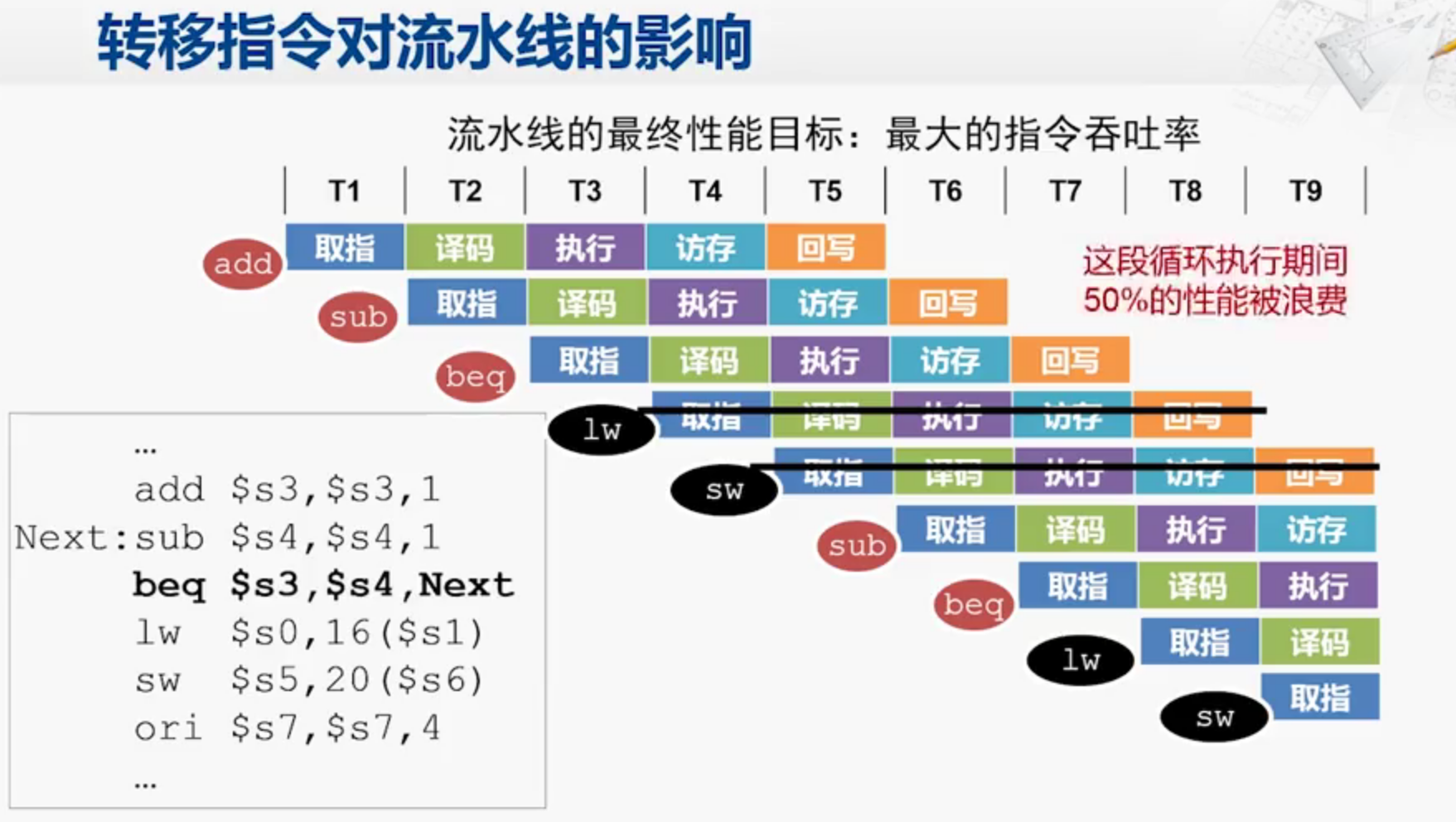
beq指令只有在进行完执行(ALU)阶段之后才能确定是否发生跳转,加入跳转条件成立,则说明lw sw是不应该取的。这时跳回sub指令,导致性能被浪费。
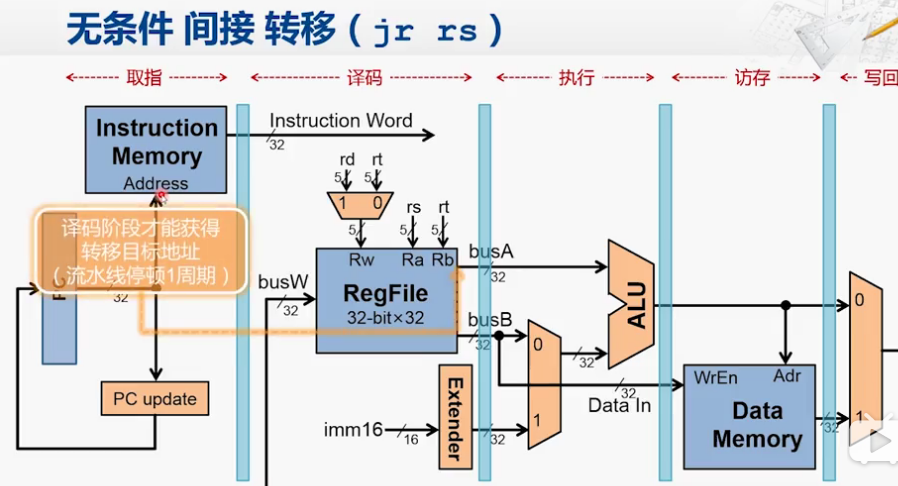
转移指令的分类

优化
