深度学习 ——Coursera
学习资源:https://github.com/Kulbear/deep-learning-coursera
官网:https://cs230-stanford.github.io/
Basic of Neural Network of Programming
Logistic Regression — Binary Classificatoin
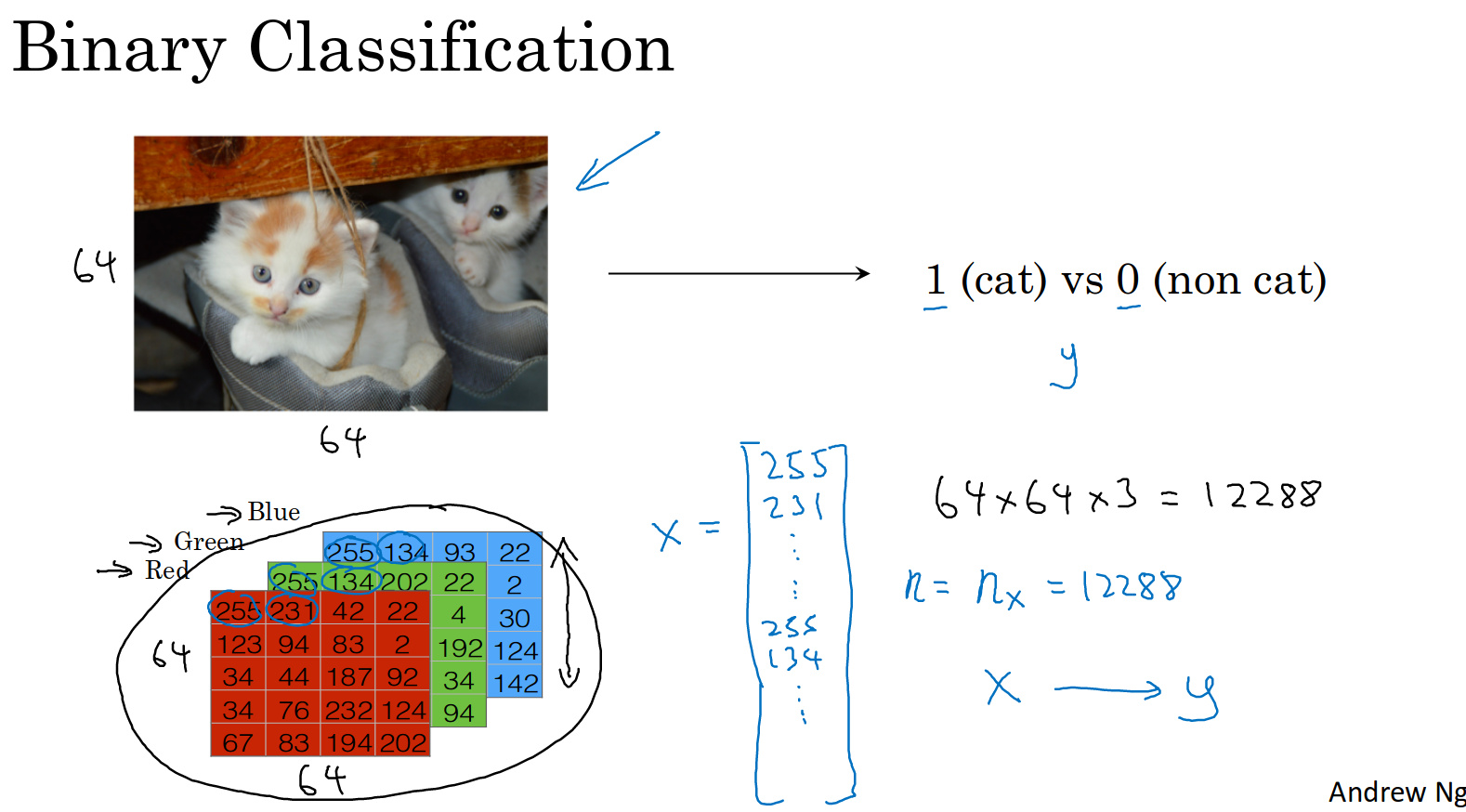
如果想把图片作为输入,判断这张图片是否为一只猫
首先得了解如何在计算机中表示图片。
图片可以表示为一个36464的矩阵,分别记录着R,G,B三个颜色通道的数值
然后定义一个向量x 让矩阵转化为一个向量,向量包含矩阵所有元素
nx表示特征向量的维度
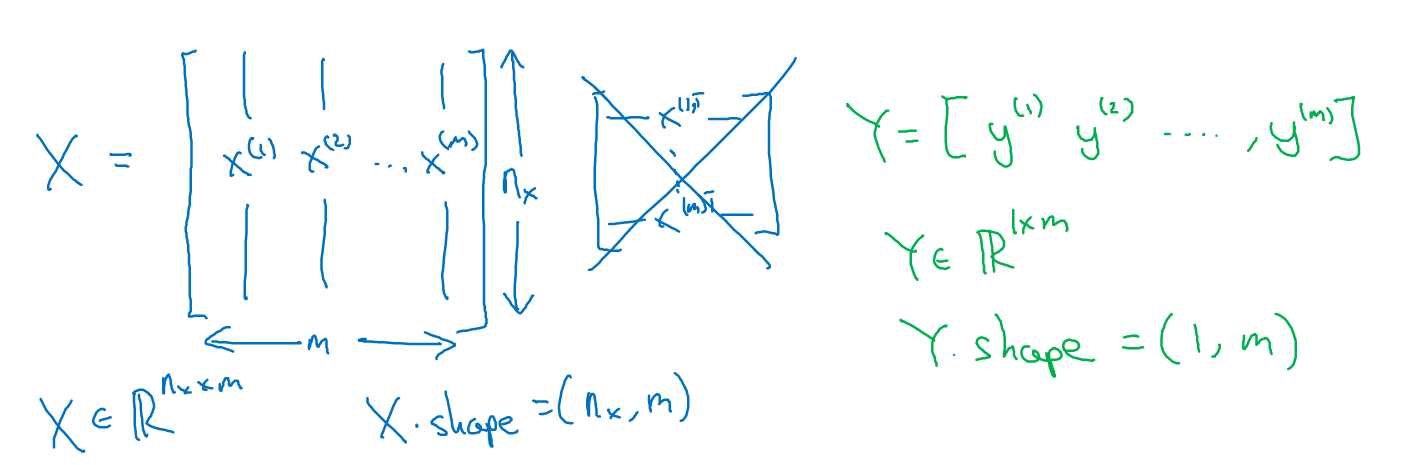
X矩阵是把向量按列排列,相应的,结果Y也是按列排列
在python中,X.shape 返回数组(nx,m)对应行数和列数,也就是向量维度为nx,个数为m
Logistic Regression
1.右上角的红色笔记不必理会
2.sigma表示sigmoid函数,是一个squashing function,即把结果压缩到0-1范围内

