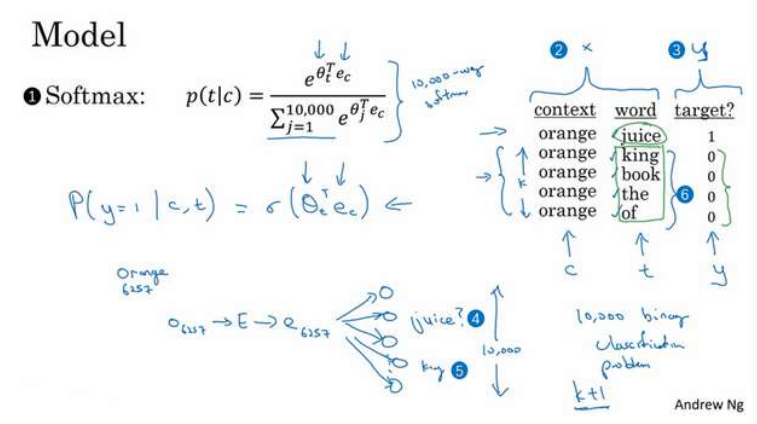
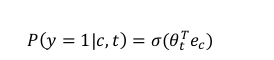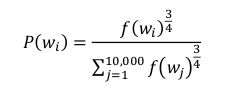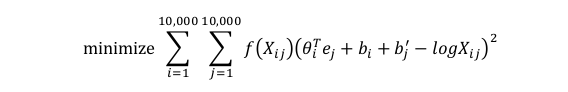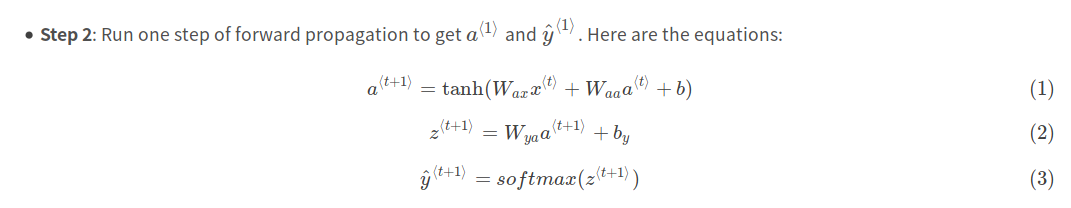SIMD
单指令多数据
向量体系结构 多媒体SIMD指令集扩展 与GPU
VMIPS
如果循环的迭代没有相关性,那么这种相关称为循环间相关。这些代码可以向量化。
向量处理器中,每个向量指令只会因为等待每个向量的第一个元素而等待一次。
向量执行时间
取决于三个要素:
1.操作数向量的长度
2.操作之间的结构冒险
3.数据相关
护航指令组:
一组可以一直执行的向量指令。
钟鸣:
度量估计护航指令组的时间
执行由m个护航指令组构成的向量序列需要m次钟鸣,向量长度为n的时候,大约为mxn个时钟周期。
向量长度寄存器
使用条带挖掘技术,把向量分割成不大于MVL大小的小向量来进行处理
1 |
|
上面这段代码表示除了第一段部分长度为VL,向量其余长度都为MVL
向量遮罩寄存器
代码向量化程度低的原因:
1.存在IF条件语句
2.稀疏矩阵
于是向量遮罩寄存器可以把条件执行IF转换为直行代码序列,方便代码进行向量化。
如果元素对应的向量遮罩寄存器对应数值为1,说明该数值不受该向量影响。
1 | LV V1,RX |
内存组
为向量载入/存储单元提供带宽
时钟周期提取或者存储一个字的初始化速率,约等于寄存器向存储器载入或者提取新字的速度,于是存储器必须能够生成或者接收那么多数据,将访问对象分散在多个独立的存储器中。
处理非连续存储器
步幅:所要收集的寄存器元素之间的距离
1 | for(int i=0;i<100;i++){ |
考虑双字,那么这里D的步幅就是100*8;
A的步幅为8
当 组数/(步幅与组数的最小公倍数)< 组繁忙时间
例如 八个存储器组,组繁忙时间为6个时钟周期,总存储器延迟为12个时钟周期,以步幅1完成一个64元素的向量载入操作,需要时间?如果步幅32呢?