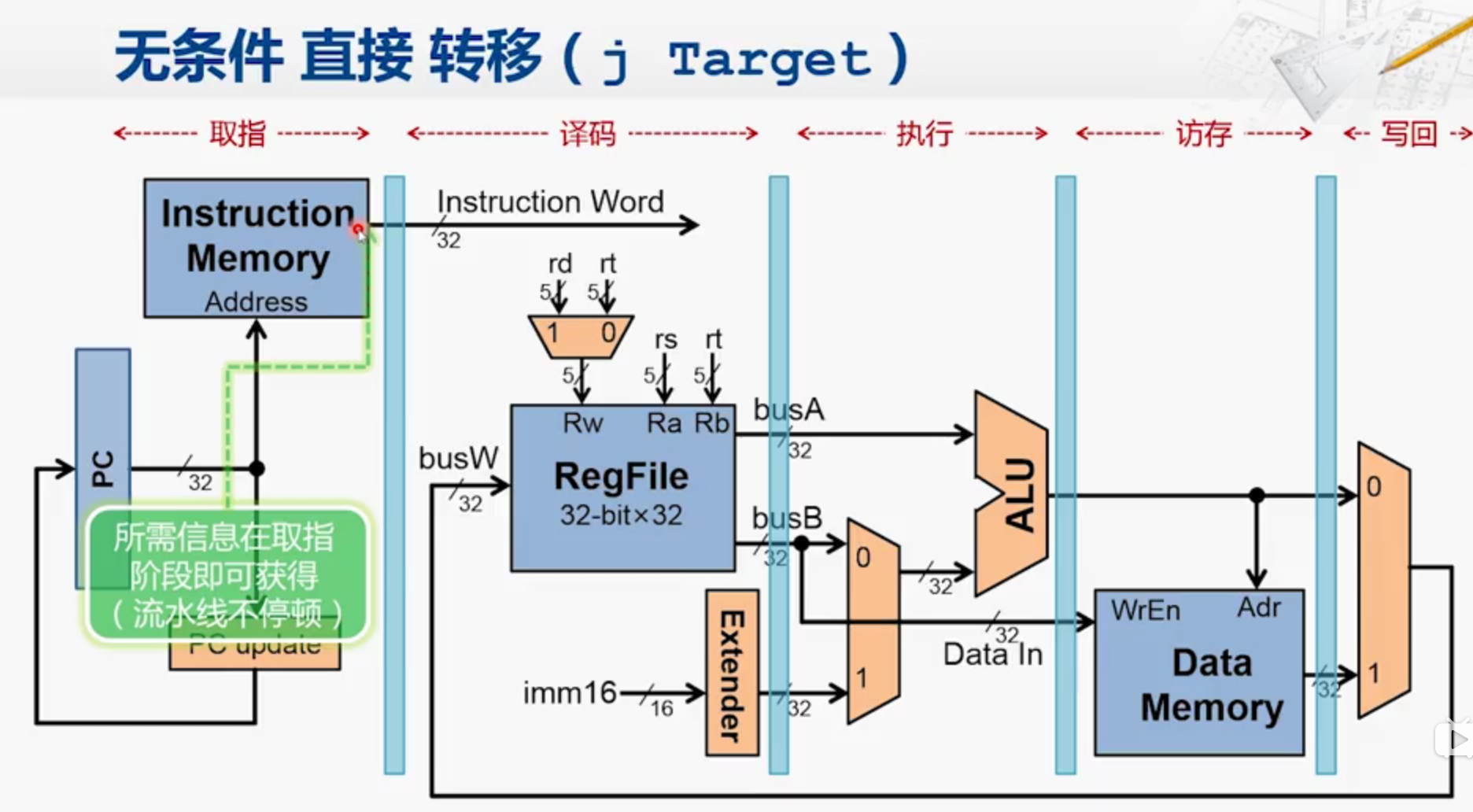
j指令在取指的时候就能判断是否为j指令,然后取出后26位,加上末两位的00,
然后在PC - update 阶段就能取PC+4的前四位,这些操作都能在一个时钟周期内完成。


译码阶段进行R【rs】,R【rt】的读取,在执行阶段进行两数的比较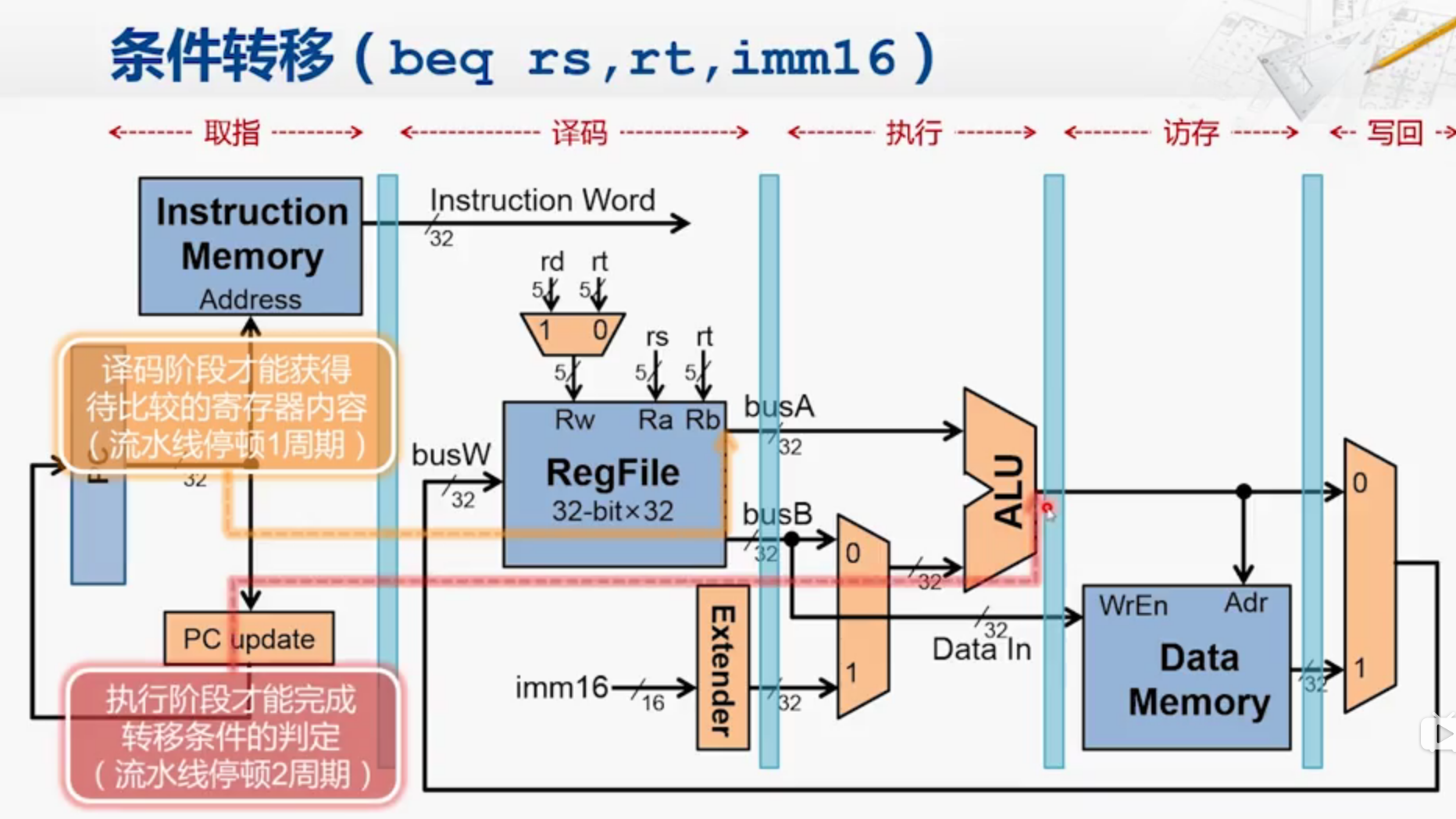