下一步,为了改变w与b,需要定义一个cost function
w is an nx dimenstional vector,while b is a real number.
如果cost function是半个平方误差的话,可能只会找到局部最优解
所以我们这里使用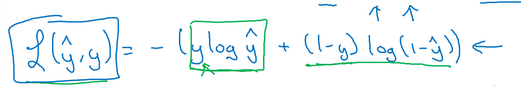

注意
不要把Loss function 和 cost function 混了!
loss function 计算的是单个训练样本的误差
而cost function 计算的是整个训练集的平均误差
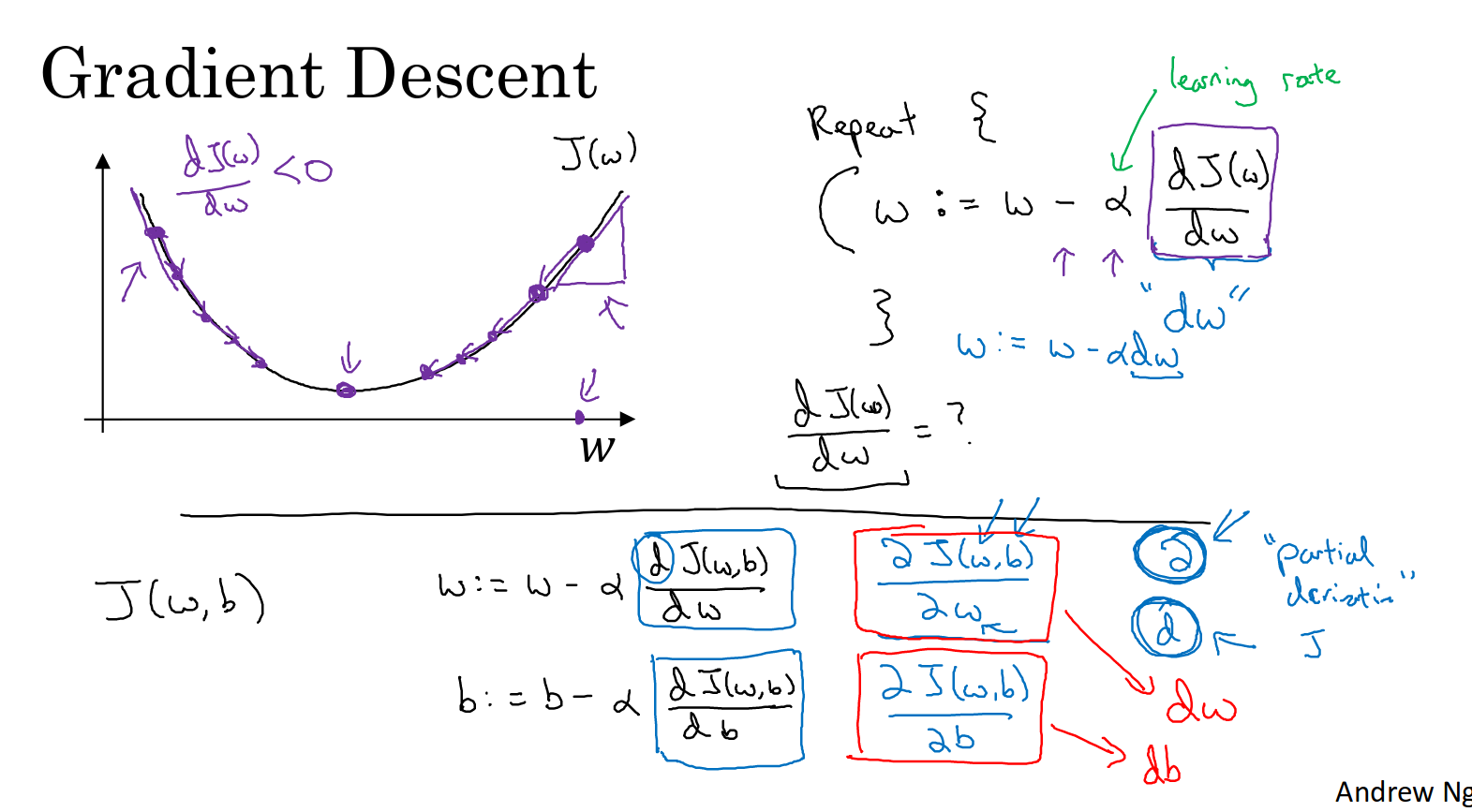
Gradient Descent
梯度下降就是我们要来寻找全局最优点的方法

1.learning rate 学习率,控制每一次迭代或者梯度下降法中步长大小
2.那为什么右上角那个repeat能保证梯度下降是make sense的呢?
