Y86 流水线的实现
PC的计算
在非流水线结构中,计算PC是在时间周期结束的时候进行的。
而在流水线实现中,计算PC作为指令执行的第一步。
Fetch 阶段
三种情况:
1.预测错误,从流水线寄存器M(M_valA)读出该指令valP的数值,即下一条指令的地址。
2.RET 指令 W_valM 从流水线寄存器读出返回地址(访存)。
3.其他情况会使用存放在流水线寄存器F中的PC的预测值。
HCL代码如下:
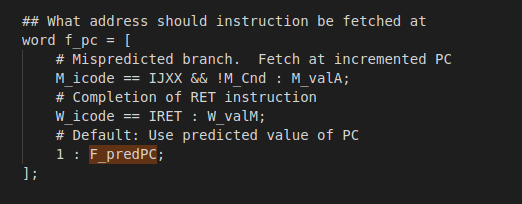
其中 f_predPC
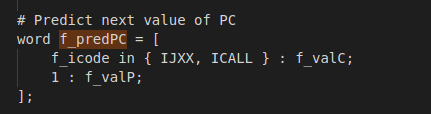
exercises:
写出 f_stat的HCL代码,提供取出指令的临时状态
word f_stat =
f_icode == IHALT : SHLT
mem_error : SADR
!instr_valid : SINS
1: SAOK
译码和写回阶段
dsrc_A
1 | word dsrc_A = |
PUSH
RRMOVQ,RMMOVQ source A的值来自于寄存器A
而push 实际上就是
subl $4,%esp
movl %ebp,(%esp)
call实际上是 push+jump,先把返回地址(此时存放在EIP中)push进%ebp,
然后再jump到要执行指令的地址
POP
而POP指令实际上是
movl (%esp),%eip //eip寄存器是保存CPU所要读取指令地址的寄存器
addl $4,%esp
return
return 实际上是 把栈顶地址弹出到EIP,然后按照EIP指示的指令地址继续执行程序
需要用到栈指针来作为source A
dsrc_B
1 |
|
dstE
1 | word d_dstE = |
dstM
1 |
|
d_valA
这五个转发源存在优先级,通常流水线的实现总是给处于最早的流水线阶段中的转发源以较高的优先级。
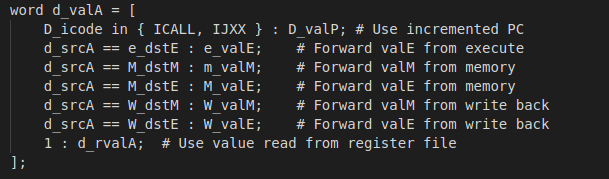
只有pop指令关心访存或者写回阶段的两个源之间的优先级
pop 指令看作是
movl (%rsp) , %rsp
addl $4,%rsp
因为默认 m_valM 访存的优先级 大于 M_valE 计算的优先级
因此加入下一条指令是
movl %rsp, %rax
则会把%rsp+4 之前的值传到%rax,满足x86的pop操作规定
aluA
1 | word aluA = [ |
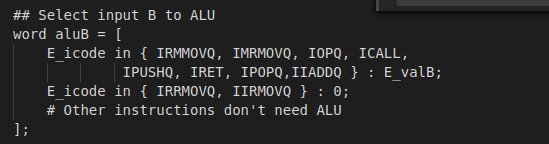
aluB