但实际上进行减法不需要ALU那么复杂的部件,可以在译码阶段进行一点小改动
总结

为了避免停顿,可以把转移指令的前一条与转移指令无关的指令(xor)移到转移指令的下一条。

Arch Lab
Part C
利用循环展开技术与加载使用冒险
加载使用冒险:
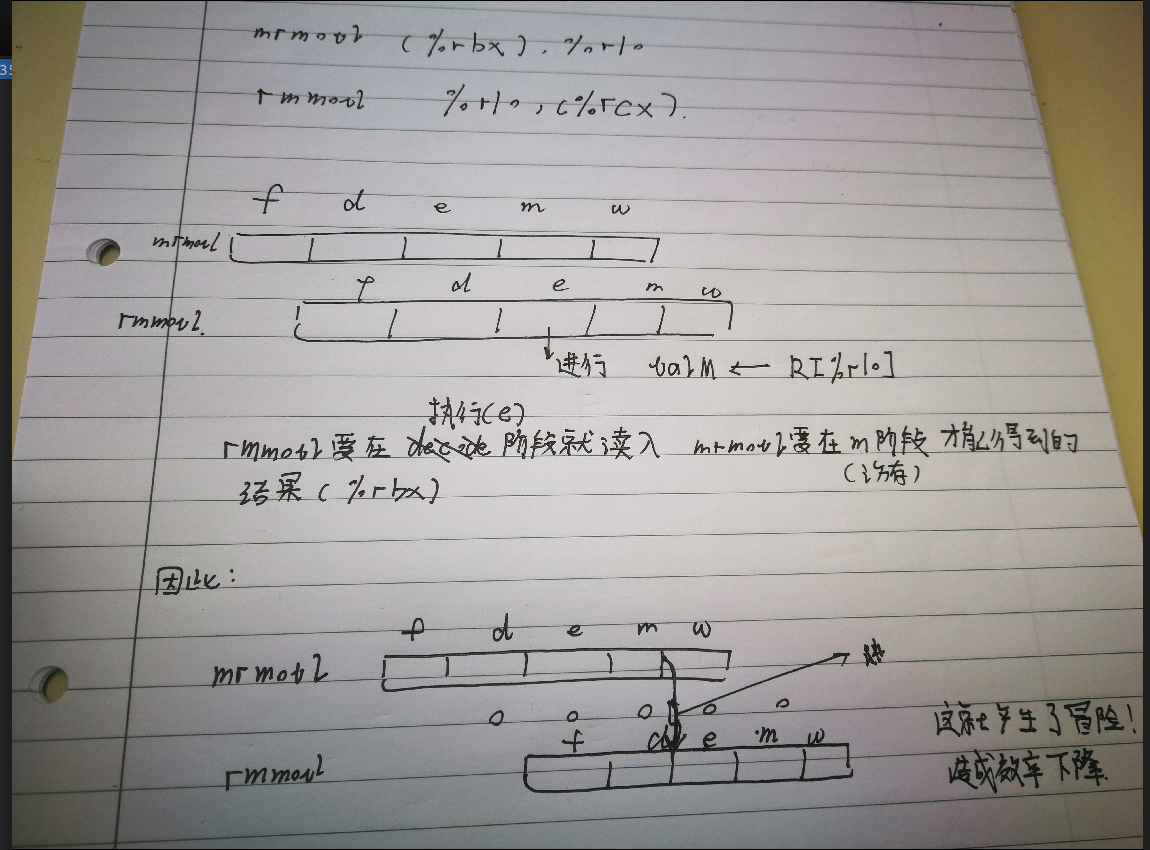
因此可以在mrmovl后添加另外一条mrmovl指令,来抵消流水线停顿,同时也使得下一次操作提前取值。
循环展开大意就是减少循环次数,在每次循环的时候同时进行多次操作。同时也可以配合并行,并行就是例如把每次累加操作的的结果分为两部分,如奇数项累加成S1,偶数项累加成S2,最后结果就是S1+S2。
1 | #You can modify this portion |