d(J)/dw 代表的是斜率,试想在全局最优点左侧,梯度是负数,相当于w加上了一个正数,那么
w就会向全局最优点靠近的方向移动。反之亦然,所以通过不停迭代最后一定会达到全局最优点。
Computation Graph
1.神经网络正向传播,计算输出,反向传播用来计算导数,为什么要这样组织呢?

反向传播意思是如果你要计算dj/da 按照红色箭头来计算(把从右到左得到的结果依次运用链式法则来求)
Logistic Regression Grdient Descent on m examples

两个循环,时间复杂度是M*N M为特征向量个数 N为特征数
那如何摆脱这个循环呢?
可以使用vectorization技巧
vectorization
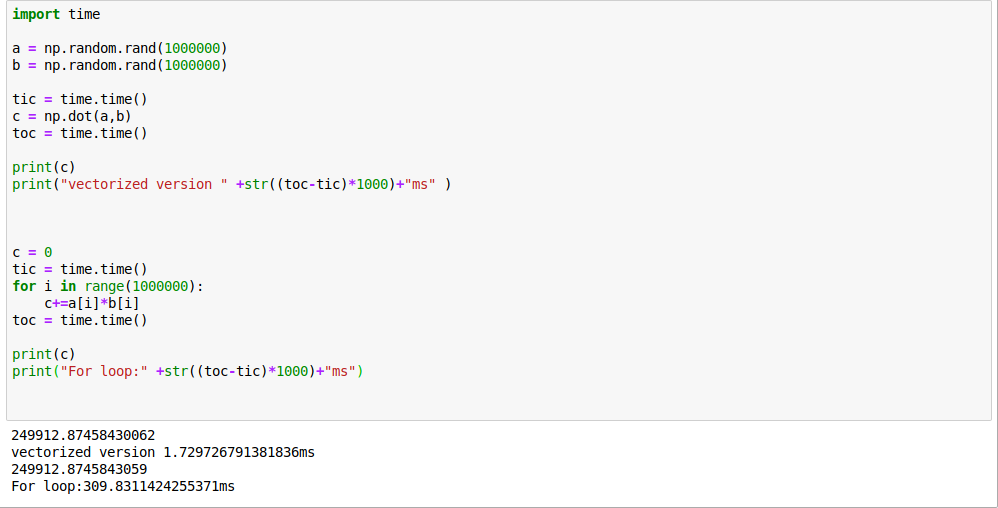
所以要使用向量化来加速代码的运行
实际上,GPU和CPU都支持并行计算,SIMD指令,当时用内置函数的时候,例如np.dot,CPU和GPU会利用并行化进行更快的运算。
因此尽量避免使用显式的for循环
例如下例:


具体我们来看逻辑回归的向量化

用z = np.dot(w.T,x)+b
就可实现移除两个for循环的功能
小知识:python中的broadcasting
意思就是虽然b是常数,但是当与一个向量相加的时候,b自动扩展为一个与向量维度相同,值全部为b的向量。
具体实现

python 的 broadcasting
(axis=0)按列相加
(axis=1)按行相加
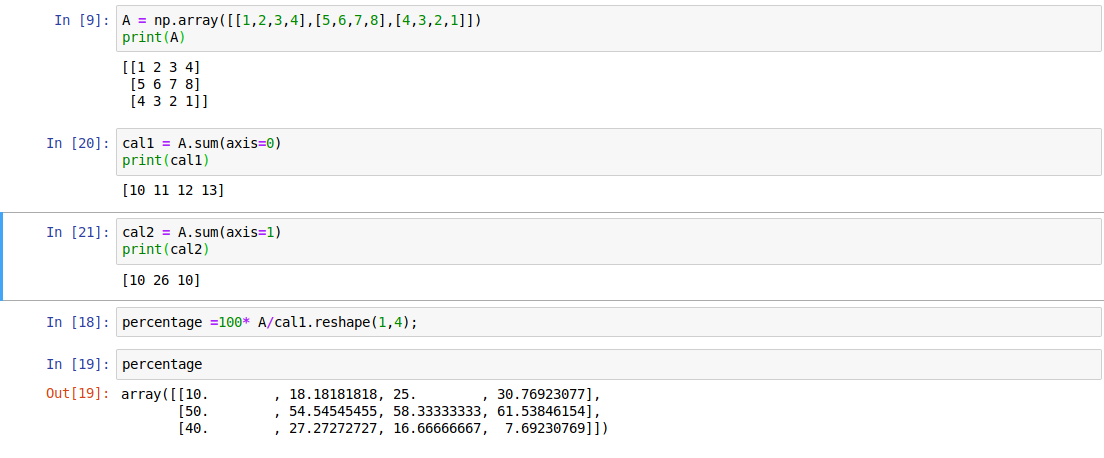
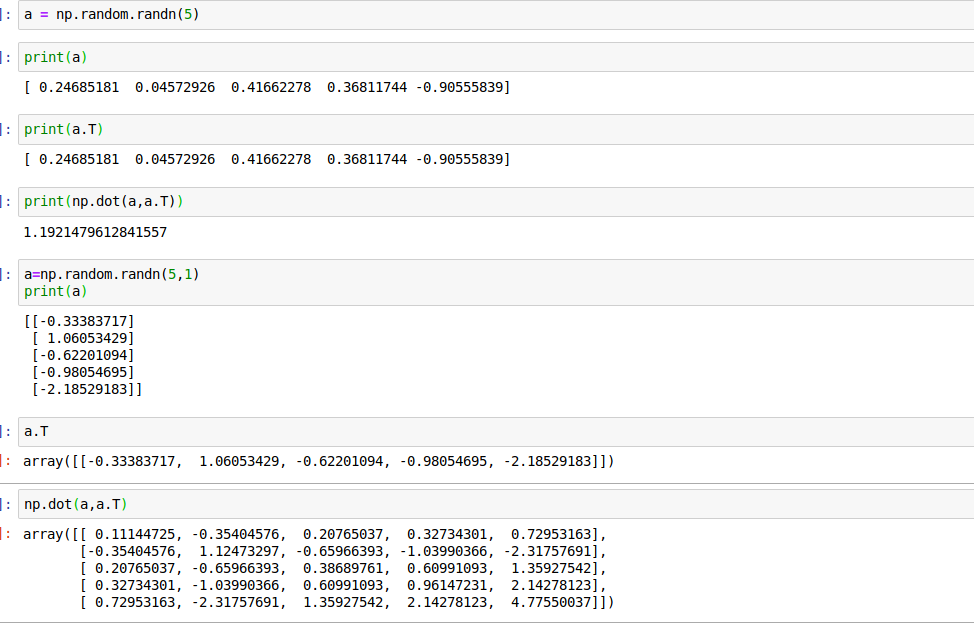
小技巧,定义vector的时候,写为下半部分的形式,不要使用np.random.randn(5)这种rank为1的结构