第一种情况:步幅为1
12+64 = 76 周期
第二种情况: 步幅为32
8 / gcd(32,8) = 1 < 6
12 + 1 + 63 * 6 = 391
第一次访问之后,对存储器的每次访问会和上一次访问发生冲突。
集中——分散:在向量体系结构中处理稀疏矩阵
GPU中所有载入操作都是集中,所有存储都是分散。
采用索引向量的集中——分散操作。VMIPS指令:LVI,SVI
图形处理器 GPU
CUDA(COMPUTE UNIFIED DEVICE ARCHITECTURE)
CUDA为系统处理器生成C/C++,为GPU生成C和C++方言。
编译器和硬件把许多CUDA线程聚合在一起,利用CPU各种并行类型:多线程,SIMD和指令级并行。这些线程被分块,执行的时候以32个线程为1组,称为线程块。执行整个线程的硬件为多线程SIMD处理器。
CUDA编程模型是一个异构模型,需要CPU与GPU协同工作。
host 指CPU以及内存
device 指GPU及其内存
host与device之间进行通信,可以进行数据拷贝。
cuda程序执行流程:
1.分配host内存,进行数据初始化
2.分配device内存,然后host把数据拷贝到device上
3.调用cuda的核函数在device上完成指定运算
4.把device运算结果拷贝到host上
5.释放device和host上分配内存。
kernel 是device上线程并行执行的函数,核函数用global 符号声明,调用的时候要用<<grid,block>>来指定kernel要执行的线程数量。
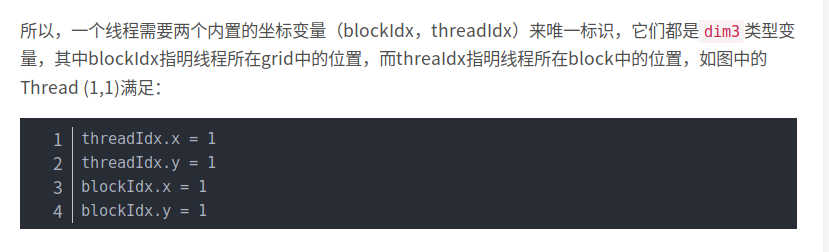
cuda中每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,ID可以通过核函数的内置变量threadIdx来获得。
GPU异构模型,需要用函数限定词来区分host与device上的代码
1 | __global__ |
GPU上有很多并行化的轻量级线程,kernel在device上执行的时候启动很多线程。
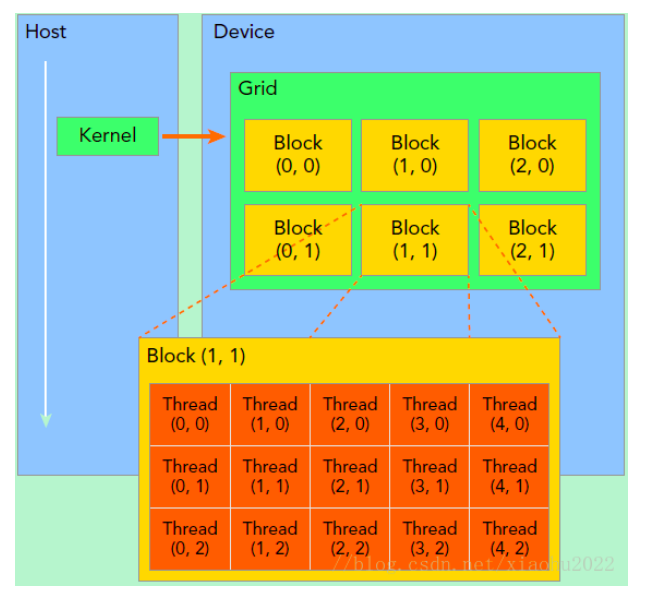
一个kernel启动的所有线程成为一个网格(grid)同一个网格的线程共享相同的全局内存空间。
grid是线程结构的第一层次,而一个grid又可以分为很多block(线程块)
一个线程块包含很多线程。
1 | dim3 grid(3,2); |
用nvcc编译,文件名为xxx.cu
1 | #include <stdio.h> |
但是上面的例子中,没有使用托管内存,其可以共同管理host与device中的内存,自动在host与device中进行数据传输。
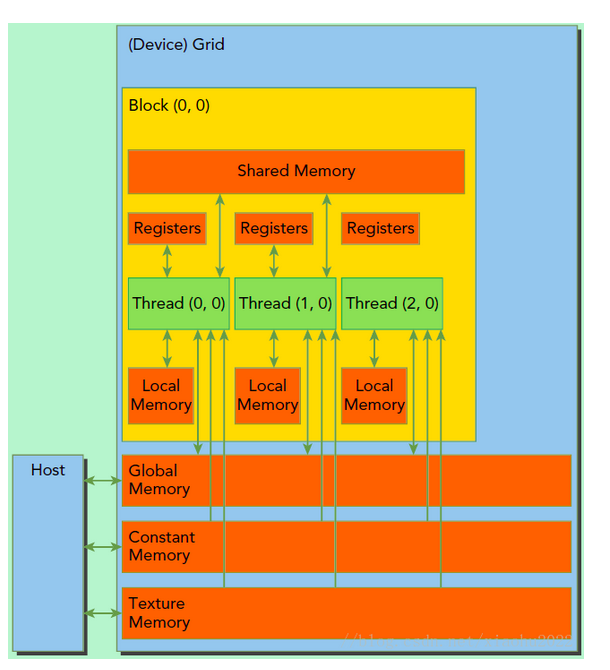
所有线程可以访问全局内存,每个线程块有local memory,而且还有包含共享内存,可以被线程块中所有线程共享,生命周期与线程块一致。
grid之间通过global memory交换数据
block之间不能相互通信,只能通过global memory共享数据
即线程之间可以通过同步通信。
矩阵乘法实例:
1 | #include <iostream> |